 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApportioning Development Effort in a Probabilistic LR Parsing System through Evaluation
Paper and Code
Apr 12, 1996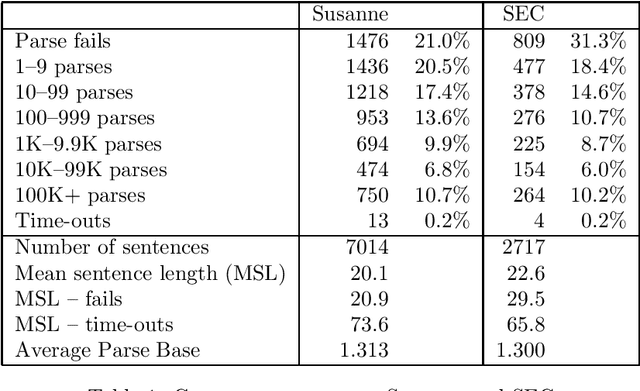
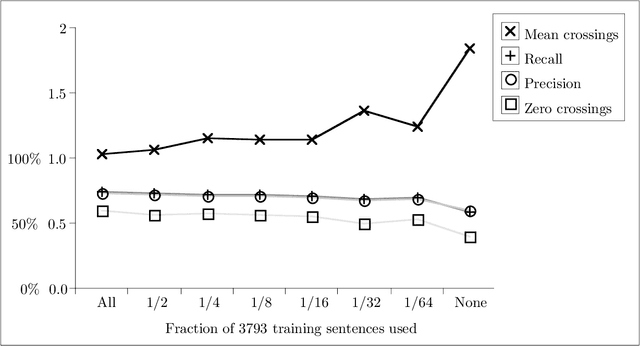
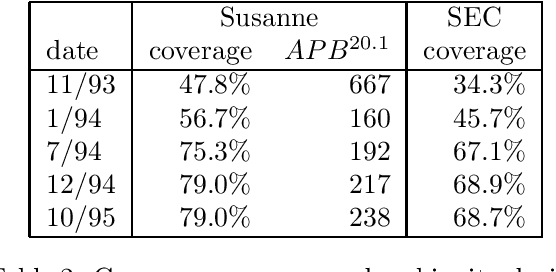
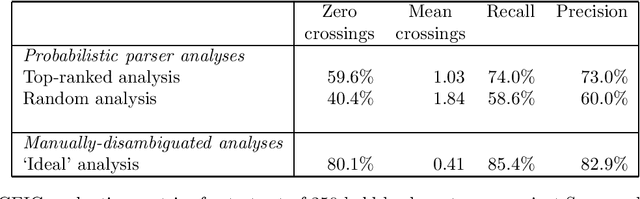
We describe an implemented system for robust domain-independent syntactic parsing of English, using a unification-based grammar of part-of-speech and punctuation labels coupled with a probabilistic LR parser. We present evaluations of the system's performance along several different dimensions; these enable us to assess the contribution that each individual part is making to the success of the system as a whole, and thus prioritise the effort to be devoted to its further enhancement. Currently, the system is able to parse around 80% of sentences in a substantial corpus of general text containing a number of distinct genres. On a random sample of 250 such sentences the system has a mean crossing bracket rate of 0.71 and recall and precision of 83% and 84% respectively when evaluated against manually-disambiguated analyses.