 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Forecasting of Features and Feature Motion for Dense Semantic Future Prediction
Paper and Code
Jan 26, 2021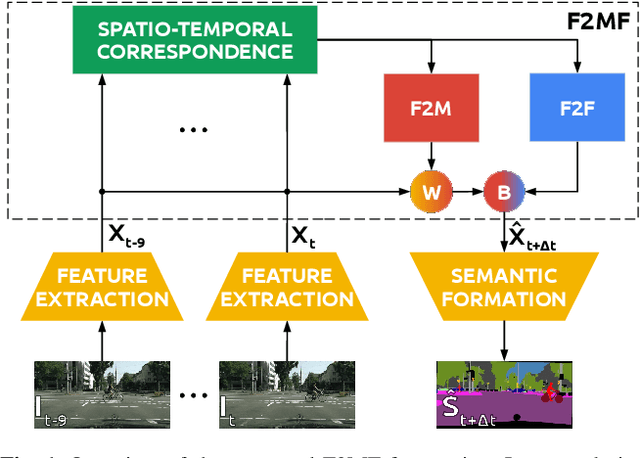
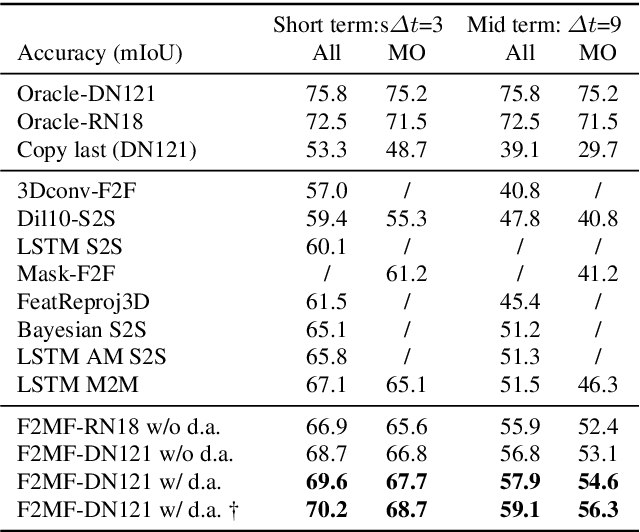
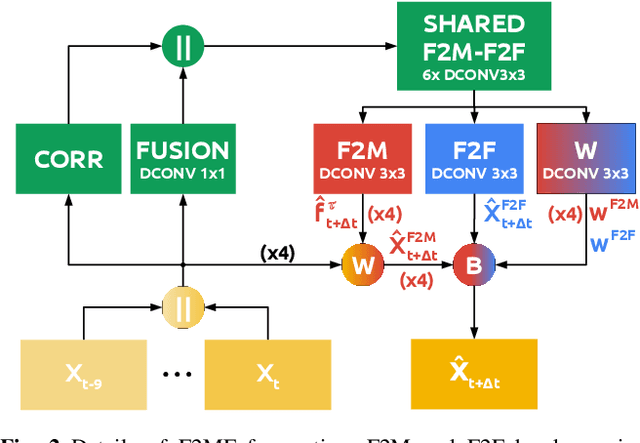

We present a novel dense semantic forecasting approach which is applicable to a variety of architectures and tasks. The approach consists of two modules. Feature-to-motion (F2M) module forecasts a dense deformation field which warps past features into their future positions. Feature-to-feature (F2F) module regresses the future features directly and is therefore able to account for emergent scenery. The compound F2MF approach decouples effects of motion from the effects of novelty in a task-agnostic manner. We aim to apply F2MF forecasting to the most subsampled and the most abstract representation of a desired single-frame model. Our implementations take advantage of deformable convolutions and pairwise correlation coefficients across neighbouring time instants. We perform experiments on three dense prediction tasks: semantic segmentation, instance-level segmentation, and panoptic segmentation. The results reveal state-of-the-art forecasting accuracy across all three modalities on the Cityscapes dataset.