 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense outlier detection and open-set recognition based on training with noisy negative images
Jan 22, 2021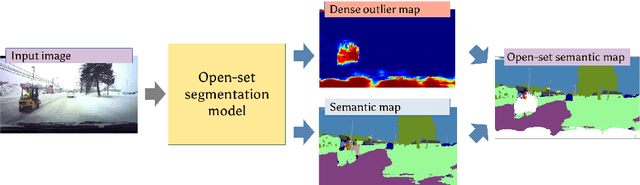
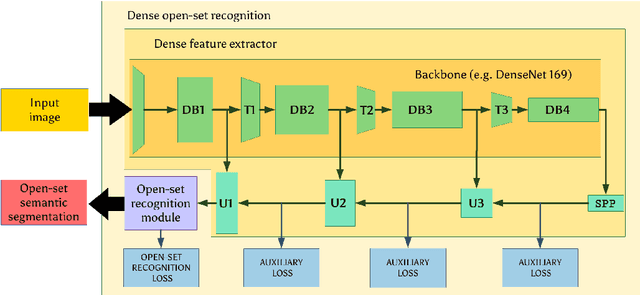
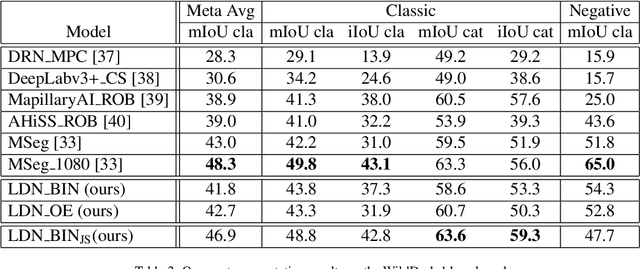
Deep convolutional models often produce inadequate predictions for inputs foreign to the training distribution. Consequently, the problem of detecting outlier images has recently been receiving a lot of attention. Unlike most previous work, we address this problem in the dense prediction context in order to be able to locate outlier objects in front of in-distribution background. Our approach is based on two reasonable assumptions. First, we assume that the inlier dataset is related to some narrow application field (e.g.~road driving). Second, we assume that there exists a general-purpose dataset which is much more diverse than the inlier dataset (e.g.~ImageNet-1k). We consider pixels from the general-purpose dataset as noisy negative training samples since most (but not all) of them are outliers. We encourage the model to recognize borders between known and unknown by pasting jittered negative patches over inlier training images. Our experiments target two dense open-set recognition benchmarks (WildDash 1 and Fishyscapes) and one dense open-set recognition dataset (StreetHazard). Extensive performance evaluation indicates competitive potential of the proposed approach.
Simultaneous Semantic Segmentation and Outlier Detection in Presence of Domain Shift
Aug 03, 2019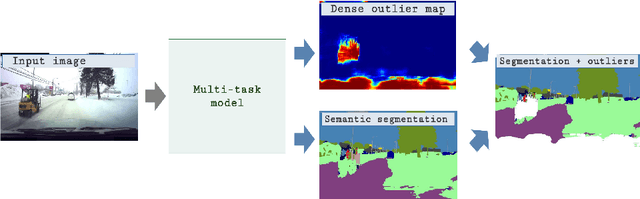
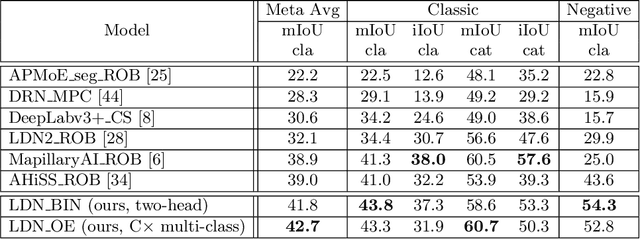
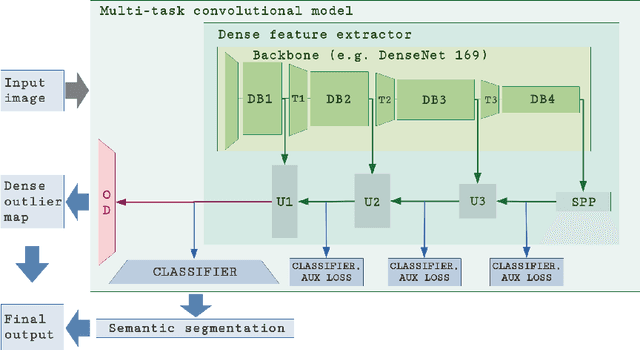
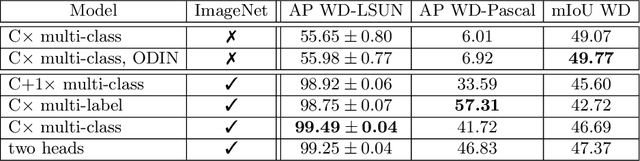
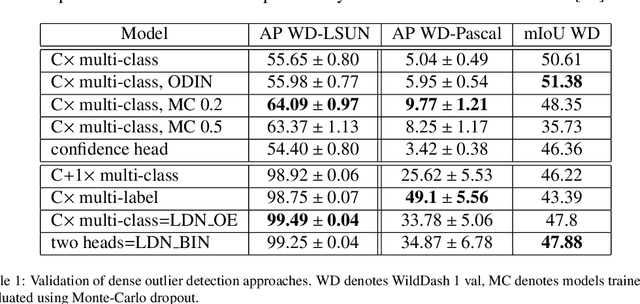
