 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Gets Activated: Uncovering Domain and Driver Experts in MoE Language Models
Jan 15, 2026Most interpretability work focuses on layer- or neuron-level mechanisms in Transformers, leaving expert-level behavior in MoE LLMs underexplored. Motivated by functional specialization in the human brain, we analyze expert activation by distinguishing domain and driver experts. In this work, we study expert activation in MoE models across three public domains and address two key questions: (1) which experts are activated, and whether certain expert types exhibit consistent activation patterns; and (2) how tokens are associated with and trigger the activation of specific experts. To answer these questions, we introduce entropy-based and causal-effect metrics to assess whether an expert is strongly favored for a particular domain, and how strongly expert activation contributes causally to the model's output, thus identify domain and driver experts, respectively. Furthermore, we explore how individual tokens are associated with the activation of specific experts. Our analysis reveals that (1) Among the activated experts, some show clear domain preferences, while others exert strong causal influence on model performance, underscoring their decisive roles. (2) tokens occurring earlier in a sentence are more likely to trigger the driver experts, and (3) adjusting the weights of domain and driver experts leads to significant performance gains across all three models and domains. These findings shed light on the internal mechanisms of MoE models and enhance their interpretability.
Debiasing Multilingual LLMs in Cross-lingual Latent Space
Aug 25, 2025Debiasing techniques such as SentDebias aim to reduce bias in large language models (LLMs). Previous studies have evaluated their cross-lingual transferability by directly applying these methods to LLM representations, revealing their limited effectiveness across languages. In this work, we therefore propose to perform debiasing in a joint latent space rather than directly on LLM representations. We construct a well-aligned cross-lingual latent space using an autoencoder trained on parallel TED talk scripts. Our experiments with Aya-expanse and two debiasing techniques across four languages (English, French, German, Dutch) demonstrate that a) autoencoders effectively construct a well-aligned cross-lingual latent space, and b) applying debiasing techniques in the learned cross-lingual latent space significantly improves both the overall debiasing performance and cross-lingual transferability.
Understanding Subword Compositionality of Large Language Models
Aug 25, 2025Large language models (LLMs) take sequences of subwords as input, requiring them to effective compose subword representations into meaningful word-level representations. In this paper, we present a comprehensive set of experiments to probe how LLMs compose subword information, focusing on three key aspects: structural similarity, semantic decomposability, and form retention. Our analysis of the experiments suggests that these five LLM families can be classified into three distinct groups, likely reflecting difference in their underlying composition strategies. Specifically, we observe (i) three distinct patterns in the evolution of structural similarity between subword compositions and whole-word representations across layers; (ii) great performance when probing layer by layer their sensitivity to semantic decompositionality; and (iii) three distinct patterns when probing sensitivity to formal features, e.g., character sequence length. These findings provide valuable insights into the compositional dynamics of LLMs and highlight different compositional pattens in how LLMs encode and integrate subword information.
SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval
May 15, 2025The rapid spread of online disinformation presents a global challenge, and machine learning has been widely explored as a potential solution. However, multilingual settings and low-resource languages are often neglected in this field. To address this gap, we conducted a shared task on multilingual claim retrieval at SemEval 2025, aimed at identifying fact-checked claims that match newly encountered claims expressed in social media posts across different languages. The task includes two subtracks: (1) a monolingual track, where social posts and claims are in the same language, and (2) a crosslingual track, where social posts and claims might be in different languages. A total of 179 participants registered for the task contributing to 52 test submissions. 23 out of 31 teams have submitted their system papers. In this paper, we report the best-performing systems as well as the most common and the most effective approaches across both subtracks. This shared task, along with its dataset and participating systems, provides valuable insights into multilingual claim retrieval and automated fact-checking, supporting future research in this field.
Concept Space Alignment in Multilingual LLMs
Oct 01, 2024


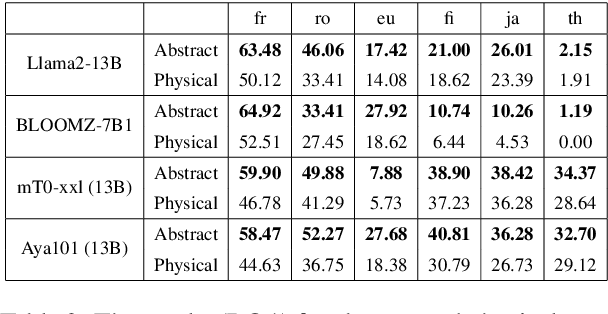
Multilingual large language models (LLMs) seem to generalize somewhat across languages. We hypothesize this is a result of implicit vector space alignment. Evaluating such alignment, we see that larger models exhibit very high-quality linear alignments between corresponding concepts in different languages. Our experiments show that multilingual LLMs suffer from two familiar weaknesses: generalization works best for languages with similar typology, and for abstract concepts. For some models, e.g., the Llama-2 family of models, prompt-based embeddings align better than word embeddings, but the projections are less linear -- an observation that holds across almost all model families, indicating that some of the implicitly learned alignments are broken somewhat by prompt-based methods.
