 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Objectness Bias and Region-to-Text Misalignment for Open-Vocabulary Panoptic Segmentation
Mar 22, 2026Open-vocabulary panoptic segmentation remains hindered by two coupled issues: (i) mask selection bias, where objectness heads trained on closed vocabularies suppress masks of categories not observed in training, and (ii) limited regional understanding in vision-language models such as CLIP, which were optimized for global image classification rather than localized segmentation. We introduce OVRCOAT, a simple, modular framework that tackles both. First, a CLIP-conditioned objectness adjustment (COAT) updates background/foreground probabilities, preserving high-quality masks for out-of-vocabulary objects. Second, an open-vocabulary mask-to-text refinement (OVR) strengthens CLIP's region-level alignment to improve classification of both seen and unseen classes with markedly lower memory cost than prior fine-tuning schemes. The two components combine to jointly improve objectness estimation and mask recognition, yielding consistent panoptic gains. Despite its simplicity, OVRCOAT sets a new state of the art on ADE20K (+5.5% PQ) and delivers clear gains on Mapillary Vistas and Cityscapes (+7.1% and +3% PQ, respectively). The code is available at: https://github.com/nickormushev/OVRCOAT
What Holds Back Open-Vocabulary Segmentation?
Aug 06, 2025Standard segmentation setups are unable to deliver models that can recognize concepts outside the training taxonomy. Open-vocabulary approaches promise to close this gap through language-image pretraining on billions of image-caption pairs. Unfortunately, we observe that the promise is not delivered due to several bottlenecks that have caused the performance to plateau for almost two years. This paper proposes novel oracle components that identify and decouple these bottlenecks by taking advantage of the groundtruth information. The presented validation experiments deliver important empirical findings that provide a deeper insight into the failures of open-vocabulary models and suggest prominent approaches to unlock the future research.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
MC-PanDA: Mask Confidence for Panoptic Domain Adaptation
Jul 19, 2024Domain adaptive panoptic segmentation promises to resolve the long tail of corner cases in natural scene understanding. Previous state of the art addresses this problem with cross-task consistency, careful system-level optimization and heuristic improvement of teacher predictions. In contrast, we propose to build upon remarkable capability of mask transformers to estimate their own prediction uncertainty. Our method avoids noise amplification by leveraging fine-grained confidence of panoptic teacher predictions. In particular, we modulate the loss with mask-wide confidence and discourage back-propagation in pixels with uncertain teacher or confident student. Experimental evaluation on standard benchmarks reveals a substantial contribution of the proposed selection techniques. We report 47.4 PQ on Synthia to Cityscapes, which corresponds to an improvement of 6.2 percentage points over the state of the art. The source code is available at https://github.com/helen1c/MC-PanDA.
On advantages of Mask-level Recognition for Open-set Segmentation in the Wild
Jan 09, 2023Most dense recognition methods bring a separate decision in each particular pixel. This approach still delivers competitive performance in usual closed-set setups with small taxonomies. However, important applications in the wild typically require strong open-set performance and large numbers of known classes. We show that these two demanding setups greatly benefit from mask-level predictions, even in the case of non-finetuned baseline models. Moreover, we propose an alternative formulation of dense recognition uncertainty that effectively reduces false positive responses at semantic borders. The proposed formulation produces a further improvement over a very strong baseline and sets the new state of the art in dense anomaly detection without training on negative data. Our contributions also lead to a performance improvement in a recent open-set panoptic setup. In-depth experiments confirm that our approach succeeds due to implicit aggregation of pixel-level cues into mask-level predictions.
Weakly supervised training of universal visual concepts for multi-domain semantic segmentation
Dec 20, 2022Deep supervised models have an unprecedented capacity to absorb large quantities of training data. Hence, training on multiple datasets becomes a method of choice towards strong generalization in usual scenes and graceful performance degradation in edge cases. Unfortunately, different datasets often have incompatible labels. For instance, the Cityscapes road class subsumes all driving surfaces, while Vistas defines separate classes for road markings, manholes etc. Furthermore, many datasets have overlapping labels. For instance, pickups are labeled as trucks in VIPER, cars in Vistas, and vans in ADE20k. We address this challenge by considering labels as unions of universal visual concepts. This allows seamless and principled learning on multi-domain dataset collections without requiring any relabeling effort. Our method achieves competitive within-dataset and cross-dataset generalization, as well as ability to learn visual concepts which are not separately labeled in any of the training datasets. Experiments reveal competitive or state-of-the-art performance on two multi-domain dataset collections and on the WildDash 2 benchmark.
Panoptic SwiftNet: Pyramidal Fusion for Real-time Panoptic Segmentation
Mar 15, 2022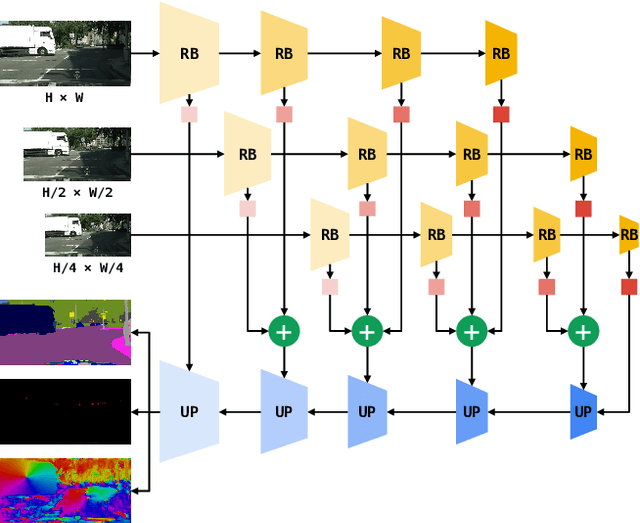
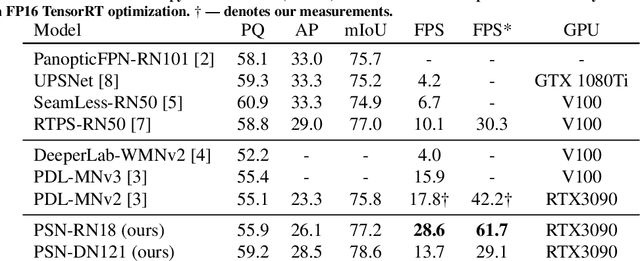