Recent success on realistic road driving datasets has increased interest in exploring robust performance in real-world applications. One of the major unsolved problems is to identify image content which can not be reliably recognized with a given inference engine. We therefore study approaches to recover a dense outlier map alongside the primary task with a single forward pass, by relying on shared convolutional features. We consider semantic segmentation as the primary task and perform extensive validation on WildDash val (inliers), LSUN val (outliers), and pasted objects from Pascal VOC 2007 (outliers). We achieve the best validation performance by training to discriminate inliers from pasted ImageNet-1k content, even though ImageNet-1k contains many road-driving pixels, and, at least nominally, fails to account for the full diversity of the visual world. The proposed two-head model performs comparably to the C-way multi-class model trained to predict uniform distribution in outliers, while outperforming several other validated approaches. We evaluate our best two models on the WildDash test dataset and set a new state of the art on the WildDash benchmark.
Efficient Ladder-style DenseNets for Semantic Segmentation of Large Images
May 14, 2019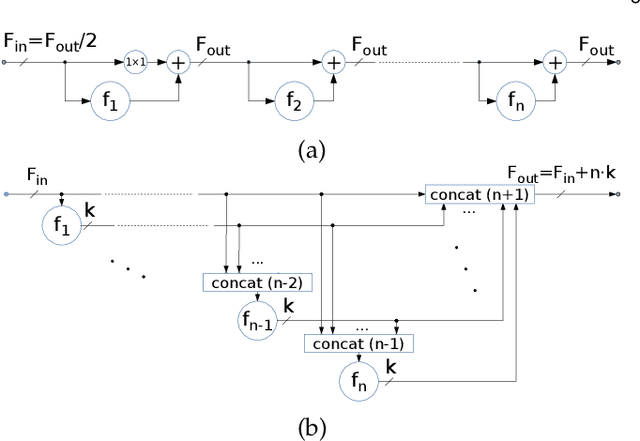
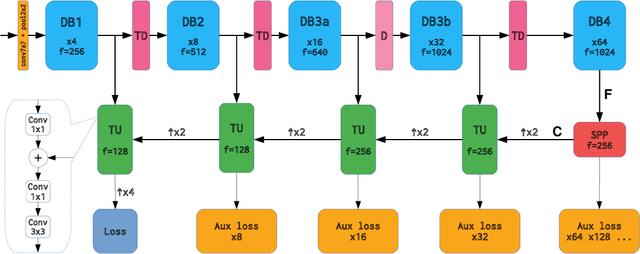
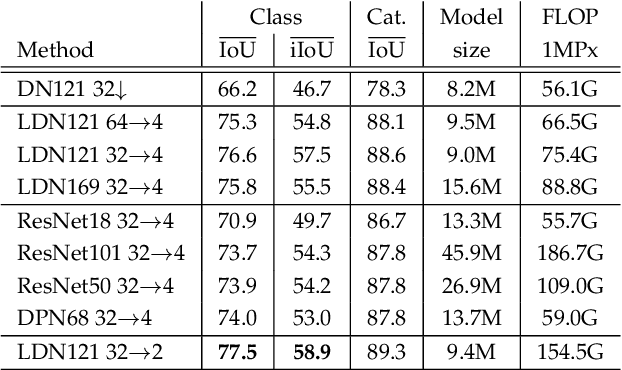
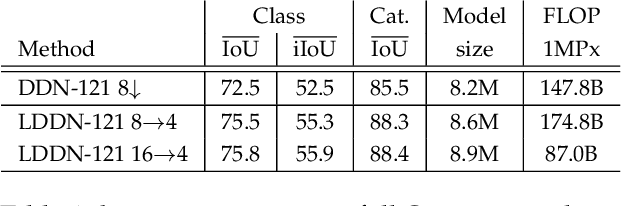
Recent progress of deep image classification models has provided great potential to improve state-of-the-art performance in related computer vision tasks. However, the transition to semantic segmentation is hampered by strict memory limitations of contemporary GPUs. The extent of feature map caching required by convolutional backprop poses significant challenges even for moderately sized Pascal images, while requiring careful architectural considerations when the source resolution is in the megapixel range. To address these concerns, we propose a novel