 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Query Generation for Evidence Collection from Web Search Engines
Mar 15, 2023



It is widely accepted that so-called facts can be checked by searching for information on the Internet. This process requires a fact-checker to formulate a search query based on the fact and to present it to a search engine. Then, relevant and believable passages need to be identified in the search results before a decision is made. This process is carried out by sub-editors at many news and media organisations on a daily basis. Here, we ask the question as to whether it is possible to automate the first step, that of query generation. Can we automatically formulate search queries based on factual statements which are similar to those formulated by human experts? Here, we consider similarity both in terms of textual similarity and with respect to relevant documents being returned by a search engine. First, we introduce a moderate-sized evidence collection dataset which includes 390 factual statements together with associated human-generated search queries and search results. Then, we investigate generating queries using a number of rule-based and automatic text generation methods based on pre-trained large language models (LLMs). We show that these methods have different merits and propose a hybrid approach which has superior performance in practice.
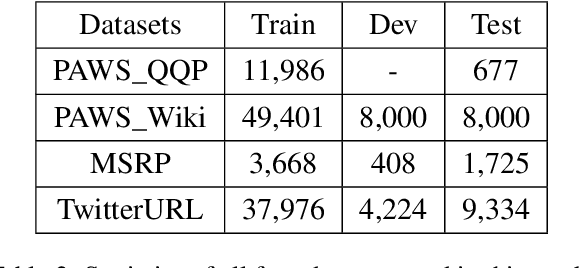
Towards Structure-aware Paraphrase Identification with Phrase Alignment Using Sentence Encoders
Oct 11, 2022

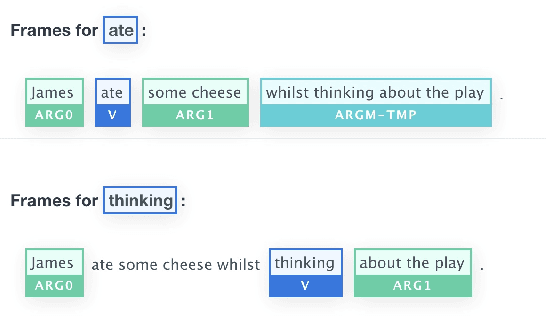
Previous works have demonstrated the effectiveness of utilising pre-trained sentence encoders based on their sentence representations for meaning comparison tasks. Though such representations are shown to capture hidden syntax structures, the direct similarity comparison between them exhibits weak sensitivity to word order and structural differences in given sentences. A single similarity score further makes the comparison process hard to interpret. Therefore, we here propose to combine sentence encoders with an alignment component by representing each sentence as a list of predicate-argument spans (where their span representations are derived from sentence encoders), and decomposing the sentence-level meaning comparison into the alignment between their spans for paraphrase identification tasks. Empirical results show that the alignment component brings in both improved performance and interpretability for various sentence encoders. After closer investigation, the proposed approach indicates increased sensitivity to structural difference and enhanced ability to distinguish non-paraphrases with high lexical overlap.
