Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Subcategorisation Probabilities Help a Statistical Parser?
Paper and Code
Jun 21, 1998
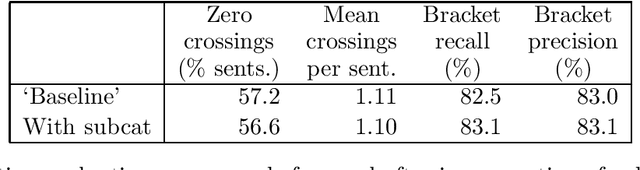
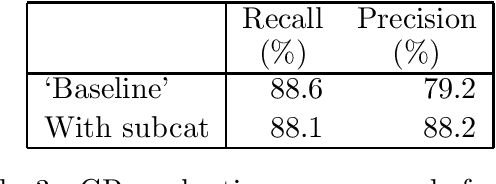
Research into the automatic acquisition of lexical information from corpora is starting to produce large-scale computational lexicons containing data on the relative frequencies of subcategorisation alternatives for individual verbal predicates. However, the empirical question of whether this type of frequency information can in practice improve the accuracy of a statistical parser has not yet been answered. In this paper we describe an experiment with a wide-coverage statistical grammar and parser for English and subcategorisation frequencies acquired from ten million words of text which shows that this information can significantly improve parse accuracy.
* 6th Workshop on Very Large Corpora, Montreal, Canada, 1998 * 9 pages, uses colacl.sty
View paper on