DenseNet-based ladder-style architecture which features high modelling power and a very lean upsampling datapath. We also propose to substantially reduce the extent of feature map caching by exploiting inherent spatial efficiency of the DenseNet feature extractor. The resulting models deliver high performance with fewer parameters than competitive approaches, and allow training at megapixel resolution on commodity hardware. The presented experimental results outperform the state-of-the-art in terms of prediction accuracy and execution speed on Cityscapes, Pascal VOC 2012, CamVid and ROB 2018 datasets. Source code will be released upon publication.
In Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images
Apr 12, 2019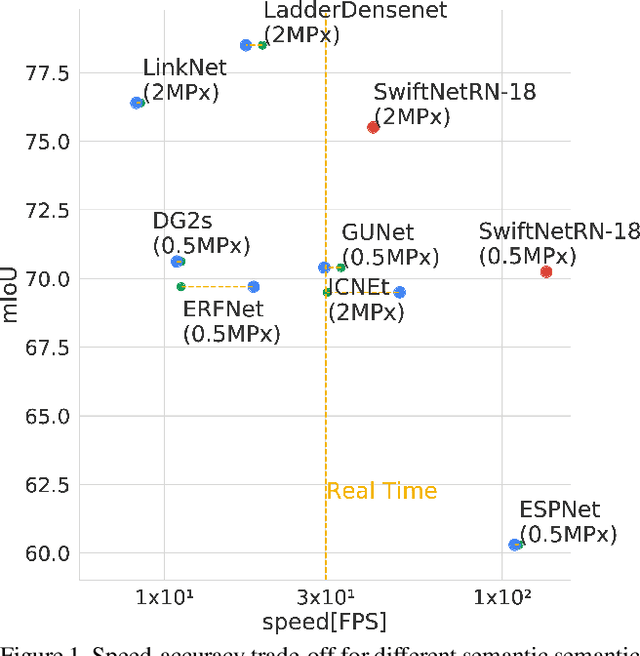
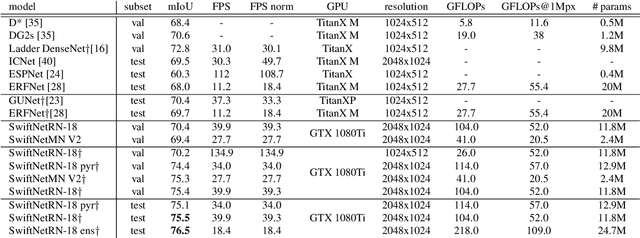
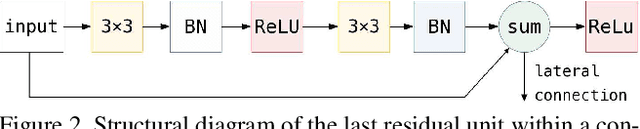
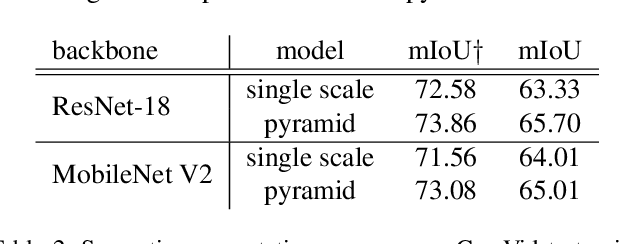
Recent success of semantic segmentation approaches on demanding road driving datasets has spurred interest in many related application fields. Many of these applications involve real-time prediction on mobile platforms such as cars, drones and various kinds of robots. Real-time setup is challenging due to extraordinary computational complexity involved. Many previous works address the challenge with custom lightweight architectures which decrease computational complexity by reducing depth, width and layer capacity with respect to general purpose architectures. We propose an alternative approach which achieves a significantly better performance across a wide range of computing budgets. First, we rely on a light-weight general purpose architecture as the main recognition engine. Then, we leverage light-weight upsampling with lateral connections as the most cost-effective solution to restore the prediction resolution. Finally, we propose to enlarge the receptive field by fusing