 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Holds Back Open-Vocabulary Segmentation?
Aug 06, 2025Standard segmentation setups are unable to deliver models that can recognize concepts outside the training taxonomy. Open-vocabulary approaches promise to close this gap through language-image pretraining on billions of image-caption pairs. Unfortunately, we observe that the promise is not delivered due to several bottlenecks that have caused the performance to plateau for almost two years. This paper proposes novel oracle components that identify and decouple these bottlenecks by taking advantage of the groundtruth information. The presented validation experiments deliver important empirical findings that provide a deeper insight into the failures of open-vocabulary models and suggest prominent approaches to unlock the future research.
A Survey on Training-free Open-Vocabulary Semantic Segmentation
May 28, 2025Semantic segmentation is one of the most fundamental tasks in image understanding with a long history of research, and subsequently a myriad of different approaches. Traditional methods strive to train models up from scratch, requiring vast amounts of computational resources and training data. In the advent of moving to open-vocabulary semantic segmentation, which asks models to classify beyond learned categories, large quantities of finely annotated data would be prohibitively expensive. Researchers have instead turned to training-free methods where they leverage existing models made for tasks where data is more easily acquired. Specifically, this survey will cover the history, nuance, idea development and the state-of-the-art in training-free open-vocabulary semantic segmentation that leverages existing multi-modal classification models. We will first give a preliminary on the task definition followed by an overview of popular model archetypes and then spotlight over 30 approaches split into broader research branches: purely CLIP-based, those leveraging auxiliary visual foundation models and ones relying on generative methods. Subsequently, we will discuss the limitations and potential problems of current research, as well as provide some underexplored ideas for future study. We believe this survey will serve as a good onboarding read to new researchers and spark increased interest in the area.
Seal Your Backdoor with Variational Defense
Mar 11, 2025We propose VIBE, a model-agnostic framework that trains classifiers resilient to backdoor attacks. The key concept behind our approach is to treat malicious inputs and corrupted labels from the training dataset as observed random variables, while the actual clean labels are latent. VIBE then recovers the corresponding latent clean label posterior through variational inference. The resulting training procedure follows the expectation-maximization (EM) algorithm. The E-step infers the clean pseudolabels by solving an entropy-regularized optimal transport problem, while the M-step updates the classifier parameters via gradient descent. Being modular, VIBE can seamlessly integrate with recent advancements in self-supervised representation learning, which enhance its ability to resist backdoor attacks. We experimentally validate the method effectiveness against contemporary backdoor attacks on standard datasets, a large-scale setup with 1$k$ classes, and a dataset poisoned with multiple attacks. VIBE consistently outperforms previous defenses across all tested scenarios.
Backdoor Defense through Self-Supervised and Generative Learning
Sep 02, 2024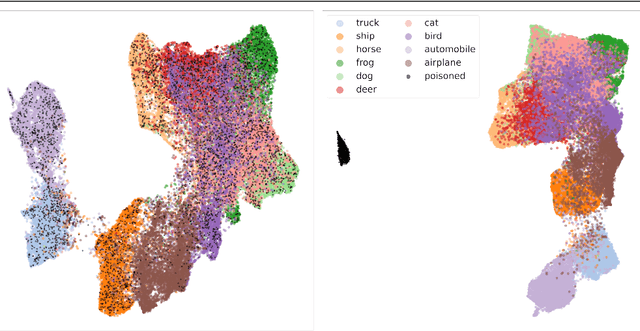



