 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation
Sep 18, 2024



Evaluating production-level retrieval systems at scale is a crucial yet challenging task due to the limited availability of a large pool of well-trained human annotators. Large Language Models (LLMs) have the potential to address this scaling issue and offer a viable alternative to humans for the bulk of annotation tasks. In this paper, we propose a framework for assessing the product search engines in a large-scale e-commerce setting, leveraging Multimodal LLMs for (i) generating tailored annotation guidelines for individual queries, and (ii) conducting the subsequent annotation task. Our method, validated through deployment on a large e-commerce platform, demonstrates comparable quality to human annotations, significantly reduces time and cost, facilitates rapid problem discovery, and provides an effective solution for production-level quality control at scale.
Task-Specific Embeddings for Ante-Hoc Explainable Text Classification
Nov 30, 2022



Current state-of-the-art approaches to text classification typically leverage BERT-style Transformer models with a softmax classifier, jointly fine-tuned to predict class labels of a target task. In this paper, we instead propose an alternative training objective in which we learn task-specific embeddings of text: our proposed objective learns embeddings such that all texts that share the same target class label should be close together in the embedding space, while all others should be far apart. This allows us to replace the softmax classifier with a more interpretable k-nearest-neighbor classification approach. In a series of experiments, we show that this yields a number of interesting benefits: (1) The resulting order induced by distances in the embedding space can be used to directly explain classification decisions. (2) This facilitates qualitative inspection of the training data, helping us to better understand the problem space and identify labelling quality issues. (3) The learned distances to some degree generalize to unseen classes, allowing us to incrementally add new classes without retraining the model. We present extensive experiments which show that the benefits of ante-hoc explainability and incremental learning come at no cost in overall classification accuracy, thus pointing to practical applicability of our proposed approach.
Enhancing Product Safety in E-Commerce with NLP
Oct 25, 2022Ensuring safety of the products offered to the customers is of paramount importance to any e- commerce platform. Despite stringent quality and safety checking of products listed on these platforms, occasionally customers might receive a product that can pose a safety issue arising out of its use. In this paper, we present an innovative mechanism of how a large scale multinational e-commerce platform, Zalando, uses Natural Language Processing techniques to assist timely investigation of the potentially unsafe products mined directly from customer written claims in unstructured plain text. We systematically describe the types of safety issues that concern Zalando customers. We demonstrate how we map this core business problem into a supervised text classification problem with highly imbalanced, noisy, multilingual data in a AI-in-the-loop setup with a focus on Key Performance Indicator (KPI) driven evaluation. Finally, we present detailed ablation studies to show a comprehensive comparison between different classification techniques. We conclude the work with how this NLP model was deployed.
