 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA redescription mining framework for post-hoc explaining and relating deep learning models
Jan 02, 2025



Deep learning models (DLMs) achieve increasingly high performance both on structured and unstructured data. They significantly extended applicability of machine learning to various domains. Their success in making predictions, detecting patterns and generating new data made significant impact on science and industry. Despite these accomplishments, DLMs are difficult to explain because of their enormous size. In this work, we propose a novel framework for post-hoc explaining and relating DLMs using redescriptions. The framework allows cohort analysis of arbitrary DLMs by identifying statistically significant redescriptions of neuron activations. It allows coupling neurons to a set of target labels or sets of descriptive attributes, relating layers within a single DLM or associating different DLMs. The proposed framework is independent of the artificial neural network architecture and can work with more complex target labels (e.g. multi-label or multi-target scenario). Additionally, it can emulate both pedagogical and decompositional approach to rule extraction. The aforementioned properties of the proposed framework can increase explainability and interpretability of arbitrary DLMs by providing different information compared to existing explainable-AI approaches.
Backdoor Defense through Self-Supervised and Generative Learning
Sep 02, 2024Backdoor attacks change a small portion of training data by introducing hand-crafted triggers and rewiring the corresponding labels towards a desired target class. Training on such data injects a backdoor which causes malicious inference in selected test samples. Most defenses mitigate such attacks through various modifications of the discriminative learning procedure. In contrast, this paper explores an approach based on generative modelling of per-class distributions in a self-supervised representation space. Interestingly, these representations get either preserved or heavily disturbed under recent backdoor attacks. In both cases, we find that per-class generative models allow to detect poisoned data and cleanse the dataset. Experiments show that training on cleansed dataset greatly reduces the attack success rate and retains the accuracy on benign inputs.
Weakly supervised training of universal visual concepts for multi-domain semantic segmentation
Dec 20, 2022Deep supervised models have an unprecedented capacity to absorb large quantities of training data. Hence, training on multiple datasets becomes a method of choice towards strong generalization in usual scenes and graceful performance degradation in edge cases. Unfortunately, different datasets often have incompatible labels. For instance, the Cityscapes road class subsumes all driving surfaces, while Vistas defines separate classes for road markings, manholes etc. Furthermore, many datasets have overlapping labels. For instance, pickups are labeled as trucks in VIPER, cars in Vistas, and vans in ADE20k. We address this challenge by considering labels as unions of universal visual concepts. This allows seamless and principled learning on multi-domain dataset collections without requiring any relabeling effort. Our method achieves competitive within-dataset and cross-dataset generalization, as well as ability to learn visual concepts which are not separately labeled in any of the training datasets. Experiments reveal competitive or state-of-the-art performance on two multi-domain dataset collections and on the WildDash 2 benchmark.
IRB-NLP at SemEval-2022 Task 1: Exploring the Relationship Between Words and Their Semantic Representations
May 13, 2022
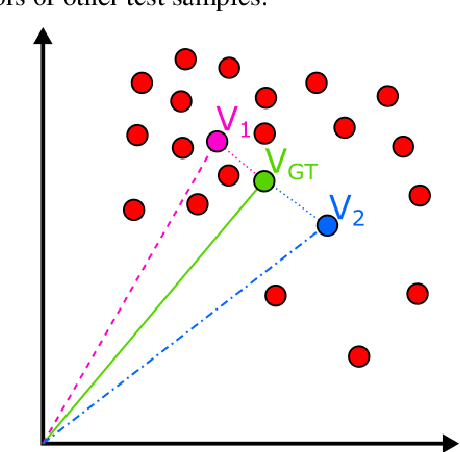

