 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation
Sep 18, 2024



Evaluating production-level retrieval systems at scale is a crucial yet challenging task due to the limited availability of a large pool of well-trained human annotators. Large Language Models (LLMs) have the potential to address this scaling issue and offer a viable alternative to humans for the bulk of annotation tasks. In this paper, we propose a framework for assessing the product search engines in a large-scale e-commerce setting, leveraging Multimodal LLMs for (i) generating tailored annotation guidelines for individual queries, and (ii) conducting the subsequent annotation task. Our method, validated through deployment on a large e-commerce platform, demonstrates comparable quality to human annotations, significantly reduces time and cost, facilitates rapid problem discovery, and provides an effective solution for production-level quality control at scale.
What should I wear to a party in a Greek taverna? Evaluation for Conversational Agents in the Fashion Domain
Aug 13, 2024



Large language models (LLMs) are poised to revolutionize the domain of online fashion retail, enhancing customer experience and discovery of fashion online. LLM-powered conversational agents introduce a new way of discovery by directly interacting with customers, enabling them to express in their own ways, refine their needs, obtain fashion and shopping advice that is relevant to their taste and intent. For many tasks in e-commerce, such as finding a specific product, conversational agents need to convert their interactions with a customer to a specific call to different backend systems, e.g., a search system to showcase a relevant set of products. Therefore, evaluating the capabilities of LLMs to perform those tasks related to calling other services is vital. However, those evaluations are generally complex, due to the lack of relevant and high quality datasets, and do not align seamlessly with business needs, amongst others. To this end, we created a multilingual evaluation dataset of 4k conversations between customers and a fashion assistant in a large e-commerce fashion platform to measure the capabilities of LLMs to serve as an assistant between customers and a backend engine. We evaluate a range of models, showcasing how our dataset scales to business needs and facilitates iterative development of tools.
Zero-shot Cross-Linguistic Learning of Event Semantics
Jul 05, 2022


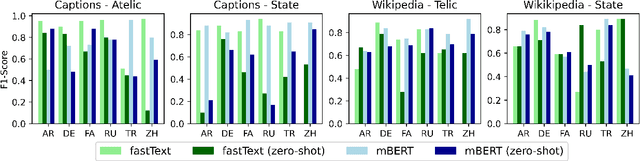
Typologically diverse languages offer systems of lexical and grammatical aspect that allow speakers to focus on facets of event structure in ways that comport with the specific communicative setting and discourse constraints they face. In this paper, we look specifically at captions of images across Arabic, Chinese, Farsi, German, Russian, and Turkish and describe a computational model for predicting lexical aspects. Despite the heterogeneity of these languages, and the salient invocation of distinctive linguistic resources across their caption corpora, speakers of these languages show surprising similarities in the ways they frame image content. We leverage this observation for zero-shot cross-lingual learning and show that lexical aspects can be predicted for a given language despite not having observed any annotated data for this language at all.
Aspectuality Across Genre: A Distributional Semantics Approach
Oct 31, 2020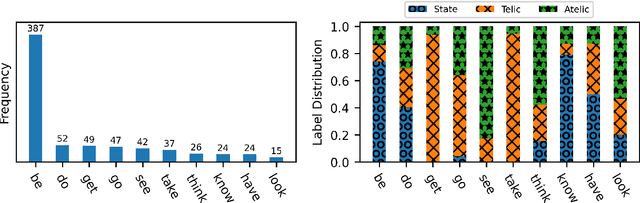
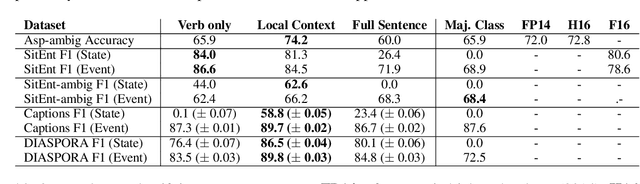
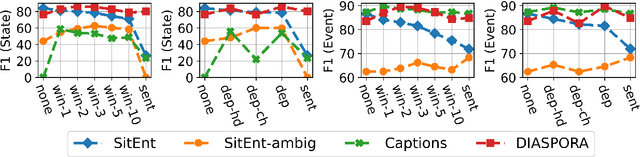
The interpretation of the lexical aspect of verbs in English plays a crucial role for recognizing textual entailment and learning discourse-level inferences. We show that two elementary dimensions of aspectual class, states vs. events, and telic vs. atelic events, can be modelled effectively with distributional semantics. We find that a verb's local context is most indicative of its aspectual class, and demonstrate that closed class words tend to be stronger discriminating contexts than content words. Our approach outperforms previous work on three datasets. Lastly, we contribute a dataset of human--human conversations annotated with lexical aspect and present experiments that show the correlation of telicity with genre and discourse goals.