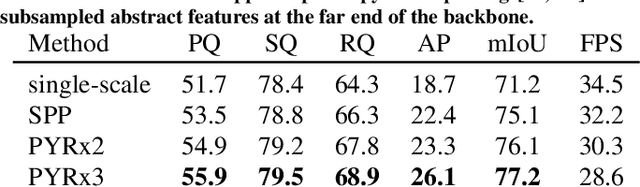
Dense panoptic prediction is a key ingredient in many existing applications such as autonomous driving, automated warehouses or agri-robotics. However, most of these applications leverage the recovered dense semantics as an input to visual closed-loop control. Hence, practical deployments require real-time inference over large input resolutions on embedded hardware. These requirements call for computationally efficient approaches which deliver high accuracy with limited computational resources. We propose to achieve this goal by trading-off backbone capacity for multi-scale feature extraction. In comparison with contemporaneous approaches to panoptic segmentation, the main novelties of our method are scale-equivariant feature extraction and cross-scale upsampling through pyramidal fusion. Our best model achieves 55.9% PQ on Cityscapes val at 60 FPS on full resolution 2MPx images and RTX3090 with FP16 Tensor RT optimization.
Multi-domain semantic segmentation with overlapping labels
Aug 25, 2021

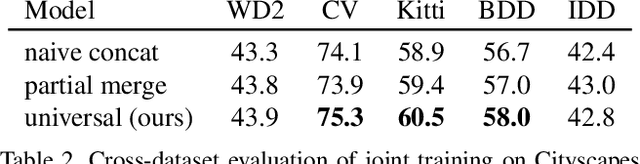

Deep supervised models have an unprecedented capacity to absorb large quantities of training data. Hence, training on many datasets becomes a method of choice towards graceful degradation in unusual scenes. Unfortunately, different datasets often use incompatible labels. For instance, the Cityscapes road class subsumes all driving surfaces, while Vistas defines separate classes for road markings, manholes etc. We address this challenge by proposing a principled method for seamless learning on datasets with overlapping classes based on partial labels and probabilistic loss. Our method achieves competitive within-dataset and cross-dataset generalization, as well as ability to learn visual concepts which are not separately labeled in any of the training datasets. Experiments reveal competitive or state-of-the-art performance on two multi-domain dataset collections and on the WildDash 2 benchmark.
Joint Forecasting of Features and Feature Motion for Dense Semantic Future Prediction
Jan 26, 2021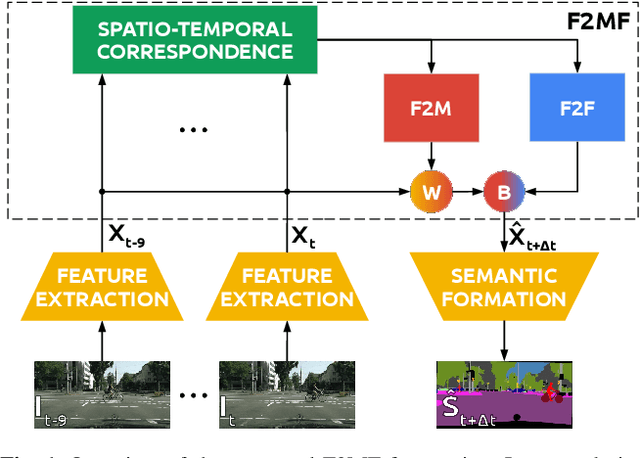
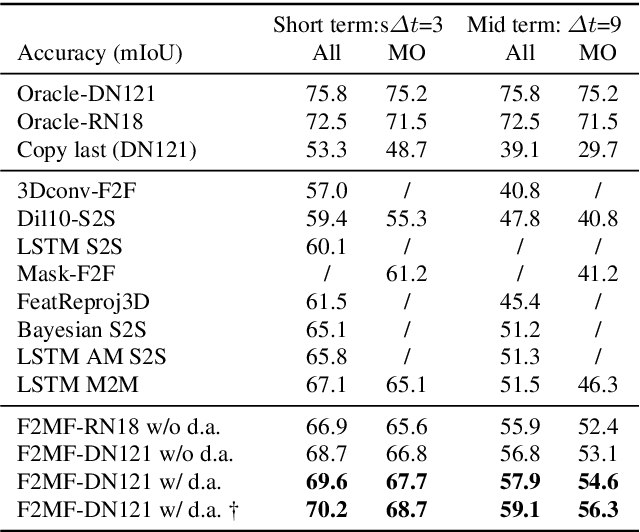
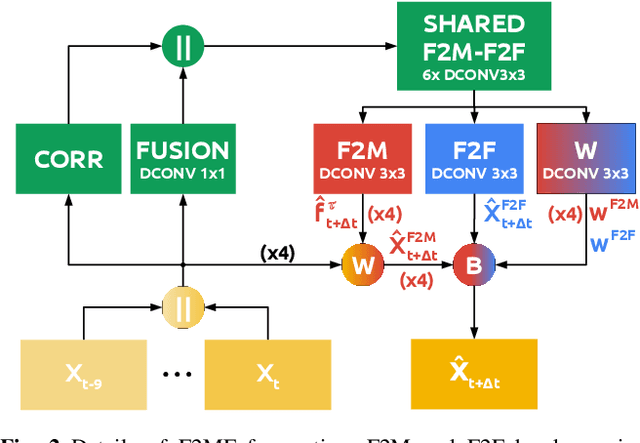