What is the relation between a word and its description, or a word and its embedding? Both descriptions and embeddings are semantic representations of words. But, what information from the original word remains in these representations? Or more importantly, which information about a word do these two representations share? Definition Modeling and Reverse Dictionary are two opposite learning tasks that address these questions. The goal of the Definition Modeling task is to investigate the power of information laying inside a word embedding to express the meaning of the word in a humanly understandable way -- as a dictionary definition. Conversely, the Reverse Dictionary task explores the ability to predict word embeddings directly from its definition. In this paper, by tackling these two tasks, we are exploring the relationship between words and their semantic representations. We present our findings based on the descriptive, exploratory, and predictive data analysis conducted on the CODWOE dataset. We give a detailed overview of the systems that we designed for Definition Modeling and Reverse Dictionary tasks, and that achieved top scores on SemEval-2022 CODWOE challenge in several subtasks. We hope that our experimental results concerning the predictive models and the data analyses we provide will prove useful in future explorations of word representations and their relationships.
Multi-domain semantic segmentation with overlapping labels
Aug 25, 2021

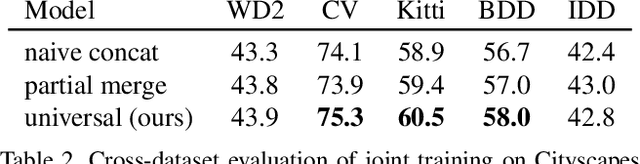

Deep supervised models have an unprecedented capacity to absorb large quantities of training data. Hence, training on many datasets becomes a method of choice towards graceful degradation in unusual scenes. Unfortunately, different datasets often use incompatible labels. For instance, the Cityscapes road class subsumes all driving surfaces, while Vistas defines separate classes for road markings, manholes etc. We address this challenge by proposing a principled method for seamless learning on datasets with overlapping classes based on partial labels and probabilistic loss. Our method achieves competitive within-dataset and cross-dataset generalization, as well as ability to learn visual concepts which are not separately labeled in any of the training datasets. Experiments reveal competitive or state-of-the-art performance on two multi-domain dataset collections and on the WildDash 2 benchmark.
A baseline for semi-supervised learning of efficient semantic segmentation models
Jun 15, 2021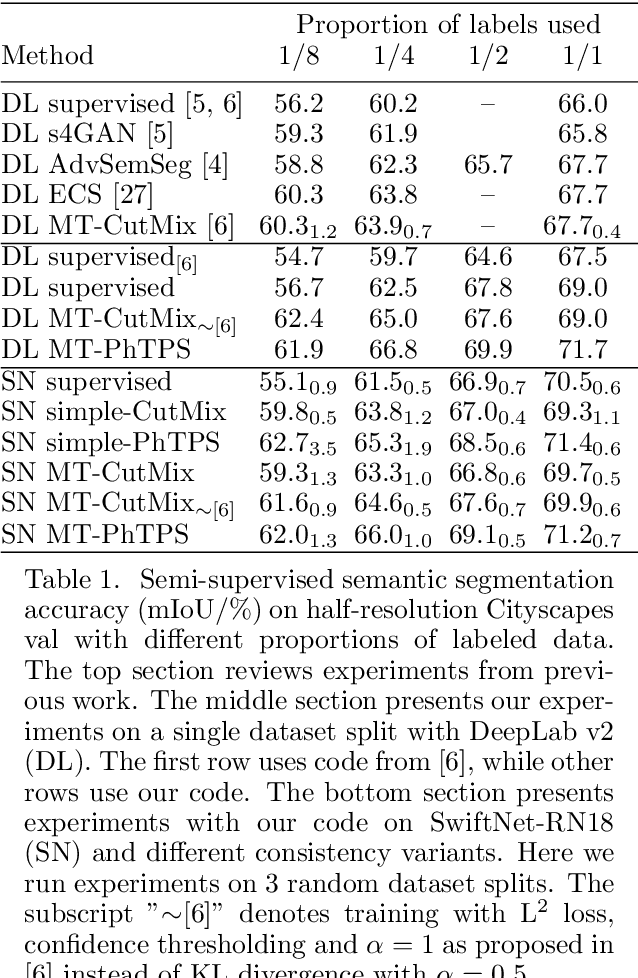

