 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus Annotation for Parser Evaluation
Jul 08, 1999
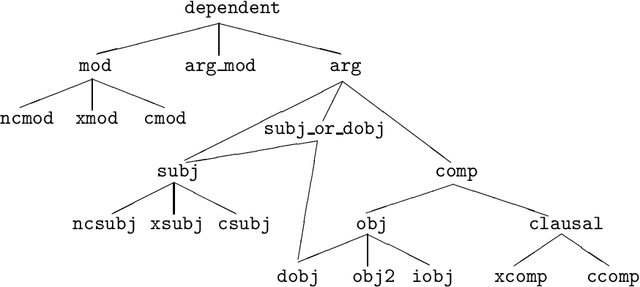

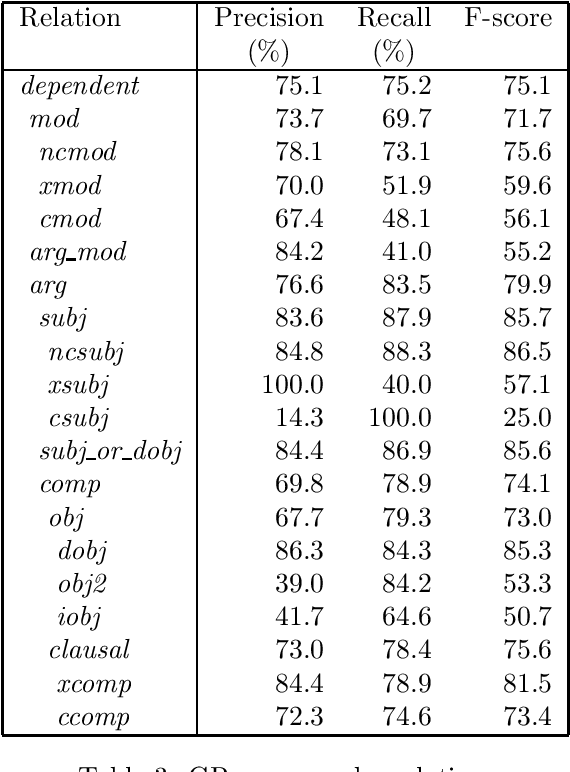
We describe a recently developed corpus annotation scheme for evaluating parsers that avoids shortcomings of current methods. The scheme encodes grammatical relations between heads and dependents, and has been used to mark up a new public-domain corpus of naturally occurring English text. We show how the corpus can be used to evaluate the accuracy of a robust parser, and relate the corpus to extant resources.
* 7 pages, LaTeX (uses eaclap.sty)
Can Subcategorisation Probabilities Help a Statistical Parser?
Jun 21, 1998
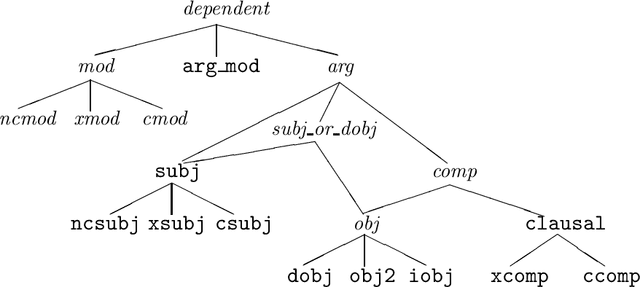
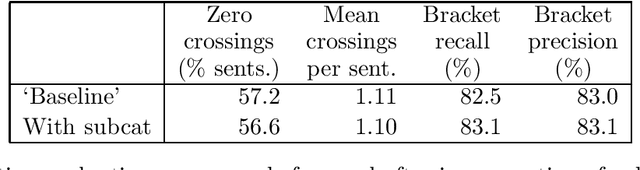
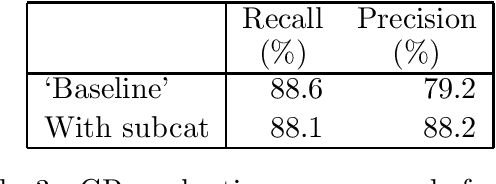
Research into the automatic acquisition of lexical information from corpora is starting to produce large-scale computational lexicons containing data on the relative frequencies of subcategorisation alternatives for individual verbal predicates. However, the empirical question of whether this type of frequency information can in practice improve the accuracy of a statistical parser has not yet been answered. In this paper we describe an experiment with a wide-coverage statistical grammar and parser for English and subcategorisation frequencies acquired from ten million words of text which shows that this information can significantly improve parse accuracy.