STAR: A Schema-Guided Dialog Dataset for Transfer Learning
Oct 22, 2020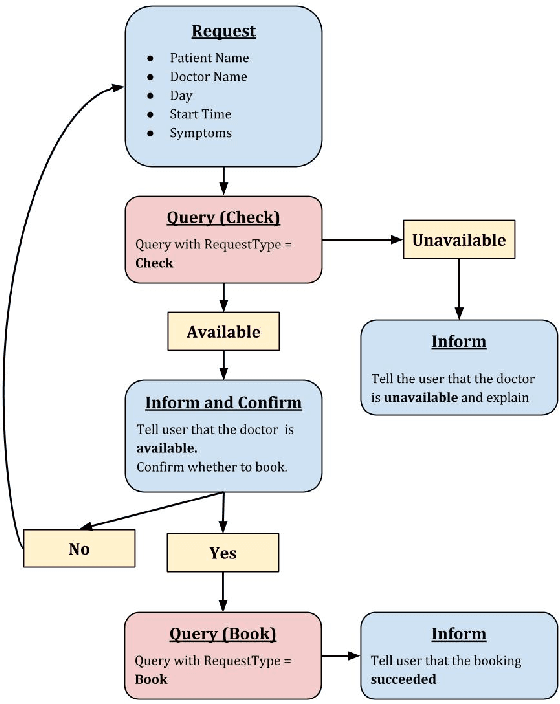
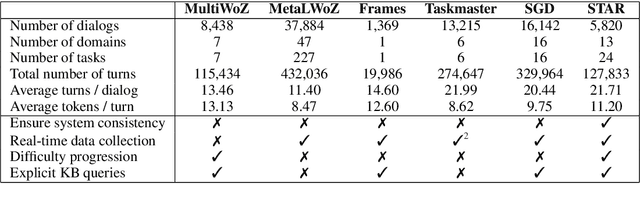
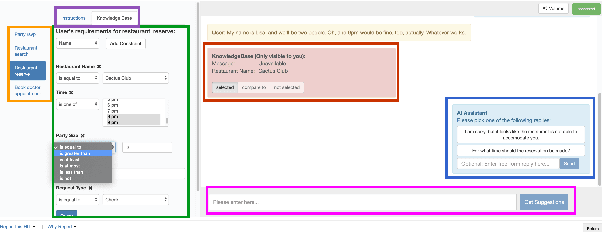
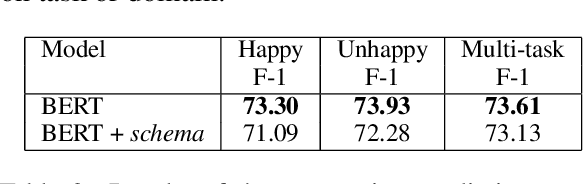
We present STAR, a schema-guided task-oriented dialog dataset consisting of 127,833 utterances and knowledge base queries across 5,820 task-oriented dialogs in 13 domains that is especially designed to facilitate task and domain transfer learning in task-oriented dialog. Furthermore, we propose a scalable crowd-sourcing paradigm to collect arbitrarily large datasets of the same quality as STAR. Moreover, we introduce novel schema-guided dialog models that use an explicit description of the task(s) to generalize from known to unknown tasks. We demonstrate the effectiveness of these models, particularly for zero-shot generalization across tasks and domains.