shared features at multiple resolutions in a novel fashion. Experiments on several road driving datasets show a substantial advantage of the proposed approach, either with ImageNet pre-trained parameters or when we learn from scratch. Our Cityscapes test submission entitled SwiftNetRN-18 delivers 75.5% MIoU and achieves 39.9 Hz on 1024x2048 images on GTX1080Ti.
Discriminative out-of-distribution detection for semantic segmentation
Oct 01, 2018
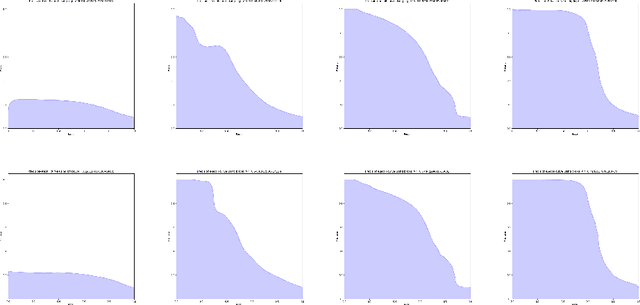


Most classification and segmentation datasets assume a closed-world scenario in which predictions are expressed as distribution over a predetermined set of visual classes. However, such assumption implies unavoidable and often unnoticeable failures in presence of out-of-distribution (OOD) input. These failures are bound to happen in most real-life applications since current visual ontologies are far from being comprehensive. We propose to address this issue by discriminative detection of OOD pixels in input data. Different from recent approaches, we avoid to bring any decisions by only observing the training dataset of the primary model trained to solve the desired computer vision task. Instead, we train a dedicated OOD model which discriminates the primary training set from a much larger "background" dataset which approximates the variety of the visual world. We perform our experiments on high resolution natural images in a dense prediction setup. We use several road driving datasets as our training distribution, while we approximate the background distribution with the ILSVRC dataset. We evaluate our approach on WildDash test, which is currently the only public test dataset that includes out-of-distribution images. The obtained results show that the proposed approach succeeds to identify out-of-distribution pixels while outperforming previous work by a wide margin.