Efficient Ladder-style DenseNets for Semantic Segmentation of Large Images
May 14, 2019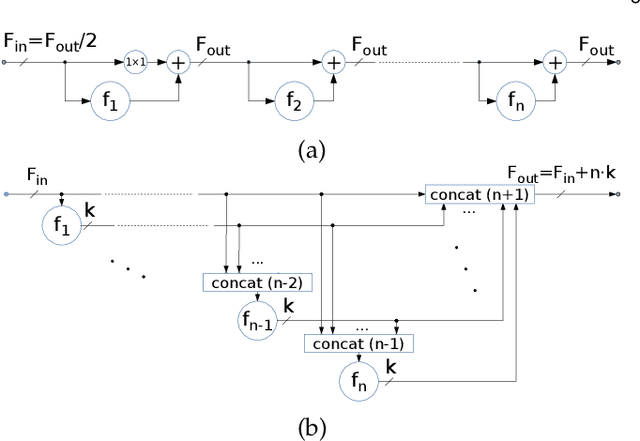
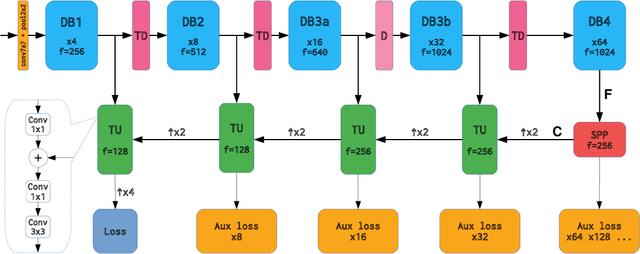
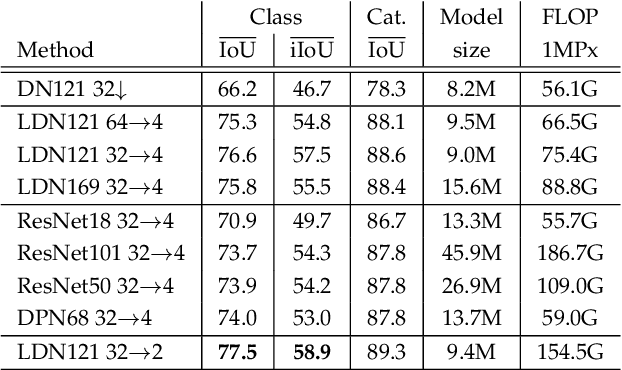
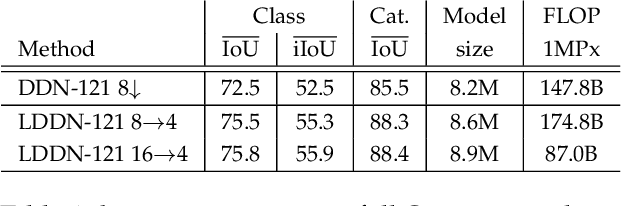
Recent progress of deep image classification models has provided great potential to improve state-of-the-art performance in related computer vision tasks. However, the transition to semantic segmentation is hampered by strict memory limitations of contemporary GPUs. The extent of feature map caching required by convolutional backprop poses significant challenges even for moderately sized Pascal images, while requiring careful architectural considerations when the source resolution is in the megapixel range. To address these concerns, we propose a novel DenseNet-based ladder-style architecture which features high modelling power and a very lean upsampling datapath. We also propose to substantially reduce the extent of feature map caching by exploiting inherent spatial efficiency of the DenseNet feature extractor. The resulting models deliver high performance with fewer parameters than competitive approaches, and allow training at megapixel resolution on commodity hardware. The presented experimental results outperform the state-of-the-art in terms of prediction accuracy and execution speed on Cityscapes, Pascal VOC 2012, CamVid and ROB 2018 datasets. Source code will be released upon publication.
Read classification using semi-supervised deep learning
Apr 23, 2019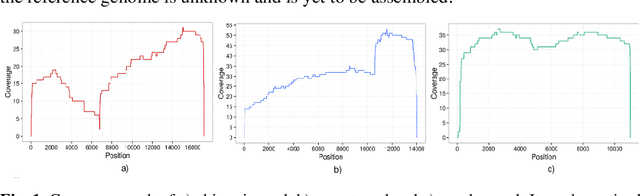
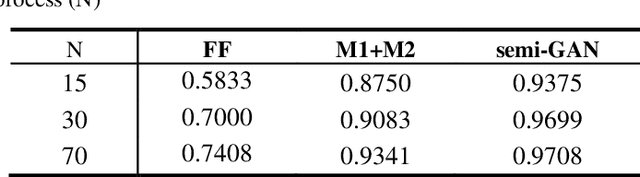
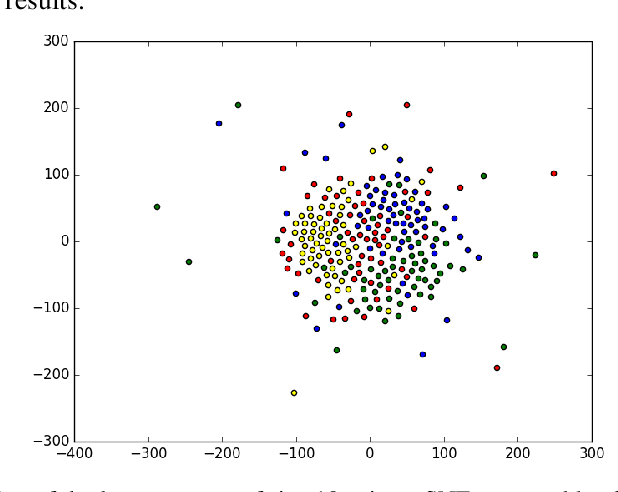
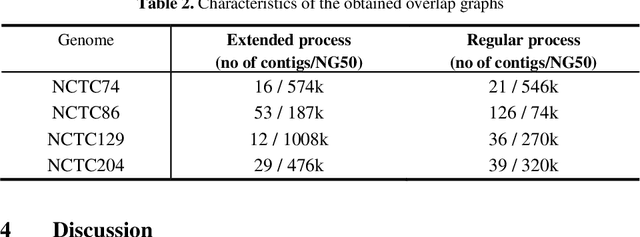
In this paper, we propose a semi-supervised deep learning method for detecting the specific types of reads that impede the de novo genome assembly process. Instead of dealing directly with sequenced reads, we analyze their coverage graphs converted to 1D-signals. We noticed that specific signal patterns occur in each relevant class of reads. Semi-supervised approach is chosen because manually labelling the data is a very slow and tedious process, so our goal was to facilitate the assembly process with as little labeled data as possible. We tested two models to learn patterns in the coverage graphs: M1+M2 and semi-GAN. We evaluated the performance of each model based on a manually labeled dataset that comprises various reads from multiple reference genomes with respect to the number of labeled examples that were used during the training process. In addition, we embedded our detection in the assembly process which improved the quality of assemblies.