 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar-Inertial Odometry with Online Spatio-Temporal Calibration via Continuous-Time IMU Modeling
Mar 20, 2026Radar-Inertial Odometry (RIO) has emerged as a robust alternative to vision- and LiDAR-based odometry in challenging conditions such as low light, fog, featureless environments, or in adverse weather. However, many existing RIO approaches assume known radar-IMU extrinsic calibration or rely on sufficient motion excitation for online extrinsic estimation, while temporal misalignment between sensors is often neglected or treated independently. In this work, we present a RIO framework that performs joint online spatial and temporal calibration within a factor-graph optimization formulation, based on continuous-time modeling of inertial measurements using uniform cubic B-splines. The proposed continuous-time representation of acceleration and angular velocity accurately captures the asynchronous nature of radar-IMU measurements, enabling reliable convergence of both the temporal offset and extrinsic calibration parameters, without relying on scan matching, target tracking, or environment-specific assumptions.
An Active Inference Model of Covert and Overt Visual Attention
May 06, 2025The ability to selectively attend to relevant stimuli while filtering out distractions is essential for agents that process complex, high-dimensional sensory input. This paper introduces a model of covert and overt visual attention through the framework of active inference, utilizing dynamic optimization of sensory precisions to minimize free-energy. The model determines visual sensory precisions based on both current environmental beliefs and sensory input, influencing attentional allocation in both covert and overt modalities. To test the effectiveness of the model, we analyze its behavior in the Posner cueing task and a simple target focus task using two-dimensional(2D) visual data. Reaction times are measured to investigate the interplay between exogenous and endogenous attention, as well as valid and invalid cueing. The results show that exogenous and valid cues generally lead to faster reaction times compared to endogenous and invalid cues. Furthermore, the model exhibits behavior similar to inhibition of return, where previously attended locations become suppressed after a specific cue-target onset asynchrony interval. Lastly, we investigate different aspects of overt attention and show that involuntary, reflexive saccades occur faster than intentional ones, but at the expense of adaptability.
Impact of Temporal Delay on Radar-Inertial Odometry
Mar 04, 2025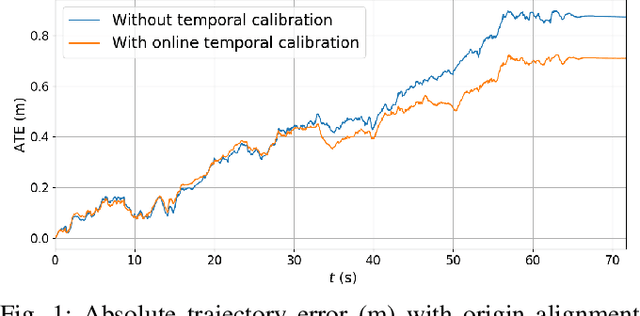
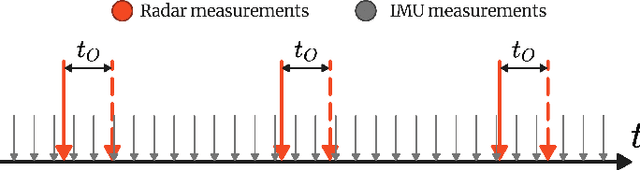
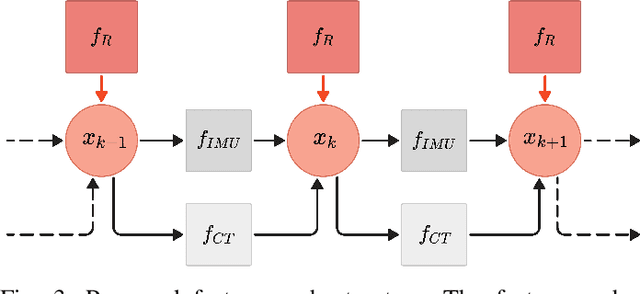
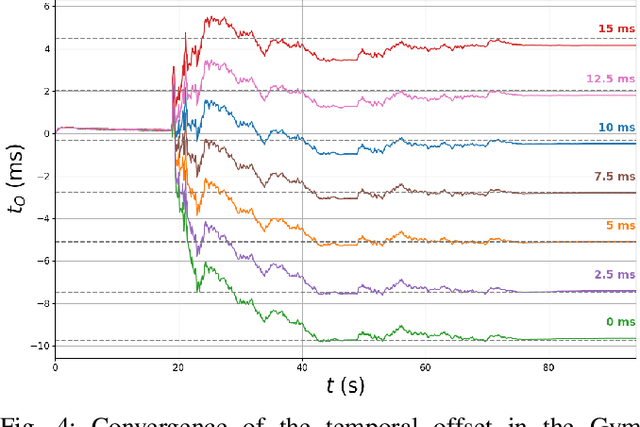
Accurate ego-motion estimation is a critical component of any autonomous system. Conventional ego-motion sensors, such as cameras and LiDARs, may be compromised in adverse environmental conditions, such as fog, heavy rain, or dust. Automotive radars, known for their robustness to such conditions, present themselves as complementary sensors or a promising alternative within the ego-motion estimation frameworks. In this paper we propose a novel Radar-Inertial Odometry (RIO) system that integrates an automotive radar and an inertial measurement unit. The key contribution is the integration of online temporal delay calibration within the factor graph optimization framework that compensates for potential time offsets between radar and IMU measurements. To validate the proposed approach we have conducted thorough experimental analysis on real-world radar and IMU data. The results show that, even without scan matching or target tracking, integration of online temporal calibration significantly reduces localization error compared to systems that disregard time synchronization, thus highlighting the important role of, often neglected, accurate temporal alignment in radar-based sensor fusion systems for autonomous navigation.