We present a novel dense semantic forecasting approach which is applicable to a variety of architectures and tasks. The approach consists of two modules. Feature-to-motion (F2M) module forecasts a dense deformation field which warps past features into their future positions. Feature-to-feature (F2F) module regresses the future features directly and is therefore able to account for emergent scenery. The compound F2MF approach decouples effects of motion from the effects of novelty in a task-agnostic manner. We aim to apply F2MF forecasting to the most subsampled and the most abstract representation of a desired single-frame model. Our implementations take advantage of deformable convolutions and pairwise correlation coefficients across neighbouring time instants. We perform experiments on three dense prediction tasks: semantic segmentation, instance-level segmentation, and panoptic segmentation. The results reveal state-of-the-art forecasting accuracy across all three modalities on the Cityscapes dataset.
Multimodal semantic forecasting based on conditional generation of future features
Oct 18, 2020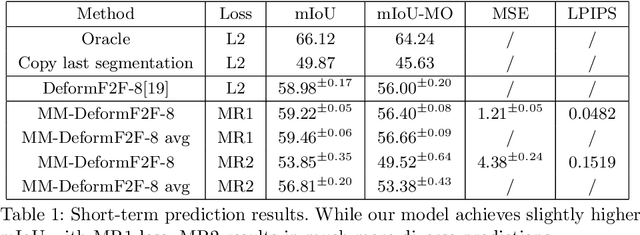

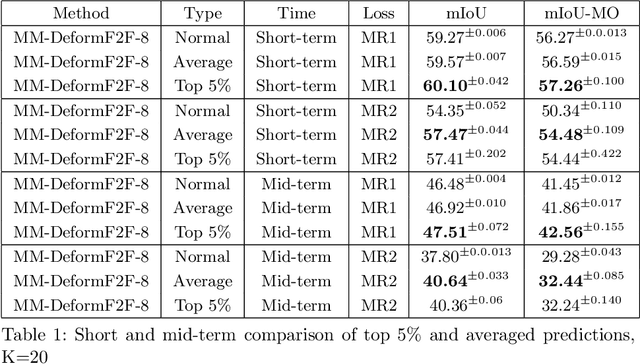
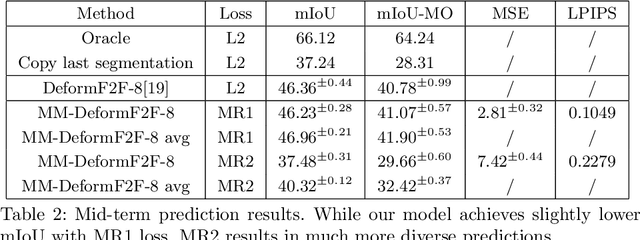
This paper considers semantic forecasting in road-driving scenes. Most existing approaches address this problem as deterministic regression of future features or future predictions given observed frames. However, such approaches ignore the fact that future can not always be guessed with certainty. For example, when a car is about to turn around a corner, the road which is currently occluded by buildings may turn out to be either free to drive, or occupied by people, other vehicles or roadworks. When a deterministic model confronts such situation, its best guess is to forecast the most likely outcome. However, this is not acceptable since it defeats the purpose of forecasting to improve security. It also throws away valuable training data, since a deterministic model is unable to learn any deviation from the norm. We address this problem by providing more freedom to the model through allowing it to forecast different futures. We propose to formulate multimodal forecasting as sampling of a multimodal generative model conditioned on the observed frames. Experiments on the Cityscapes dataset reveal that our multimodal model outperforms its deterministic counterpart in short-term forecasting while performing slightly worse in the mid-term case.