 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeal Your Backdoor with Variational Defense
Mar 11, 2025We propose VIBE, a model-agnostic framework that trains classifiers resilient to backdoor attacks. The key concept behind our approach is to treat malicious inputs and corrupted labels from the training dataset as observed random variables, while the actual clean labels are latent. VIBE then recovers the corresponding latent clean label posterior through variational inference. The resulting training procedure follows the expectation-maximization (EM) algorithm. The E-step infers the clean pseudolabels by solving an entropy-regularized optimal transport problem, while the M-step updates the classifier parameters via gradient descent. Being modular, VIBE can seamlessly integrate with recent advancements in self-supervised representation learning, which enhance its ability to resist backdoor attacks. We experimentally validate the method effectiveness against contemporary backdoor attacks on standard datasets, a large-scale setup with 1$k$ classes, and a dataset poisoned with multiple attacks. VIBE consistently outperforms previous defenses across all tested scenarios.
Fine-grained Classes and How to Find Them
Jun 16, 2024



In many practical applications, coarse-grained labels are readily available compared to fine-grained labels that reflect subtle differences between classes. However, existing methods cannot leverage coarse labels to infer fine-grained labels in an unsupervised manner. To bridge this gap, we propose FALCON, a method that discovers fine-grained classes from coarsely labeled data without any supervision at the fine-grained level. FALCON simultaneously infers unknown fine-grained classes and underlying relationships between coarse and fine-grained classes. Moreover, FALCON is a modular method that can effectively learn from multiple datasets labeled with different strategies. We evaluate FALCON on eight image classification tasks and a single-cell classification task. FALCON outperforms baselines by a large margin, achieving 22% improvement over the best baseline on the tieredImageNet dataset with over 600 fine-grained classes.
Outlier detection by ensembling uncertainty with negative objectness
Feb 23, 2024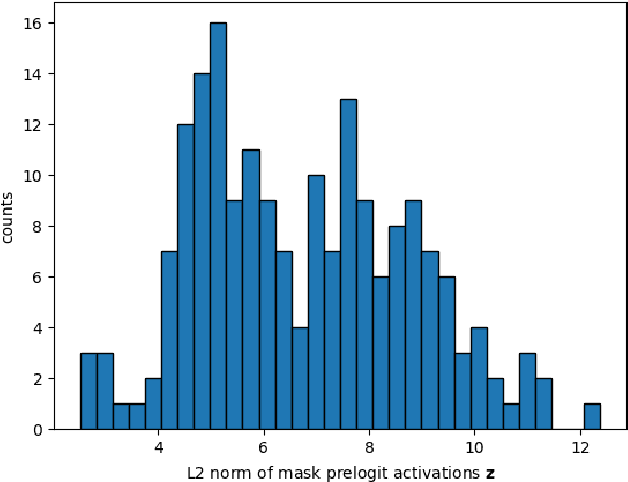



Outlier detection is an essential capability in safety-critical applications of supervised visual recognition. Most of the existing methods deliver best results by encouraging standard closed-set models to produce low-confidence predictions in negative training data. However, that approach conflates prediction uncertainty with recognition of the negative class. We therefore reconsider direct prediction of K+1 logits that correspond to K groundtruth classes and one outlier class. This setup allows us to formulate a novel anomaly score as an ensemble of in-distribution uncertainty and the posterior of the outlier class which we term negative objectness. Now outliers can be independently detected due to i) high prediction uncertainty or ii) similarity with negative data. We embed our method into a dense prediction architecture with mask-level recognition over K+2 classes. The training procedure encourages the novel K+2-th class to learn negative objectness at pasted negative instances. Our models outperform the current state-of-the art on standard benchmarks for image-wide and pixel-level outlier detection with and without training on real negative data.
Real time dense anomaly detection by learning on synthetic negative data
May 24, 2023

Most approaches to dense anomaly detection rely on generative modeling or on discriminative methods that train with negative data. We consider a recent hybrid method that optimizes the same shared representation according to cross-entropy of the discriminative predictions, and negative log likelihood of the predicted energy-based density. We extend that work with a jointly trained generative flow that samples synthetic negatives at the border of the inlier distribution. The proposed extension provides potential to learn the hybrid method without real negative data. Our experiments analyze the impact of training with synthetic negative data and validate contribution of the energy-based density during training and evaluation.
Hybrid Open-set Segmentation with Synthetic Negative Data
Jan 19, 2023