Going Beyond T-SNE: Exposing \texttt{whatlies} in Text Embeddings
Sep 04, 2020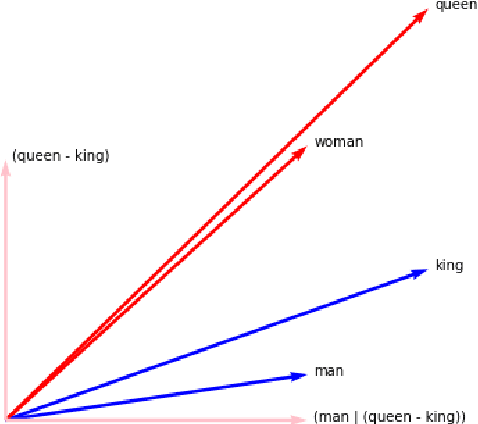
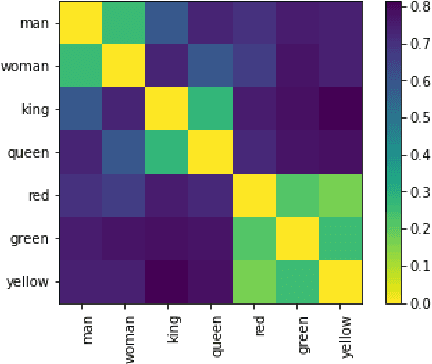
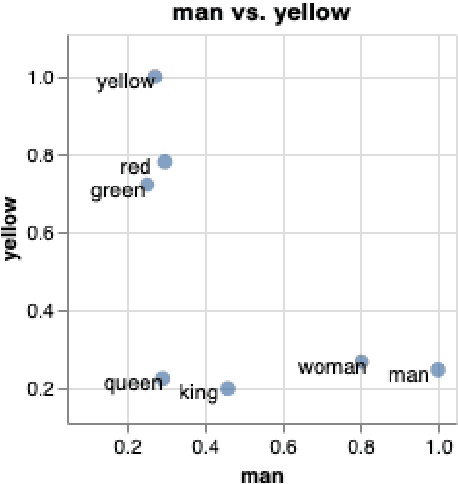
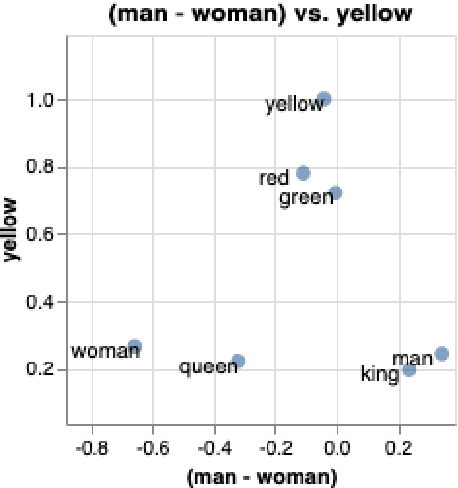
We introduce whatlies, an open source toolkit for visually inspecting word and sentence embeddings. The project offers a unified and extensible API with current support for a range of popular embedding backends including spaCy, tfhub, huggingface transformers, gensim, fastText and BytePair embeddings. The package combines a domain specific language for vector arithmetic with visualisation tools that make exploring word embeddings more intuitive and concise. It offers support for many popular dimensionality reduction techniques as well as many interactive visualisations that can either be statically exported or shared via Jupyter notebooks. The project documentation is available from https://rasahq.github.io/whatlies/.