* 9 pages, uses colacl.sty
Encoding Frequency Information in Lexicalized Grammars
Aug 19, 1997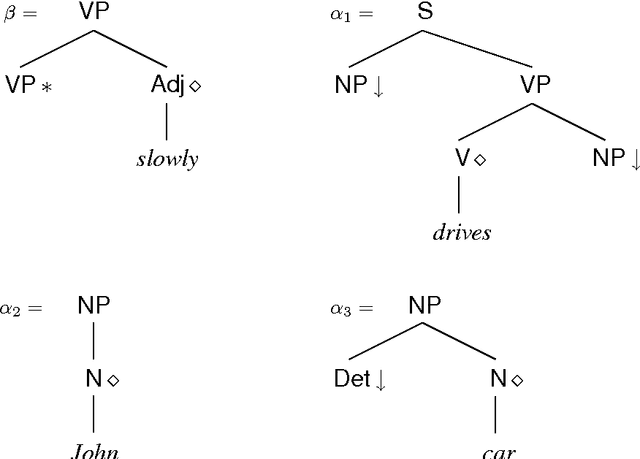
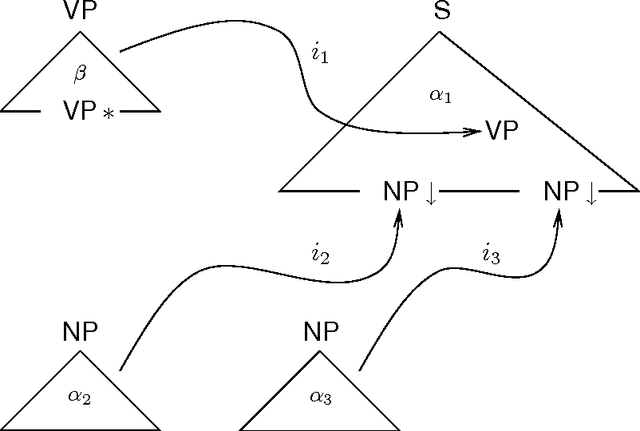

We address the issue of how to associate frequency information with lexicalized grammar formalisms, using Lexicalized Tree Adjoining Grammar as a representative framework. We consider systematically a number of alternative probabilistic frameworks, evaluating their adequacy from both a theoretical and empirical perspective using data from existing large treebanks. We also propose three orthogonal approaches for backing off probability estimates to cope with the large number of parameters involved.