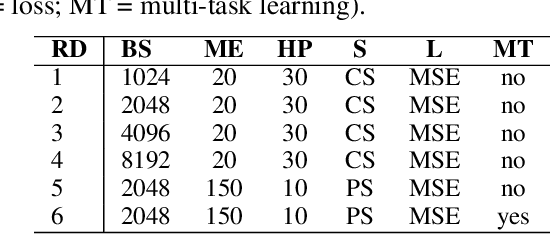
Semi-supervised learning is especially interesting in the dense prediction context due to high cost of pixel-level ground truth. Unfortunately, most such approaches are evaluated on outdated architectures which hamper research due to very slow training and high requirements on GPU RAM. We address this concern by presenting a simple and effective baseline which works very well both on standard and efficient architectures. Our baseline is based on one-way consistency and non-linear geometric and photometric perturbations. We show advantage of perturbing only the student branch and present a plausible explanation of such behaviour. Experiments on Cityscapes and CIFAR-10 demonstrate competitive performance with respect to prior work.
Densely connected normalizing flows
Jun 08, 2021


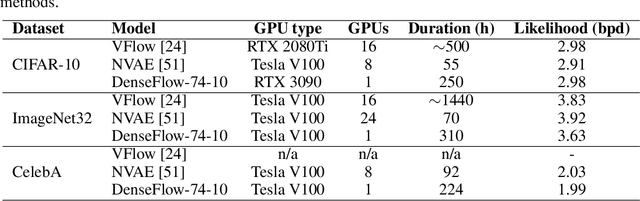
Normalizing flows are bijective mappings between inputs and latent representations with a fully factorized distribution. They are very attractive due to exact likelihood evaluation and efficient sampling. However, their effective capacity is often insufficient since the bijectivity constraint limits the model width. We address this issue by incrementally padding intermediate representations with noise. We precondition the noise in accordance with previous invertible units, which we describe as cross-unit coupling. Our invertible glow-like modules express intra-unit affine coupling as a fusion of a densely connected block and Nystr\"om self-attention. We refer to our architecture as DenseFlow since both cross-unit and intra-unit couplings rely on dense connectivity. Experiments show significant improvements due to the proposed contributions, and reveal state-of-the-art density estimation among all generative models under moderate computing budgets.
Multi-domain semantic segmentation with pyramidal fusion
Sep 16, 2020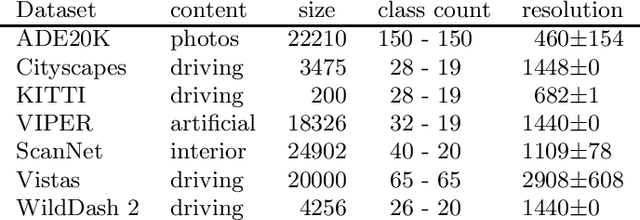
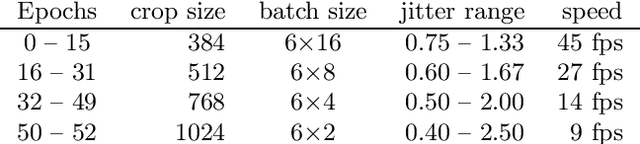

We present our submission to the semantic segmentation contest of the Robust Vision Challenge held at ECCV 2020. The contest requires submitting the same model to seven benchmarks from three different domains. Our approach is based on the SwiftNet architecture with pyramidal fusion. We address inconsistent taxonomies with a single-level 193-dimensional softmax output. We strive to train with large batches in order to stabilize optimization of a hard recognition problem, and to favour smooth evolution of batchnorm statistics. We achieve this by implementing a custom backward step through log-sum-prob loss, and by using small crops before freezing the population statistics. Our model ranks first on the RVC semantic segmentation challenge as well as on the WildDash 2 leaderboard. This suggests that pyramidal fusion is competitive not only for efficient inference with lightweight backbones, but also in large-scale setups for multi-domain application.