Backdoor attacks change a small portion of training data by introducing hand-crafted triggers and rewiring the corresponding labels towards a desired target class. Training on such data injects a backdoor which causes malicious inference in selected test samples. Most defenses mitigate such attacks through various modifications of the discriminative learning procedure. In contrast, this paper explores an approach based on generative modelling of per-class distributions in a self-supervised representation space. Interestingly, these representations get either preserved or heavily disturbed under recent backdoor attacks. In both cases, we find that per-class generative models allow to detect poisoned data and cleanse the dataset. Experiments show that training on cleansed dataset greatly reduces the attack success rate and retains the accuracy on benign inputs.
MC-PanDA: Mask Confidence for Panoptic Domain Adaptation
Jul 19, 2024Domain adaptive panoptic segmentation promises to resolve the long tail of corner cases in natural scene understanding. Previous state of the art addresses this problem with cross-task consistency, careful system-level optimization and heuristic improvement of teacher predictions. In contrast, we propose to build upon remarkable capability of mask transformers to estimate their own prediction uncertainty. Our method avoids noise amplification by leveraging fine-grained confidence of panoptic teacher predictions. In particular, we modulate the loss with mask-wide confidence and discourage back-propagation in pixels with uncertain teacher or confident student. Experimental evaluation on standard benchmarks reveals a substantial contribution of the proposed selection techniques. We report 47.4 PQ on Synthia to Cityscapes, which corresponds to an improvement of 6.2 percentage points over the state of the art. The source code is available at https://github.com/helen1c/MC-PanDA.
Outlier detection by ensembling uncertainty with negative objectness
Feb 23, 2024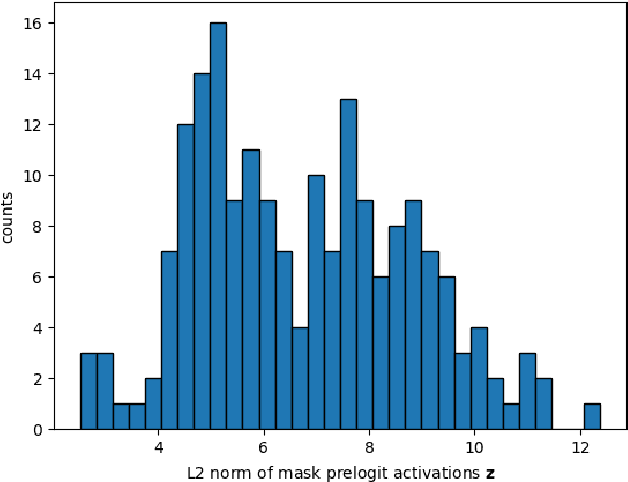



Outlier detection is an essential capability in safety-critical applications of supervised visual recognition. Most of the existing methods deliver best results by encouraging standard closed-set models to produce low-confidence predictions in negative training data. However, that approach conflates prediction uncertainty with recognition of the negative class. We therefore reconsider direct prediction of K+1 logits that correspond to K groundtruth classes and one outlier class. This setup allows us to formulate a novel anomaly score as an ensemble of in-distribution uncertainty and the posterior of the outlier class which we term negative objectness. Now outliers can be independently detected due to i) high prediction uncertainty or ii) similarity with negative data. We embed our method into a dense prediction architecture with mask-level recognition over K+2 classes. The training procedure encourages the novel K+2-th class to learn negative objectness at pasted negative instances. Our models outperform the current state-of-the art on standard benchmarks for image-wide and pixel-level outlier detection with and without training on real negative data.
Real time dense anomaly detection by learning on synthetic negative data
May 24, 2023

