 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-based Event Stereo Visual Odometry
Jul 10, 2021

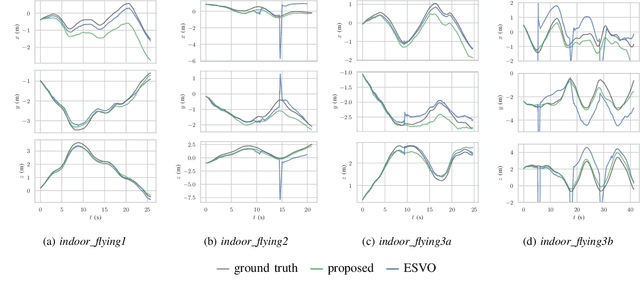
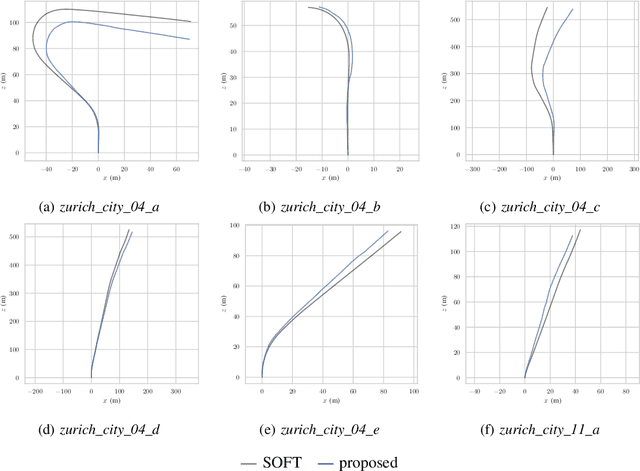
Event-based cameras are biologically inspired sensors that output events, i.e., asynchronous pixel-wise brightness changes in the scene. Their high dynamic range and temporal resolution of a microsecond makes them more reliable than standard cameras in environments of challenging illumination and in high-speed scenarios, thus developing odometry algorithms based solely on event cameras offers exciting new possibilities for autonomous systems and robots. In this paper, we propose a novel stereo visual odometry method for event cameras based on feature detection and matching with careful feature management, while pose estimation is done by reprojection error minimization. We evaluate the performance of the proposed method on two publicly available datasets: MVSEC sequences captured by an indoor flying drone and DSEC outdoor driving sequences. MVSEC offers accurate ground truth from motion capture, while for DSEC, which does not offer ground truth, in order to obtain a reference trajectory on the standard camera frames we used our SOFT visual odometry, one of the highest ranking algorithms on the KITTI scoreboards. We compared our method to the ESVO method, which is the first and still the only stereo event odometry method, showing on par performance on the MVSEC sequences, while on the DSEC dataset ESVO, unlike our method, was unable to handle outdoor driving scenario with default parameters. Furthermore, two important advantages of our method over ESVO are that it adapts tracking frequency to the asynchronous event rate and does not require initialization.
Joint Forecasting of Features and Feature Motion for Dense Semantic Future Prediction
Jan 26, 2021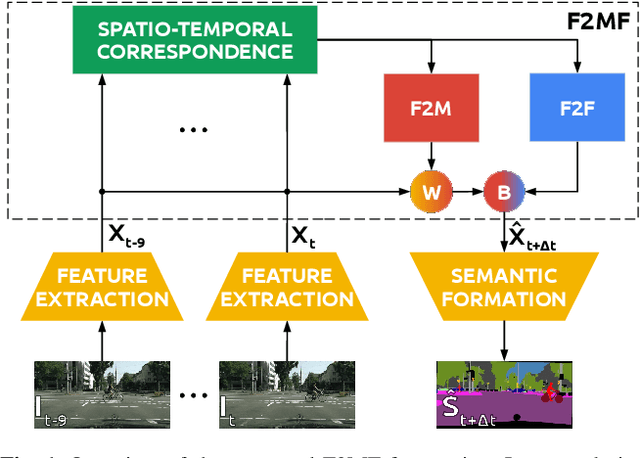
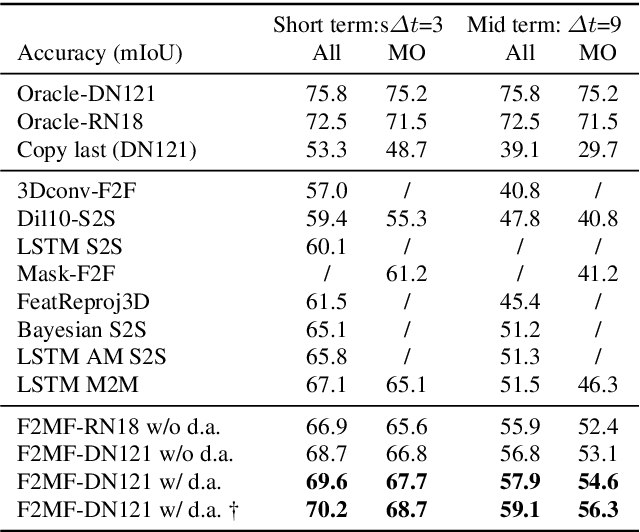
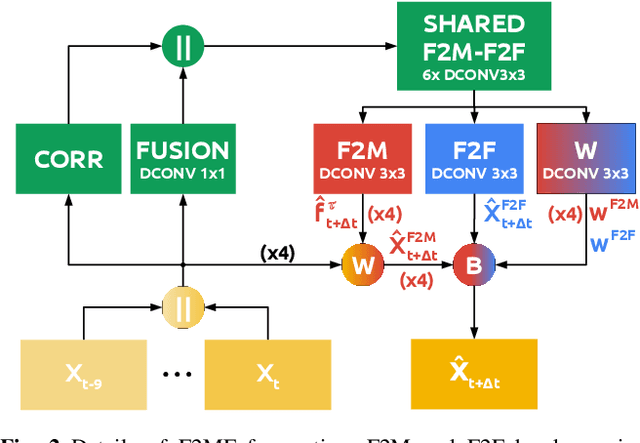

We present a novel dense semantic forecasting approach which is applicable to a variety of architectures and tasks. The approach consists of two modules. Feature-to-motion (F2M) module forecasts a dense deformation field which warps past features into their future positions. Feature-to-feature (F2F) module regresses the future features directly and is therefore able to account for emergent scenery. The compound F2MF approach decouples effects of motion from the effects of novelty in a task-agnostic manner. We aim to apply F2MF forecasting to the most subsampled and the most abstract representation of a desired single-frame model. Our implementations take advantage of deformable convolutions and pairwise correlation coefficients across neighbouring time instants. We perform experiments on three dense prediction tasks: semantic segmentation, instance-level segmentation, and panoptic segmentation. The results reveal state-of-the-art forecasting accuracy across all three modalities on the Cityscapes dataset.
Single Level Feature-to-Feature Forecasting with Deformable Convolutions
Jul 26, 2019



Future anticipation is of vital importance in autonomous driving and other decision-making systems. We present a method to anticipate semantic segmentation of future frames in driving scenarios based on feature-to-feature forecasting. Our method is based on a semantic segmentation model without lateral connections within the upsampling path. Such design ensures that the forecasting addresses only the most abstract features on a very coarse resolution. We further propose to express feature-to-feature forecasting with deformable convolutions. This increases the modelling power due to being able to represent different motion patterns within a single feature map. Experiments show that our models with deformable convolutions outperform their regular and dilated counterparts while minimally increasing the number of parameters. Our method achieves state of the art performance on the Cityscapes validation set when forecasting nine timesteps into the future.