RAVE: A Framework for Radar Ego-Velocity Estimation
Jun 27, 2024



State estimation is an essential component of autonomous systems, usually relying on sensor fusion that integrates data from cameras, LiDARs and IMUs. Recently, radars have shown the potential to improve the accuracy and robustness of state estimation and perception, especially in challenging environmental conditions such as adverse weather and low-light scenarios. In this paper, we present a framework for ego-velocity estimation, which we call RAVE, that relies on 3D automotive radar data and encompasses zero velocity detection, outlier rejection, and velocity estimation. In addition, we propose a simple filtering method to discard infeasible ego-velocity estimates. We also conduct a systematic analysis of how different existing outlier rejection techniques and optimization loss functions impact estimation accuracy. Our evaluation on three open-source datasets demonstrates the effectiveness of the proposed filter and a significant positive impact of RAVE on the odometry accuracy. Furthermore, we release an open-source implementation of the proposed framework for radar ego-velocity estimation accompanied with a ROS interface.
GenDepth: Generalizing Monocular Depth Estimation for Arbitrary Camera Parameters via Ground Plane Embedding
Dec 10, 2023Learning-based monocular depth estimation leverages geometric priors present in the training data to enable metric depth perception from a single image, a traditionally ill-posed problem. However, these priors are often specific to a particular domain, leading to limited generalization performance on unseen data. Apart from the well studied environmental domain gap, monocular depth estimation is also sensitive to the domain gap induced by varying camera parameters, an aspect that is often overlooked in current state-of-the-art approaches. This issue is particularly evident in autonomous driving scenarios, where datasets are typically collected with a single vehicle-camera setup, leading to a bias in the training data due to a fixed perspective geometry. In this paper, we challenge this trend and introduce GenDepth, a novel model capable of performing metric depth estimation for arbitrary vehicle-camera setups. To address the lack of data with sufficiently diverse camera parameters, we first create a bespoke synthetic dataset collected with different vehicle-camera systems. Then, we design GenDepth to simultaneously optimize two objectives: (i) equivariance to the camera parameter variations on synthetic data, (ii) transferring the learned equivariance to real-world environmental features using a single real-world dataset with a fixed vehicle-camera system. To achieve this, we propose a novel embedding of camera parameters as the ground plane depth and present a novel architecture that integrates these embeddings with adversarial domain alignment. We validate GenDepth on several autonomous driving datasets, demonstrating its state-of-the-art generalization capability for different vehicle-camera systems.
A Distance-Geometric Method for Recovering Robot Joint Angles From an RGB Image
Jan 05, 2023



Autonomous manipulation systems operating in domains where human intervention is difficult or impossible (e.g., underwater, extraterrestrial or hazardous environments) require a high degree of robustness to sensing and communication failures. Crucially, motion planning and control algorithms require a stream of accurate joint angle data provided by joint encoders, the failure of which may result in an unrecoverable loss of functionality. In this paper, we present a novel method for retrieving the joint angles of a robot manipulator using only a single RGB image of its current configuration, opening up an avenue for recovering system functionality when conventional proprioceptive sensing is unavailable. Our approach, based on a distance-geometric representation of the configuration space, exploits the knowledge of a robot's kinematic model with the goal of training a shallow neural network that performs a 2D-to-3D regression of distances associated with detected structural keypoints. It is shown that the resulting Euclidean distance matrix uniquely corresponds to the observed configuration, where joint angles can be recovered via multidimensional scaling and a simple inverse kinematics procedure. We evaluate the performance of our approach on real RGB images of a Franka Emika Panda manipulator, showing that the proposed method is efficient and exhibits solid generalization ability. Furthermore, we show that our method can be easily combined with a dense refinement technique to obtain superior results.