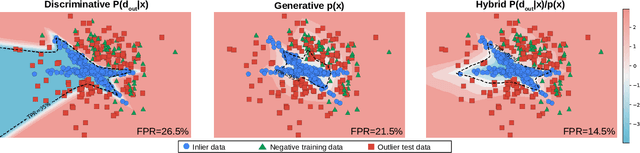

Open-set segmentation is often conceived by complementing closed-set classification with anomaly detection. Existing dense anomaly detectors operate either through generative modelling of regular training data or by discriminating with respect to negative training data. These two approaches optimize different objectives and therefore exhibit different failure modes. Consequently, we propose the first dense hybrid anomaly score that fuses generative and discriminative cues. The proposed score can be efficiently implemented by upgrading any semantic segmentation model with translation-equivariant estimates of data likelihood and dataset posterior. Our design is a remarkably good fit for efficient inference on large images due to negligible computational overhead over the closed-set baseline. The resulting dense hybrid open-set models require negative training images that can be sampled either from an auxiliary negative dataset or from a jointly trained generative model. We evaluate our contributions on benchmarks for dense anomaly detection and open-set segmentation of traffic scenes. The experiments reveal strong open-set performance in spite of negligible computational overhead.
On advantages of Mask-level Recognition for Open-set Segmentation in the Wild
Jan 09, 2023Most dense recognition methods bring a separate decision in each particular pixel. This approach still delivers competitive performance in usual closed-set setups with small taxonomies. However, important applications in the wild typically require strong open-set performance and large numbers of known classes. We show that these two demanding setups greatly benefit from mask-level predictions, even in the case of non-finetuned baseline models. Moreover, we propose an alternative formulation of dense recognition uncertainty that effectively reduces false positive responses at semantic borders. The proposed formulation produces a further improvement over a very strong baseline and sets the new state of the art in dense anomaly detection without training on negative data. Our contributions also lead to a performance improvement in a recent open-set panoptic setup. In-depth experiments confirm that our approach succeeds due to implicit aggregation of pixel-level cues into mask-level predictions.
DenseHybrid: Hybrid Anomaly Detection for Dense Open-set Recognition
Jul 06, 2022



Anomaly detection can be conceived either through generative modelling of regular training data or by discriminating with respect to negative training data. These two approaches exhibit different failure modes. Consequently, hybrid algorithms present an attractive research goal. Unfortunately, dense anomaly detection requires translational equivariance and very large input resolutions. These requirements disqualify all previous hybrid approaches to the best of our knowledge. We therefore design a novel hybrid algorithm based on reinterpreting discriminative logits as a logarithm of the unnormalized joint distribution $\hat{p}(\mathbf{x}, \mathbf{y})$. Our model builds on a shared convolutional representation from which we recover three dense predictions: i) the closed-set class posterior $P(\mathbf{y}|\mathbf{x})$, ii) the dataset posterior $P(d_{in}|\mathbf{x})$, iii) unnormalized data likelihood $\hat{p}(\mathbf{x})$. The latter two predictions are trained both on the standard training data and on a generic negative dataset. We blend these two predictions into a hybrid anomaly score which allows dense open-set recognition on large natural images. We carefully design a custom loss for the data likelihood in order to avoid backpropagation through the untractable normalizing constant $Z(\theta)$. Experiments evaluate our contributions on standard dense anomaly detection benchmarks as well as in terms of open-mIoU - a novel metric for dense open-set performance. Our submissions achieve state-of-the-art performance despite neglectable computational overhead over the standard semantic segmentation baseline.
Dense anomaly detection by robust learning on synthetic negative data
Dec 31, 2021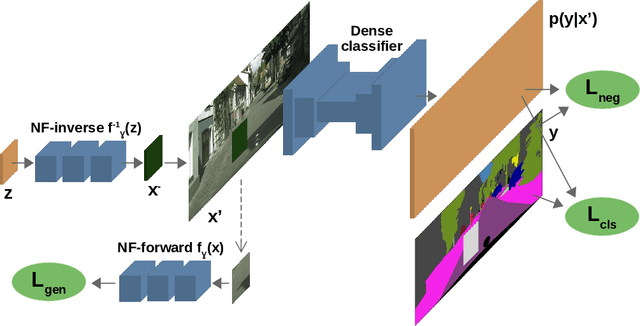