Representing Syntax and Composition with Geometric Transformations
Jun 03, 2021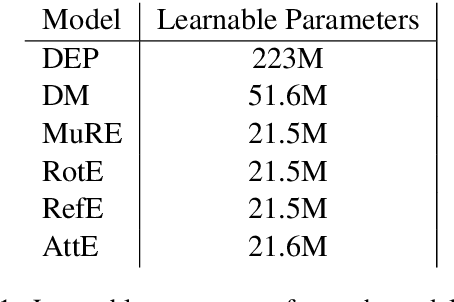
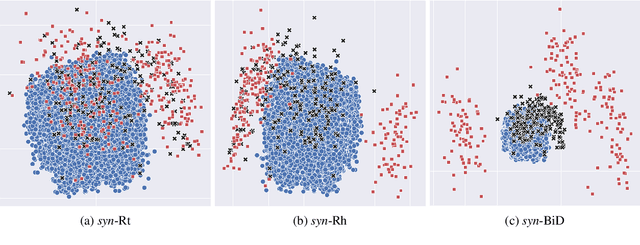
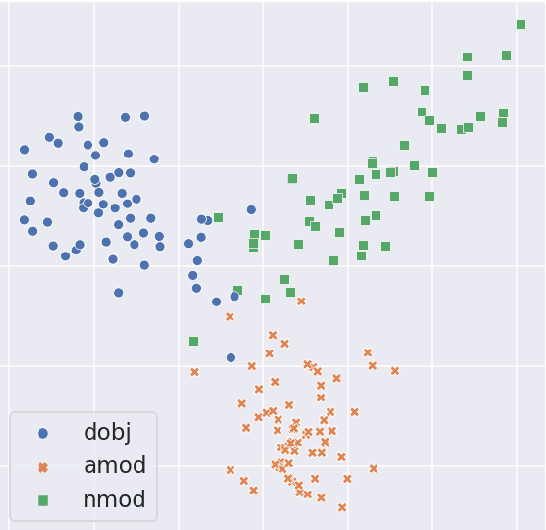
The exploitation of syntactic graphs (SyGs) as a word's context has been shown to be beneficial for distributional semantic models (DSMs), both at the level of individual word representations and in deriving phrasal representations via composition. However, notwithstanding the potential performance benefit, the syntactically-aware DSMs proposed to date have huge numbers of parameters (compared to conventional DSMs) and suffer from data sparsity. Furthermore, the encoding of the SyG links (i.e., the syntactic relations) has been largely limited to linear maps. The knowledge graphs' literature, on the other hand, has proposed light-weight models employing different geometric transformations (GTs) to encode edges in a knowledge graph (KG). Our work explores the possibility of adopting this family of models to encode SyGs. Furthermore, we investigate which GT better encodes syntactic relations, so that these representations can be used to enhance phrase-level composition via syntactic contextualisation.
Data Augmentation for Hypernymy Detection
May 04, 2020
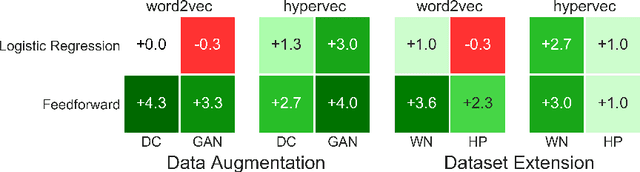
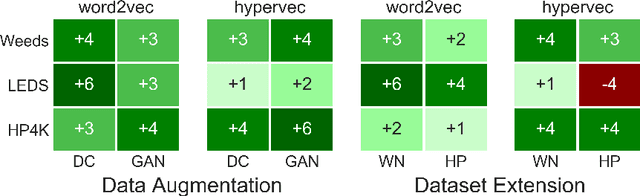
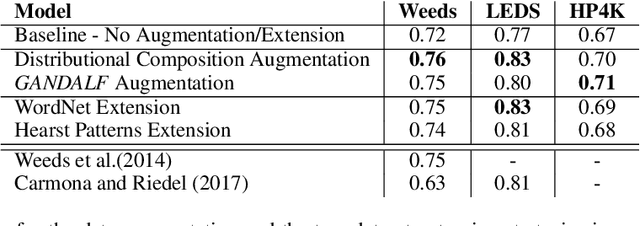
The automatic detection of hypernymy relationships represents a challenging problem in NLP. The successful application of state-of-the-art supervised approaches using distributed representations has generally been impeded by the limited availability of high quality training data. We have developed two novel data augmentation techniques which generate new training examples from existing ones. First, we combine the linguistic principles of hypernym transitivity and intersective modifier-noun composition to generate additional pairs of vectors, such as "small dog - dog" or "small dog - animal", for which a hypernymy relationship can be assumed. Second, we use generative adversarial networks (GANs) to generate pairs of vectors for which the hypernymy relation can also be assumed. We furthermore present two complementary strategies for extending an existing dataset by leveraging linguistic resources such as WordNet. Using an evaluation across 3 different datasets for hypernymy detection and 2 different vector spaces, we demonstrate that both of the proposed automatic data augmentation and dataset extension strategies substantially improve classifier performance.