* 10 pages, uses fullname.sty
Automatic Extraction of Subcategorization from Corpora
Feb 04, 1997
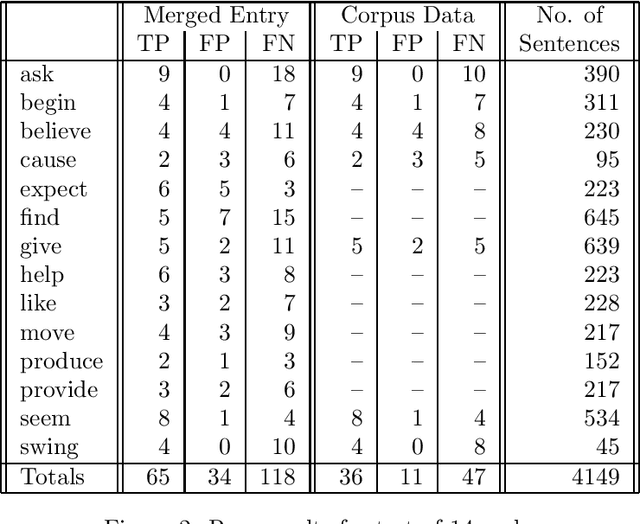

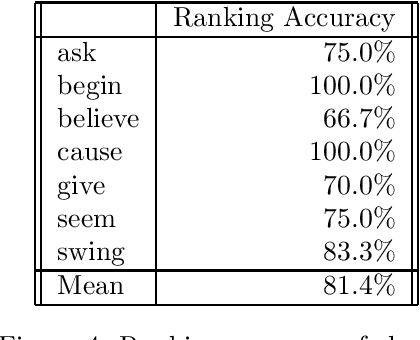
We describe a novel technique and implemented system for constructing a subcategorization dictionary from textual corpora. Each dictionary entry encodes the relative frequency of occurrence of a comprehensive set of subcategorization classes for English. An initial experiment, on a sample of 14 verbs which exhibit multiple complementation patterns, demonstrates that the technique achieves accuracy comparable to previous approaches, which are all limited to a highly restricted set of subcategorization classes. We also demonstrate that a subcategorization dictionary built with the system improves the accuracy of a parser by an appreciable amount.
Apportioning Development Effort in a Probabilistic LR Parsing System through Evaluation
Apr 12, 1996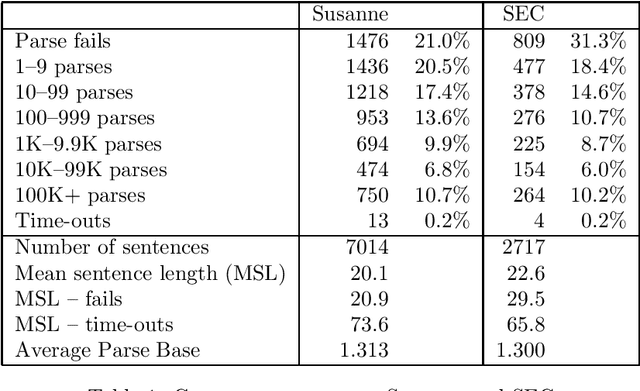
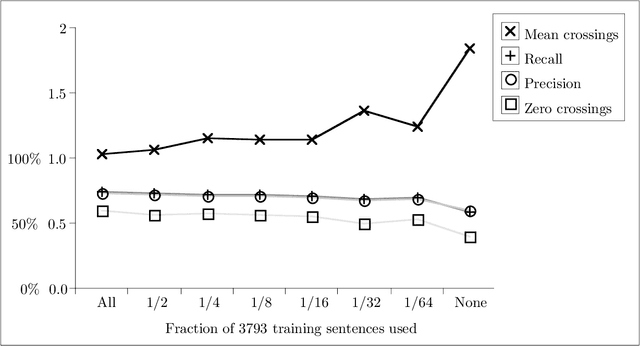
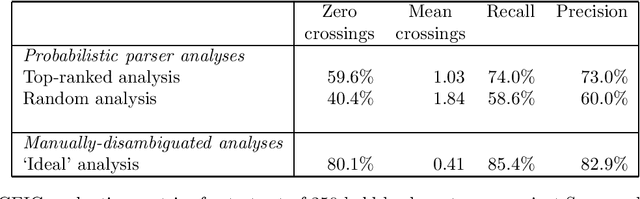
We describe an implemented system for robust domain-independent syntactic parsing of English, using a unification-based grammar of part-of-speech and punctuation labels coupled with a probabilistic LR parser. We present evaluations of the system's performance along several different dimensions; these enable us to assess the contribution that each individual part is making to the success of the system as a whole, and thus prioritise the effort to be devoted to its further enhancement. Currently, the system is able to parse around 80% of sentences in a substantial corpus of general text containing a number of distinct genres. On a random sample of 250 such sentences the system has a mean crossing bracket rate of 0.71 and recall and precision of 83% and 84% respectively when evaluated against manually-disambiguated analyses.