Most approaches to dense anomaly detection rely on generative modeling or on discriminative methods that train with negative data. We consider a recent hybrid method that optimizes the same shared representation according to cross-entropy of the discriminative predictions, and negative log likelihood of the predicted energy-based density. We extend that work with a jointly trained generative flow that samples synthetic negatives at the border of the inlier distribution. The proposed extension provides potential to learn the hybrid method without real negative data. Our experiments analyze the impact of training with synthetic negative data and validate contribution of the energy-based density during training and evaluation.
Identifying Label Errors in Object Detection Datasets by Loss Inspection
Mar 13, 2023
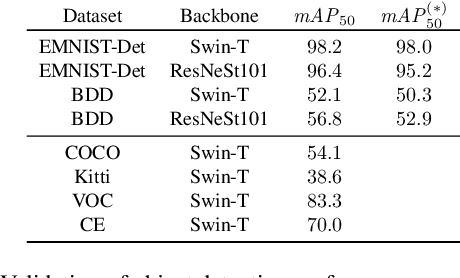
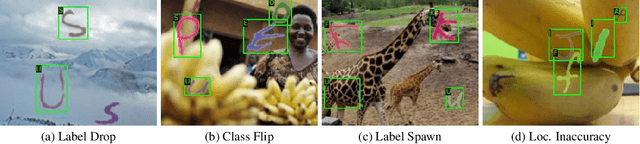
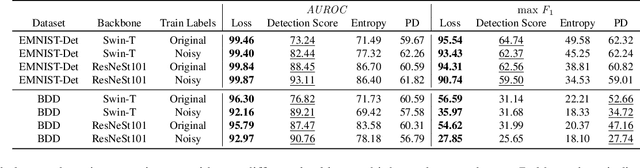
Labeling datasets for supervised object detection is a dull and time-consuming task. Errors can be easily introduced during annotation and overlooked during review, yielding inaccurate benchmarks and performance degradation of deep neural networks trained on noisy labels. In this work, we for the first time introduce a benchmark for label error detection methods on object detection datasets as well as a label error detection method and a number of baselines. We simulate four different types of randomly introduced label errors on train and test sets of well-labeled object detection datasets. For our label error detection method we assume a two-stage object detector to be given and consider the sum of both stages' classification and regression losses. The losses are computed with respect to the predictions and the noisy labels including simulated label errors, aiming at detecting the latter. We compare our method to three baselines: a naive one without deep learning, the object detector's score and the entropy of the classification softmax distribution. We outperform all baselines and demonstrate that among the considered methods, ours is the only one that detects label errors of all four types efficiently. Furthermore, we detect real label errors a) on commonly used test datasets in object detection and b) on a proprietary dataset. In both cases we achieve low false positives rates, i.e., when considering 200 proposals from our method, we detect label errors with a precision for a) of up to 71.5% and for b) with 97%.
Normalizing Flow based Feature Synthesis for Outlier-Aware Object Detection
Feb 01, 2023



Real-world deployment of reliable object detectors is crucial for applications such as autonomous driving. However, general-purpose object detectors like Faster R-CNN are prone to providing overconfident predictions for outlier objects. Recent outlier-aware object detection approaches estimate the density of instance-wide features with class-conditional Gaussians and train on synthesized outlier features from their low-likelihood regions. However, this strategy does not guarantee that the synthesized outlier features will have a low likelihood according to the other class-conditional Gaussians. We propose a novel outlier-aware object detection framework that learns to distinguish outliers from inlier objects by learning the joint data distribution of all inlier classes with an invertible normalizing flow. The flow model ensures that the synthesized outliers have a lower likelihood than inliers of all object classes, thereby modeling a better decision boundary between inlier and outlier objects. Our approach significantly outperforms the state-of-the-art for outlier-aware object detection on both image and video datasets.
Hybrid Open-set Segmentation with Synthetic Negative Data
Jan 19, 2023

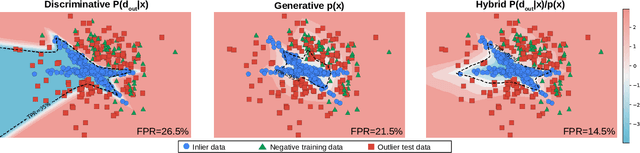

Open-set segmentation is often conceived by complementing closed-set classification with anomaly detection. Existing dense anomaly detectors operate either through generative modelling of regular training data or by discriminating with respect to negative training data. These two approaches optimize different objectives and therefore exhibit different failure modes. Consequently, we propose the first dense hybrid anomaly score that fuses generative and discriminative cues. The proposed score can be efficiently implemented by upgrading any semantic segmentation model with translation-equivariant estimates of data likelihood and dataset posterior. Our design is a remarkably good fit for efficient inference on large images due to negligible computational overhead over the closed-set baseline. The resulting dense hybrid open-set models require negative training images that can be sampled either from an auxiliary negative dataset or from a jointly trained generative model. We evaluate our contributions on benchmarks for dense anomaly detection and open-set segmentation of traffic scenes. The experiments reveal strong open-set performance in spite of negligible computational overhead.