Standard machine learning is unable to accommodate inputs which do not belong to the training distribution. The resulting models often give rise to confident incorrect predictions which may lead to devastating consequences. This problem is especially demanding in the context of dense prediction since input images may be partially anomalous. Previous work has addressed dense anomaly detection by discriminative training on mixed-content images. We extend this approach with synthetic negative patches which simultaneously achieve high inlier likelihood and uniform discriminative prediction. We generate synthetic negatives with normalizing flows due to their outstanding distribution coverage and capability to generate samples at different resolutions. We also propose to detect anomalies according to a principled information-theoretic criterion which can be consistently applied through training and inference. The resulting models set the new state of the art on standard benchmarks and datasets in spite of minimal computational overhead and refraining from auxiliary negative data.
Densely connected normalizing flows
Jun 08, 2021


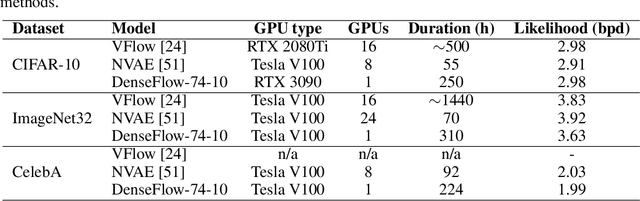
Normalizing flows are bijective mappings between inputs and latent representations with a fully factorized distribution. They are very attractive due to exact likelihood evaluation and efficient sampling. However, their effective capacity is often insufficient since the bijectivity constraint limits the model width. We address this issue by incrementally padding intermediate representations with noise. We precondition the noise in accordance with previous invertible units, which we describe as cross-unit coupling. Our invertible glow-like modules express intra-unit affine coupling as a fusion of a densely connected block and Nystr\"om self-attention. We refer to our architecture as DenseFlow since both cross-unit and intra-unit couplings rely on dense connectivity. Experiments show significant improvements due to the proposed contributions, and reveal state-of-the-art density estimation among all generative models under moderate computing budgets.
Dense open-set recognition with synthetic outliers generated by Real NVP
Nov 22, 2020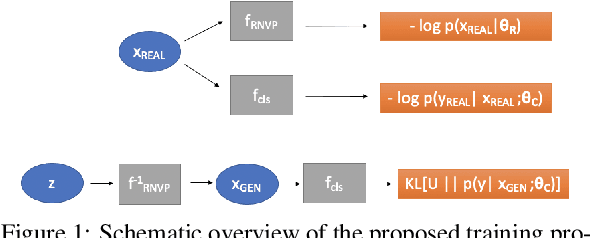

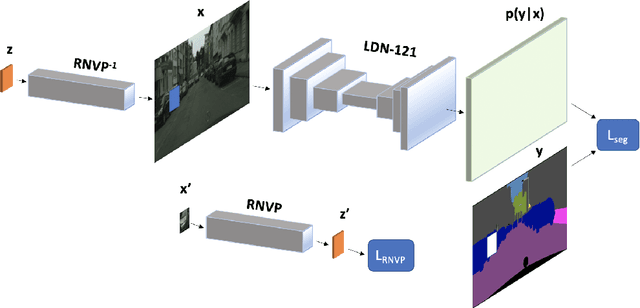

Today's deep models are often unable to detect inputs which do not belong to the training distribution. This gives rise to confident incorrect predictions which could lead to devastating consequences in many important application fields such as healthcare and autonomous driving. Interestingly, both discriminative and generative models appear to be equally affected. Consequently, this vulnerability represents an important research challenge. We consider an outlier detection approach based on discriminative training with jointly learned synthetic outliers. We obtain the synthetic outliers by sampling an RNVP model which is jointly trained to generate datapoints at the border of the training distribution. We show that this approach can be adapted for simultaneous semantic segmentation and dense outlier detection. We present image classification experiments on CIFAR-10, as well as semantic segmentation experiments on three existing datasets (StreetHazards, WD-Pascal, Fishyscapes Lost & Found), and one contributed dataset. Our models perform competitively with respect to the state of the art despite producing predictions with only one forward pass.