Tokenization Falling Short: The Curse of Tokenization
Jun 17, 2024Language models typically tokenize raw text into sequences of subword identifiers from a predefined vocabulary, a process inherently sensitive to typographical errors, length variations, and largely oblivious to the internal structure of tokens-issues we term the curse of tokenization. In this study, we delve into these drawbacks and demonstrate that large language models (LLMs) remain susceptible to these problems. This study systematically investigates these challenges and their impact on LLMs through three critical research questions: (1) complex problem solving, (2) token structure probing, and (3) resilience to typographical variation. Our findings reveal that scaling model parameters can mitigate the issue of tokenization; however, LLMs still suffer from biases induced by typos and other text format variations. Our experiments show that subword regularization such as BPE-dropout can mitigate this issue. We will release our code and data to facilitate further research.
FoodieQA: A Multimodal Dataset for Fine-Grained Understanding of Chinese Food Culture
Jun 16, 2024



Food is a rich and varied dimension of cultural heritage, crucial to both individuals and social groups. To bridge the gap in the literature on the often-overlooked regional diversity in this domain, we introduce FoodieQA, a manually curated, fine-grained image-text dataset capturing the intricate features of food cultures across various regions in China. We evaluate vision-language Models (VLMs) and large language models (LLMs) on newly collected, unseen food images and corresponding questions. FoodieQA comprises three multiple-choice question-answering tasks where models need to answer questions based on multiple images, a single image, and text-only descriptions, respectively. While LLMs excel at text-based question answering, surpassing human accuracy, the open-sourced VLMs still fall short by 41\% on multi-image and 21\% on single-image VQA tasks, although closed-weights models perform closer to human levels (within 10\%). Our findings highlight that understanding food and its cultural implications remains a challenging and under-explored direction.
HumanEval-XL: A Multilingual Code Generation Benchmark for Cross-lingual Natural Language Generalization
Feb 26, 2024



Large language models (LLMs) have made significant progress in generating codes from textual prompts. However, existing benchmarks have mainly concentrated on translating English prompts to multilingual codes or have been constrained to very limited natural languages (NLs). These benchmarks have overlooked the vast landscape of massively multilingual NL to multilingual code, leaving a critical gap in the evaluation of multilingual LLMs. In response, we introduce HumanEval-XL, a massively multilingual code generation benchmark specifically crafted to address this deficiency. HumanEval-XL establishes connections between 23 NLs and 12 programming languages (PLs), and comprises of a collection of 22,080 prompts with an average of 8.33 test cases. By ensuring parallel data across multiple NLs and PLs, HumanEval-XL offers a comprehensive evaluation platform for multilingual LLMs, allowing the assessment of the understanding of different NLs. Our work serves as a pioneering step towards filling the void in evaluating NL generalization in the area of multilingual code generation. We make our evaluation code and data publicly available at \url{https://github.com/FloatAI/HumanEval-XL}.