Data Augmentation for Hypernymy Detection
May 04, 2020
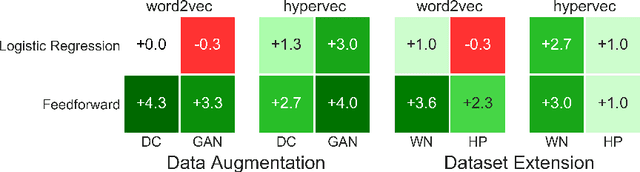
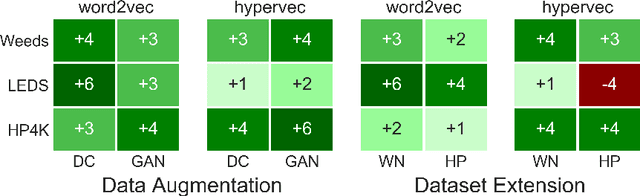
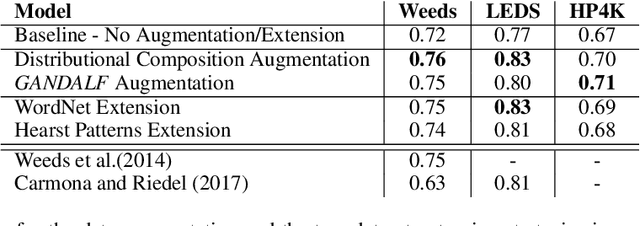
The automatic detection of hypernymy relationships represents a challenging problem in NLP. The successful application of state-of-the-art supervised approaches using distributed representations has generally been impeded by the limited availability of high quality training data. We have developed two novel data augmentation techniques which generate new training examples from existing ones. First, we combine the linguistic principles of hypernym transitivity and intersective modifier-noun composition to generate additional pairs of vectors, such as "small dog - dog" or "small dog - animal", for which a hypernymy relationship can be assumed. Second, we use generative adversarial networks (GANs) to generate pairs of vectors for which the hypernymy relation can also be assumed. We furthermore present two complementary strategies for extending an existing dataset by leveraging linguistic resources such as WordNet. Using an evaluation across 3 different datasets for hypernymy detection and 2 different vector spaces, we demonstrate that both of the proposed automatic data augmentation and dataset extension strategies substantially improve classifier performance.
Temporal and Aspectual Entailment
Apr 02, 2019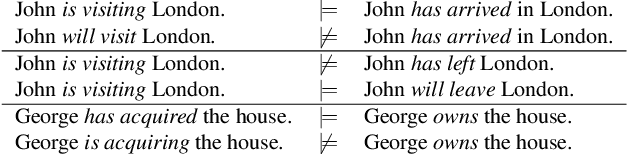
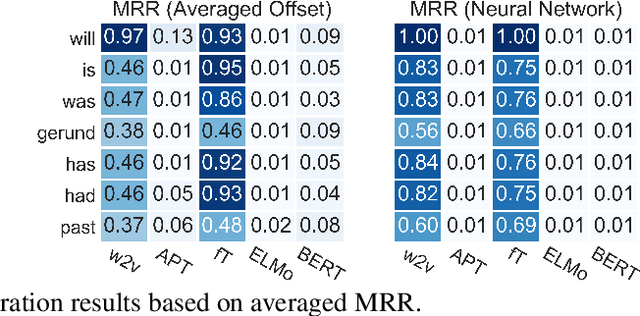
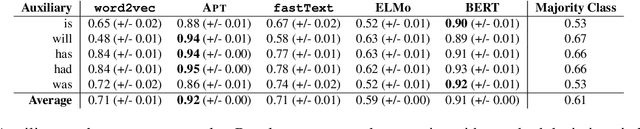
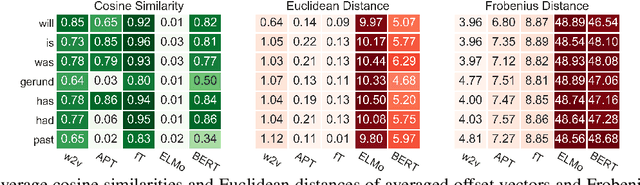
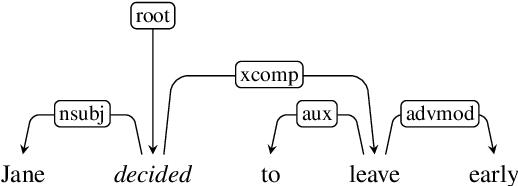
Inferences regarding "Jane's arrival in London" from predications such as "Jane is going to London" or "Jane has gone to London" depend on tense and aspect of the predications. Tense determines the temporal location of the predication in the past, present or future of the time of utterance. The aspectual auxiliaries on the other hand specify the internal constituency of the event, i.e. whether the event of "going to London" is completed and whether its consequences hold at that time or not. While tense and aspect are among the most important factors for determining natural language inference, there has been very little work to show whether modern NLP models capture these semantic concepts. In this paper we propose a novel entailment dataset and analyse the ability of a range of recently proposed NLP models to perform inference on temporal predications. We show that the models encode a substantial amount of morphosyntactic information relating to tense and aspect, but fail to model inferences that require reasoning with these semantic properties.