* 10 pages, 1 Postscript figure. To Appear in Proceedings of the Conference on Empirical Methods in Natural Language Processing, University of Pennsylvania, May 1996
Developing and Evaluating a Probabilistic LR Parser of Part-of-Speech and Punctuation Labels
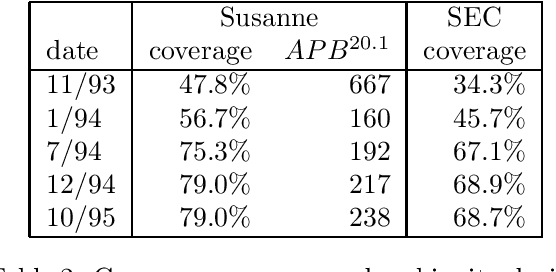
Oct 09, 1995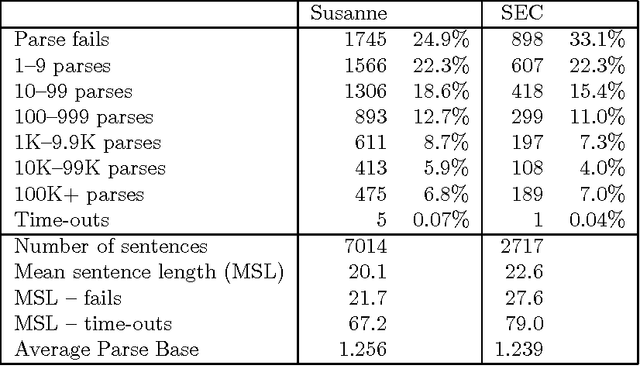


We describe an approach to robust domain-independent syntactic parsing of unrestricted naturally-occurring (English) input. The technique involves parsing sequences of part-of-speech and punctuation labels using a unification-based grammar coupled with a probabilistic LR parser. We describe the coverage of several corpora using this grammar and report the results of a parsing experiment using probabilities derived from bracketed training data. We report the first substantial experiments to assess the contribution of punctuation to deriving an accurate syntactic analysis, by parsing identical texts both with and without naturally-occurring punctuation marks.
* 11 pages, standard LaTeX
Relating Complexity to Practical Performance in Parsing with Wide-Coverage Unification Grammars
May 31, 1994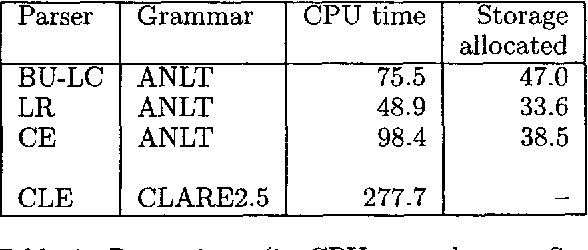
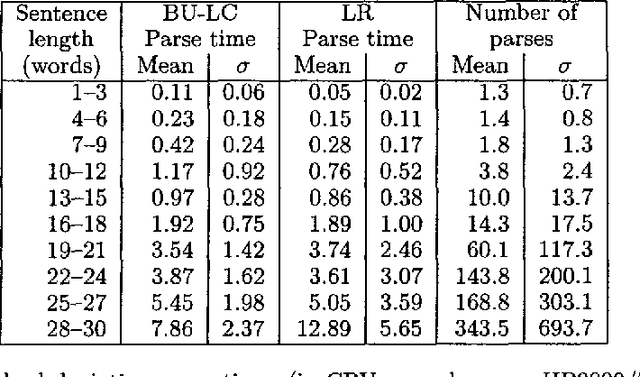
The paper demonstrates that exponential complexities with respect to grammar size and input length have little impact on the performance of three unification-based parsing algorithms, using a wide-coverage grammar. The results imply that the study and optimisation of unification-based parsing must rely on empirical data until complexity theory can more accurately predict the practical behaviour of such parsers.
* 8 pages, LaTeX source (one figure not included) To appear in ACL-94