Towards Structure-aware Paraphrase Identification with Phrase Alignment Using Sentence Encoders
Oct 11, 2022

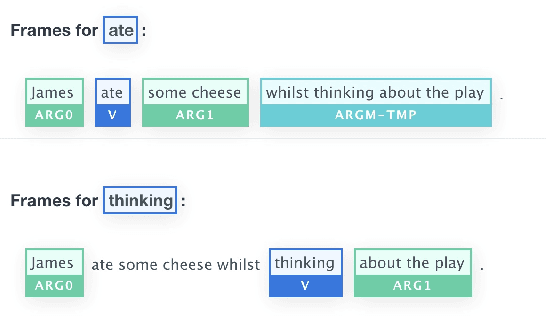
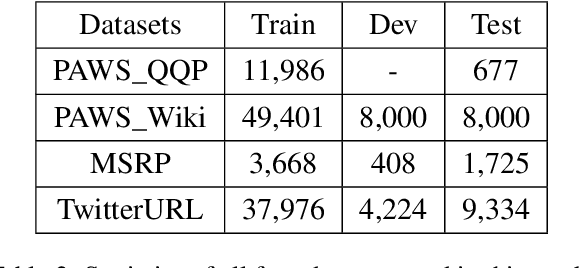
Previous works have demonstrated the effectiveness of utilising pre-trained sentence encoders based on their sentence representations for meaning comparison tasks. Though such representations are shown to capture hidden syntax structures, the direct similarity comparison between them exhibits weak sensitivity to word order and structural differences in given sentences. A single similarity score further makes the comparison process hard to interpret. Therefore, we here propose to combine sentence encoders with an alignment component by representing each sentence as a list of predicate-argument spans (where their span representations are derived from sentence encoders), and decomposing the sentence-level meaning comparison into the alignment between their spans for paraphrase identification tasks. Empirical results show that the alignment component brings in both improved performance and interpretability for various sentence encoders. After closer investigation, the proposed approach indicates increased sensitivity to structural difference and enhanced ability to distinguish non-paraphrases with high lexical overlap.
Representing Syntax and Composition with Geometric Transformations
Jun 03, 2021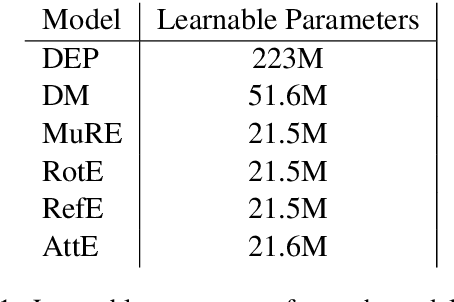
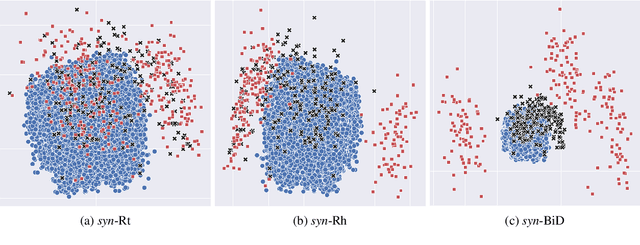
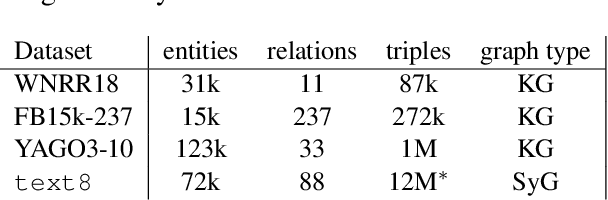
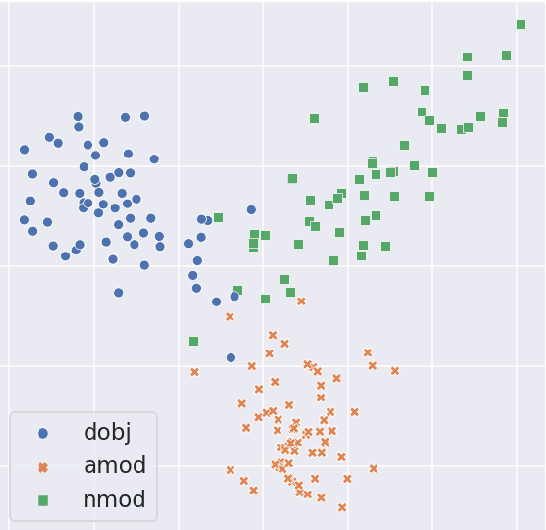
The exploitation of syntactic graphs (SyGs) as a word's context has been shown to be beneficial for distributional semantic models (DSMs), both at the level of individual word representations and in deriving phrasal representations via composition. However, notwithstanding the potential performance benefit, the syntactically-aware DSMs proposed to date have huge numbers of parameters (compared to conventional DSMs) and suffer from data sparsity. Furthermore, the encoding of the SyG links (i.e., the syntactic relations) has been largely limited to linear maps. The knowledge graphs' literature, on the other hand, has proposed light-weight models employing different geometric transformations (GTs) to encode edges in a knowledge graph (KG). Our work explores the possibility of adopting this family of models to encode SyGs. Furthermore, we investigate which GT better encodes syntactic relations, so that these representations can be used to enhance phrase-level composition via syntactic contextualisation.