Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Extraction of Subcategorization from Corpora
Paper and Code
Feb 04, 1997
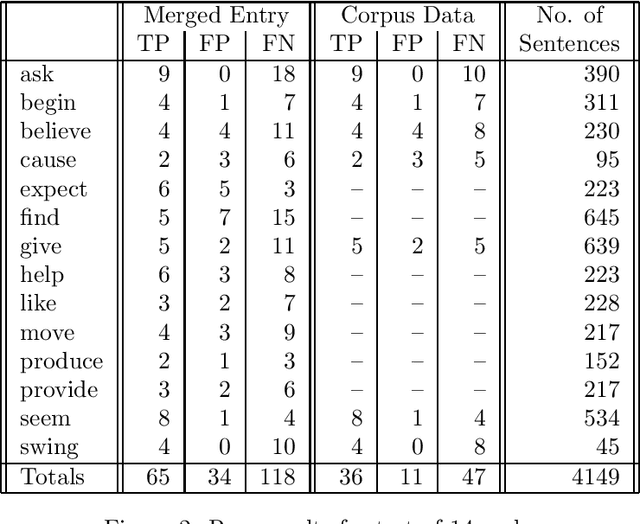

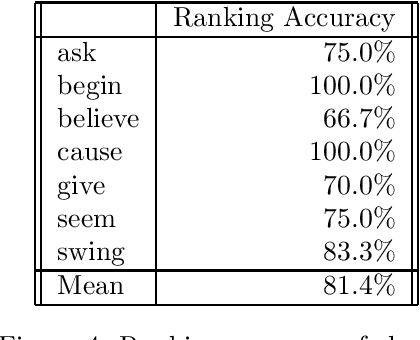
We describe a novel technique and implemented system for constructing a subcategorization dictionary from textual corpora. Each dictionary entry encodes the relative frequency of occurrence of a comprehensive set of subcategorization classes for English. An initial experiment, on a sample of 14 verbs which exhibit multiple complementation patterns, demonstrates that the technique achieves accuracy comparable to previous approaches, which are all limited to a highly restricted set of subcategorization classes. We also demonstrate that a subcategorization dictionary built with the system improves the accuracy of a parser by an appreciable amount.
* 8 pages; requires aclap.sty. To appear in ANLP-97
View paper on