Improving Semantic Composition with Offset Inference
Apr 21, 2017
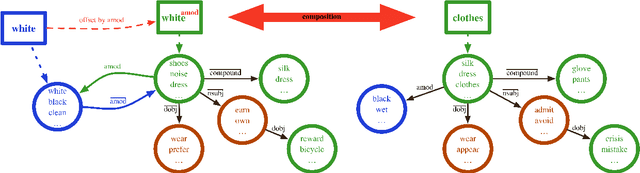

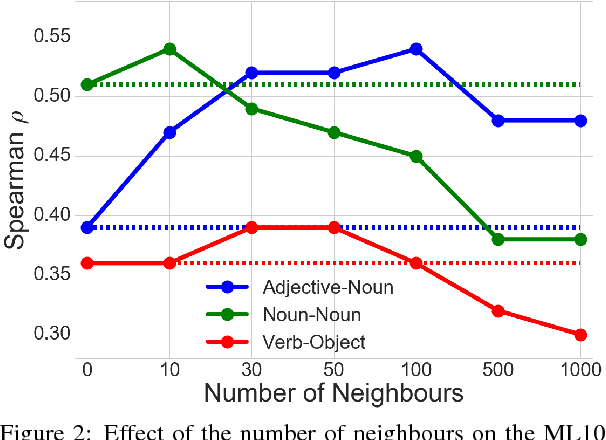
Count-based distributional semantic models suffer from sparsity due to unobserved but plausible co-occurrences in any text collection. This problem is amplified for models like Anchored Packed Trees (APTs), that take the grammatical type of a co-occurrence into account. We therefore introduce a novel form of distributional inference that exploits the rich type structure in APTs and infers missing data by the same mechanism that is used for semantic composition.
One Representation per Word - Does it make Sense for Composition?
Feb 22, 2017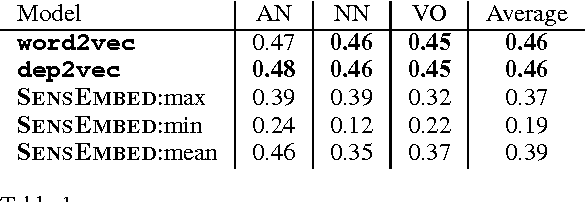
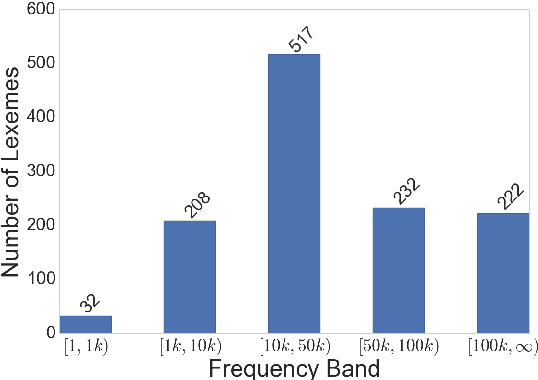

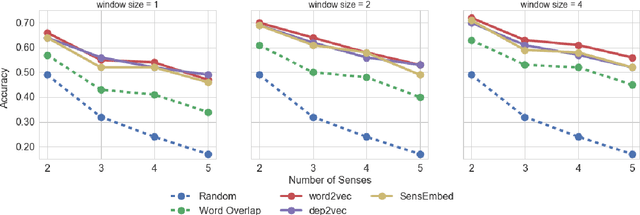
In this paper, we investigate whether an a priori disambiguation of word senses is strictly necessary or whether the meaning of a word in context can be disambiguated through composition alone. We evaluate the performance of off-the-shelf single-vector and multi-sense vector models on a benchmark phrase similarity task and a novel task for word-sense discrimination. We find that single-sense vector models perform as well or better than multi-sense vector models despite arguably less clean elementary representations. Our findings furthermore show that simple composition functions such as pointwise addition are able to recover sense specific information from a single-sense vector model remarkably well.