Motion Planning in Dynamic Environments Using Context-Aware Human Trajectory Prediction
Jan 13, 2022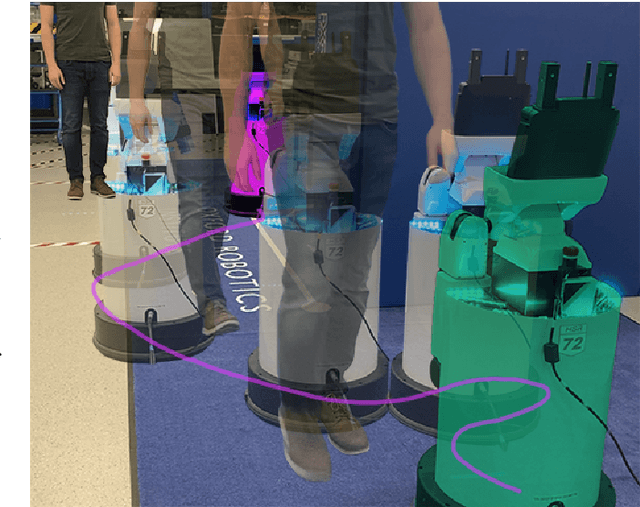
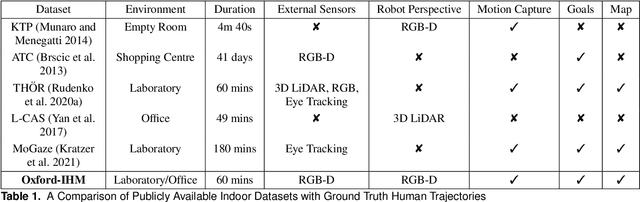
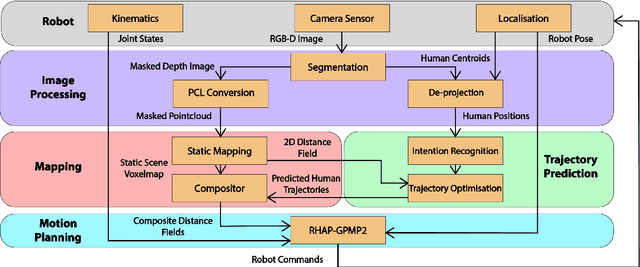

Over the years, the separate fields of motion planning, mapping, and human trajectory prediction have advanced considerably. However, the literature is still sparse in providing practical frameworks that enable mobile manipulators to perform whole-body movements and account for the predicted motion of moving obstacles. Previous optimisation-based motion planning approaches that use distance fields have suffered from the high computational cost required to update the environment representation. We demonstrate that GPU-accelerated predicted composite distance fields significantly reduce the computation time compared to calculating distance fields from scratch. We integrate this technique with a complete motion planning and perception framework that accounts for the predicted motion of humans in dynamic environments, enabling reactive and pre-emptive motion planning that incorporates predicted motions. To achieve this, we propose and implement a novel human trajectory prediction method that combines intention recognition with trajectory optimisation-based motion planning. We validate our resultant framework on a real-world Toyota Human Support Robot (HSR) using live RGB-D sensor data from the onboard camera. In addition to providing analysis on a publicly available dataset, we release the Oxford Indoor Human Motion (Oxford-IHM) dataset and demonstrate state-of-the-art performance in human trajectory prediction. The Oxford-IHM dataset is a human trajectory prediction dataset in which people walk between regions of interest in an indoor environment. Both static and robot-mounted RGB-D cameras observe the people while tracked with a motion-capture system.
