Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping and Evaluating a Probabilistic LR Parser of Part-of-Speech and Punctuation Labels
Paper and Code
Oct 09, 1995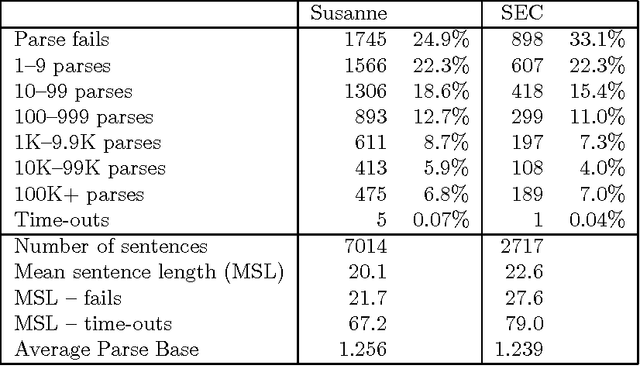


We describe an approach to robust domain-independent syntactic parsing of unrestricted naturally-occurring (English) input. The technique involves parsing sequences of part-of-speech and punctuation labels using a unification-based grammar coupled with a probabilistic LR parser. We describe the coverage of several corpora using this grammar and report the results of a parsing experiment using probabilities derived from bracketed training data. We report the first substantial experiments to assess the contribution of punctuation to deriving an accurate syntactic analysis, by parsing identical texts both with and without naturally-occurring punctuation marks.
* 4th International Workshop on Parsing Technologies (IWPT-95),
48-58 * 11 pages, standard LaTeX
View paper on