Aligning Packed Dependency Trees: a theory of composition for distributional semantics
Aug 25, 2016We present a new framework for compositional distributional semantics in which the distributional contexts of lexemes are expressed in terms of anchored packed dependency trees. We show that these structures have the potential to capture the full sentential contexts of a lexeme and provide a uniform basis for the composition of distributional knowledge in a way that captures both mutual disambiguation and generalization.
Improving Sparse Word Representations with Distributional Inference for Semantic Composition
Aug 24, 2016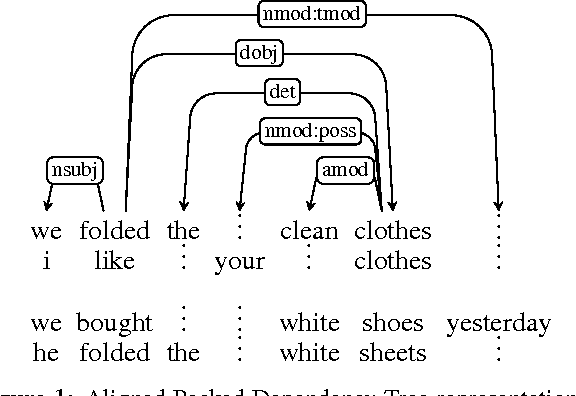


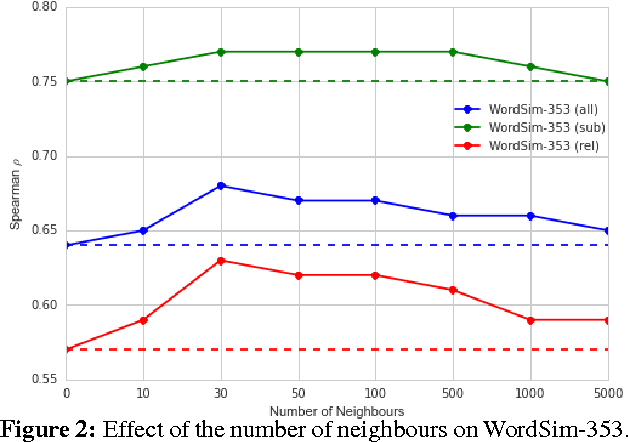
Distributional models are derived from co-occurrences in a corpus, where only a small proportion of all possible plausible co-occurrences will be observed. This results in a very sparse vector space, requiring a mechanism for inferring missing knowledge. Most methods face this challenge in ways that render the resulting word representations uninterpretable, with the consequence that semantic composition becomes hard to model. In this paper we explore an alternative which involves explicitly inferring unobserved co-occurrences using the distributional neighbourhood. We show that distributional inference improves sparse word representations on several word similarity benchmarks and demonstrate that our model is competitive with the state-of-the-art for adjective-noun, noun-noun and verb-object compositions while being fully interpretable.
Encoding Frequency Information in Lexicalized Grammars
Aug 19, 1997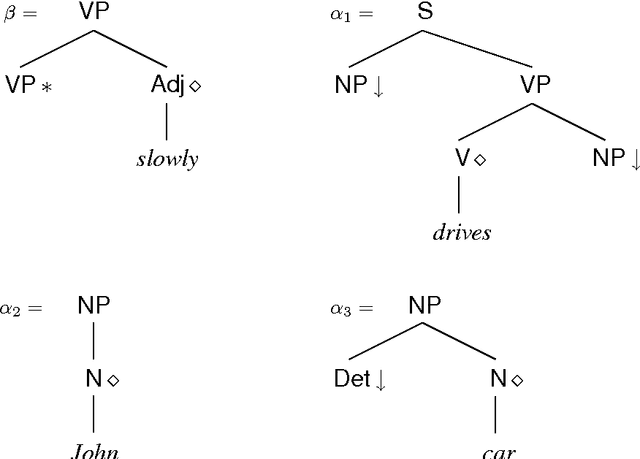
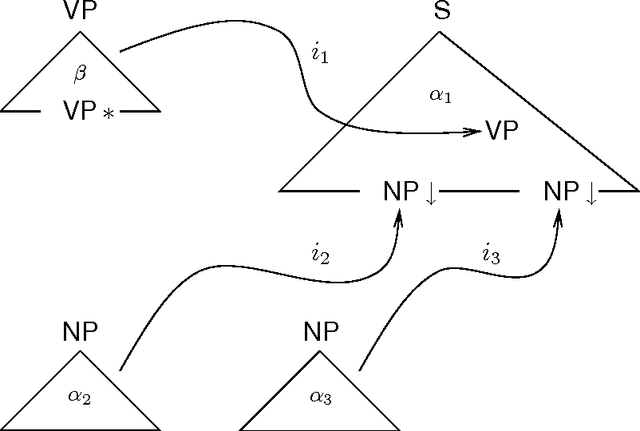

We address the issue of how to associate frequency information with lexicalized grammar formalisms, using Lexicalized Tree Adjoining Grammar as a representative framework. We consider systematically a number of alternative probabilistic frameworks, evaluating their adequacy from both a theoretical and empirical perspective using data from existing large treebanks. We also propose three orthogonal approaches for backing off probability estimates to cope with the large number of parameters involved.
