 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Platonic Representation Hypothesis: An Aristotelian View
Feb 16, 2026The Platonic Representation Hypothesis suggests that representations from neural networks are converging to a common statistical model of reality. We show that the existing metrics used to measure representational similarity are confounded by network scale: increasing model depth or width can systematically inflate representational similarity scores. To correct these effects, we introduce a permutation-based null-calibration framework that transforms any representational similarity metric into a calibrated score with statistical guarantees. We revisit the Platonic Representation Hypothesis with our calibration framework, which reveals a nuanced picture: the apparent convergence reported by global spectral measures largely disappears after calibration, while local neighborhood similarity, but not local distances, retains significant agreement across different modalities. Based on these findings, we propose the Aristotelian Representation Hypothesis: representations in neural networks are converging to shared local neighborhood relationships.
HeurekaBench: A Benchmarking Framework for AI Co-scientist
Jan 04, 2026LLM-based reasoning models have enabled the development of agentic systems that act as co-scientists, assisting in multi-step scientific analysis. However, evaluating these systems is challenging, as it requires realistic, end-to-end research scenarios that integrate data analysis, interpretation, and the generation of new insights from the experimental data. To address this limitation, we introduce HeurekaBench, a framework to create benchmarks with exploratory, open-ended research questions for experimental datasets. Each such question is grounded in a scientific study and its corresponding code repository, and is created using a semi-automated pipeline that leverages multiple LLMs to extract insights and generate candidate workflows, which are then verified against reported findings. We instantiate the framework in single-cell biology to obtain sc-HeurekaBench benchmark and use it to compare state-of-the-art single-cell agents. We further showcase the benefits of our benchmark for quantitatively analyzing current design choices in agentic systems. We find that the addition of a critic module can improve ill-formed responses for open-source LLM-based agents by up to 22% and close the gap with their closed-source counterparts. Overall, HeurekaBench sets a path toward rigorous, end-to-end evaluation of scientific agents, grounding benchmark construction in real scientific workflows.
Fine-grained Classes and How to Find Them
Jun 16, 2024



In many practical applications, coarse-grained labels are readily available compared to fine-grained labels that reflect subtle differences between classes. However, existing methods cannot leverage coarse labels to infer fine-grained labels in an unsupervised manner. To bridge this gap, we propose FALCON, a method that discovers fine-grained classes from coarsely labeled data without any supervision at the fine-grained level. FALCON simultaneously infers unknown fine-grained classes and underlying relationships between coarse and fine-grained classes. Moreover, FALCON is a modular method that can effectively learn from multiple datasets labeled with different strategies. We evaluate FALCON on eight image classification tasks and a single-cell classification task. FALCON outperforms baselines by a large margin, achieving 22% improvement over the best baseline on the tieredImageNet dataset with over 600 fine-grained classes.
$\ell_0$-Motivated Low-Rank Sparse Subspace Clustering
Dec 17, 2018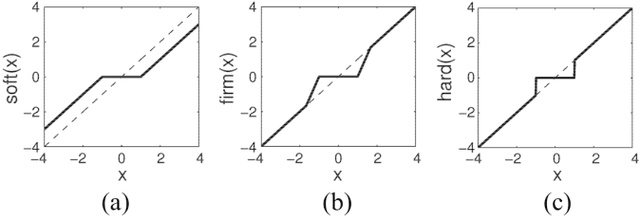
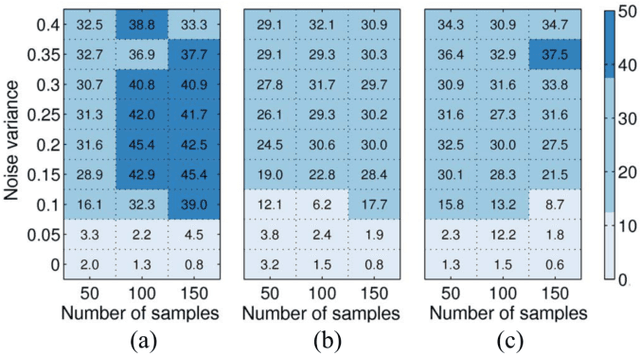
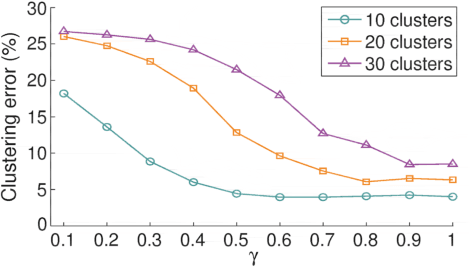

In many applications, high-dimensional data points can be well represented by low-dimensional subspaces. To identify the subspaces, it is important to capture a global and local structure of the data which is achieved by imposing low-rank and sparseness constraints on the data representation matrix. In low-rank sparse subspace clustering (LRSSC), nuclear and $\ell_1$ norms are used to measure rank and sparsity. However, the use of nuclear and $\ell_1$ norms leads to an overpenalized problem and only approximates the original problem. In this paper, we propose two $\ell_0$ quasi-norm based regularizations. First, the paper presents regularization based on multivariate generalization of minimax-concave penalty (GMC-LRSSC), which contains the global minimizers of $\ell_0$ quasi-norm regularized objective. Afterward, we introduce the Schatten-0 ($S_0$) and $\ell_0$ regularized objective and approximate the proximal map of the joint solution using a proximal average method ($S_0/\ell_0$-LRSSC). The resulting nonconvex optimization problems are solved using alternating direction method of multipliers with established convergence conditions of both algorithms. Results obtained on synthetic and four real-world datasets show the effectiveness of GMC-LRSSC and $S_0/\ell_0$-LRSSC when compared to state-of-the-art methods.