Robust Semantic Segmentation with Ladder-DenseNet Models
Jun 09, 2018
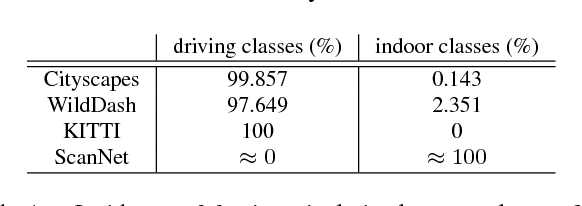


We present semantic segmentation experiments with a model capable to perform predictions on four benchmark datasets: Cityscapes, ScanNet, WildDash and KITTI. We employ a ladder-style convolutional architecture featuring a modified DenseNet-169 model in the downsampling datapath, and only one convolution in each stage of the upsampling datapath. Due to limited computing resources, we perform the training only on Cityscapes Fine train+val, ScanNet train, WildDash val and KITTI train. We evaluate the trained model on the test subsets of the four benchmarks in concordance with the guidelines of the Robust Vision Challenge ROB 2018. The performed experiments reveal several interesting findings which we describe and discuss.
A Novel Georeferenced Dataset for Stereo Visual Odometry
Oct 01, 2013
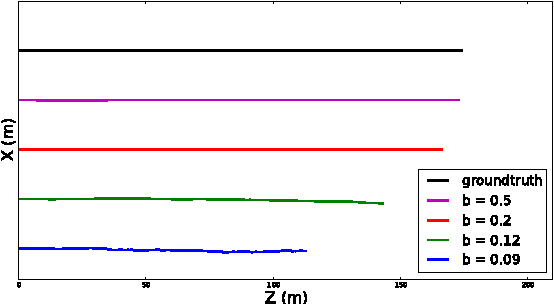
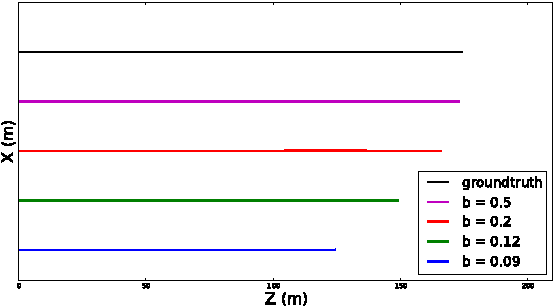
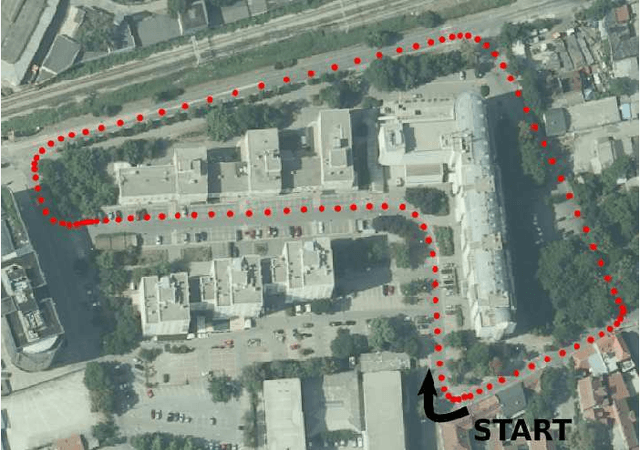
In this work, we present a novel dataset for assessing the accuracy of stereo visual odometry. The dataset has been acquired by a small-baseline stereo rig mounted on the top of a moving car. The groundtruth is supplied by a consumer grade GPS device without IMU. Synchronization and alignment between GPS readings and stereo frames are recovered after the acquisition. We show that the attained groundtruth accuracy allows to draw useful conclusions in practice. The presented experiments address influence of camera calibration, baseline distance and zero-disparity features to the achieved reconstruction performance.