* 10 pages, uses fullname.sty
Encoding Lexicalized Tree Adjoining Grammars with a Nonmonotonic Inheritance Hierarchy
May 15, 1995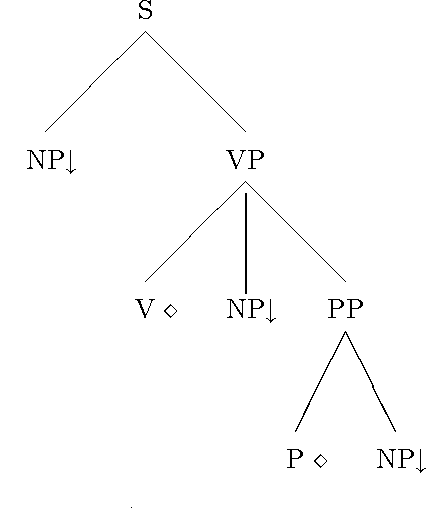
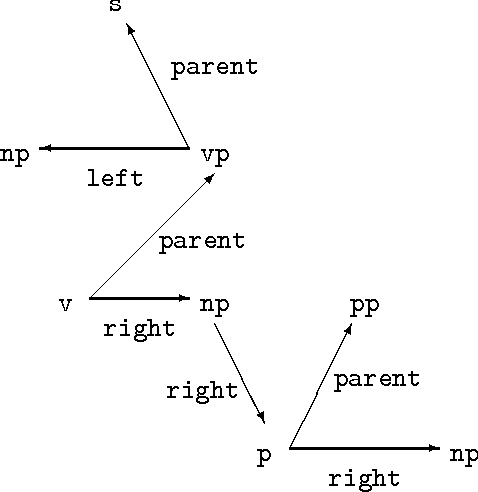
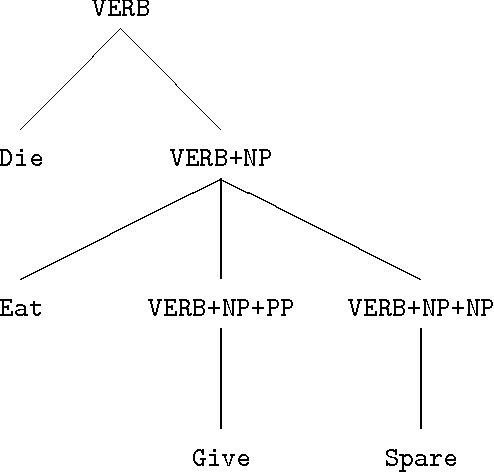
This paper shows how DATR, a widely used formal language for lexical knowledge representation, can be used to define an LTAG lexicon as an inheritance hierarchy with internal lexical rules. A bottom-up featural encoding is used for LTAG trees and this allows lexical rules to be implemented as covariation constraints within feature structures. Such an approach eliminates the considerable redundancy otherwise associated with an LTAG lexicon.
* Latex source, needs aclap.sty, 8 pages