Improving Semantic Composition with Offset Inference
Apr 21, 2017
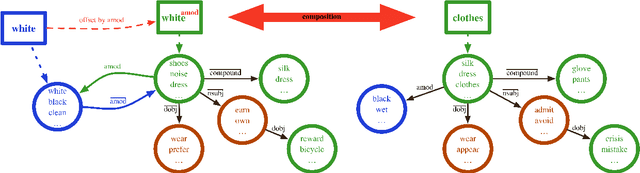

Count-based distributional semantic models suffer from sparsity due to unobserved but plausible co-occurrences in any text collection. This problem is amplified for models like Anchored Packed Trees (APTs), that take the grammatical type of a co-occurrence into account. We therefore introduce a novel form of distributional inference that exploits the rich type structure in APTs and infers missing data by the same mechanism that is used for semantic composition.
One Representation per Word - Does it make Sense for Composition?
Feb 22, 2017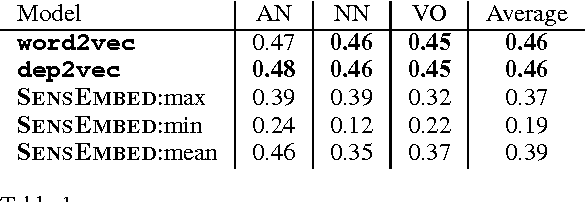

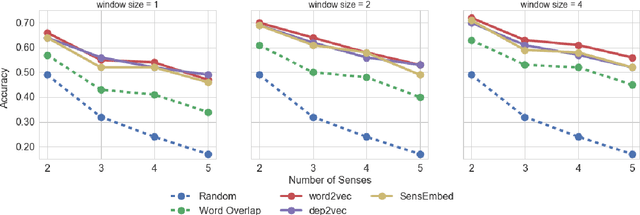
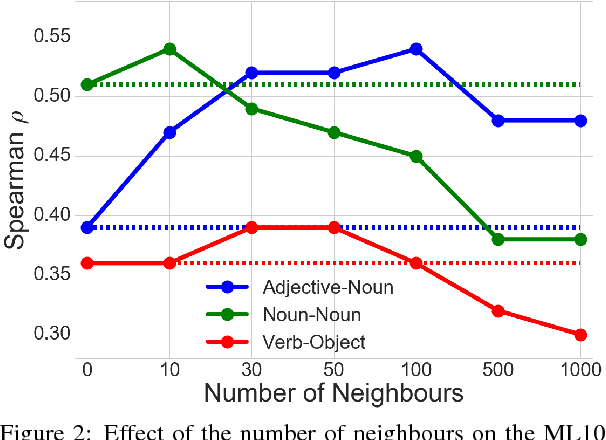
In this paper, we investigate whether an a priori disambiguation of word senses is strictly necessary or whether the meaning of a word in context can be disambiguated through composition alone. We evaluate the performance of off-the-shelf single-vector and multi-sense vector models on a benchmark phrase similarity task and a novel task for word-sense discrimination. We find that single-sense vector models perform as well or better than multi-sense vector models despite arguably less clean elementary representations. Our findings furthermore show that simple composition functions such as pointwise addition are able to recover sense specific information from a single-sense vector model remarkably well.