Recalibrating the KITTI Dataset Camera Setup for Improved Odometry Accuracy
Sep 08, 2021

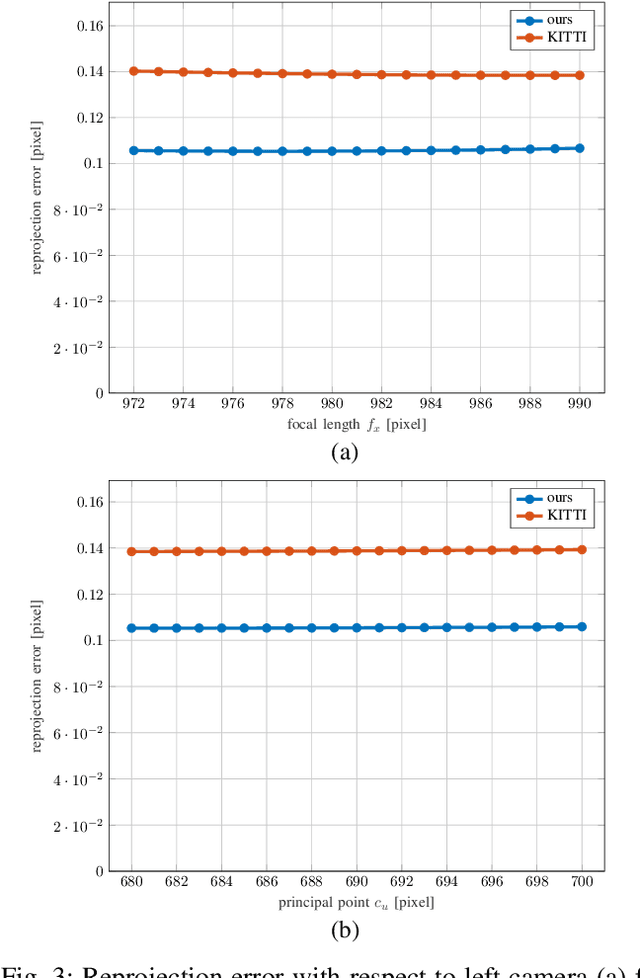
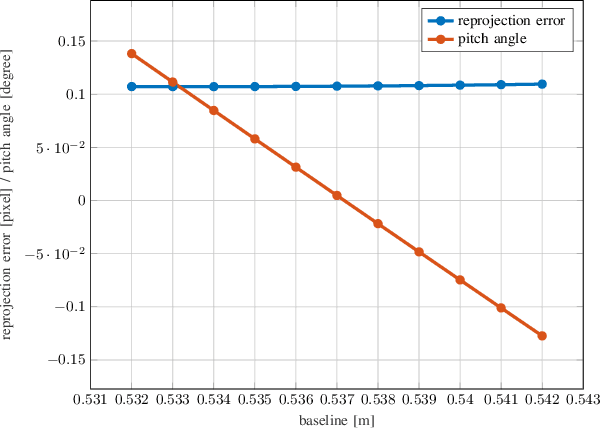
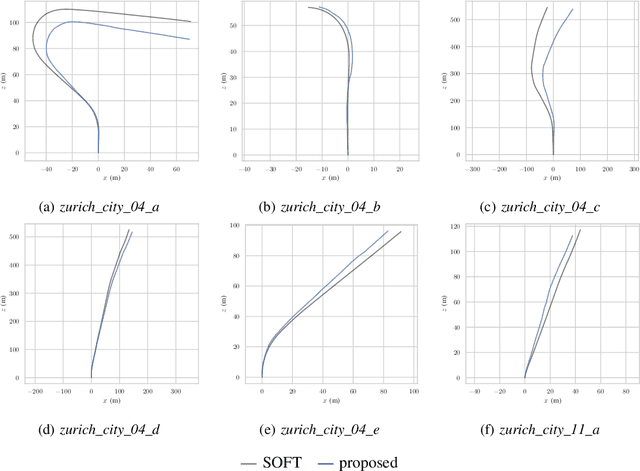
Over the last decade, one of the most relevant public datasets for evaluating odometry accuracy is the KITTI dataset. Beside the quality and rich sensor setup, its success is also due to the online evaluation tool, which enables researchers to benchmark and compare algorithms. The results are evaluated on the test subset solely, without any knowledge about the ground truth, yielding unbiased, overfit free and therefore relevant validation for robot localization based on cameras, 3D laser or combination of both. However, as any sensor setup, it requires prior calibration and rectified stereo images are provided, introducing dependence on the default calibration parameters. Given that, a natural question arises if a better set of calibration parameters can be found that would yield higher odometry accuracy. In this paper, we propose a new approach for one shot calibration of the KITTI dataset multiple camera setup. The approach yields better calibration parameters, both in the sense of lower calibration reprojection errors and lower visual odometry error. We conducted experiments where we show for three different odometry algorithms, namely SOFT2, ORB-SLAM2 and VISO2, that odometry accuracy is significantly improved with the proposed calibration parameters. Moreover, our odometry, SOFT2, in conjunction with the proposed calibration method achieved the highest accuracy on the official KITTI scoreboard with 0.53% translational and 0.0009 deg/m rotational error, outperforming even 3D laser-based methods.
Feature-based Event Stereo Visual Odometry
Jul 10, 2021

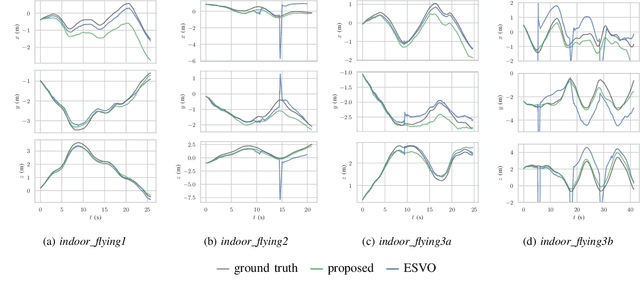
Event-based cameras are biologically inspired sensors that output events, i.e., asynchronous pixel-wise brightness changes in the scene. Their high dynamic range and temporal resolution of a microsecond makes them more reliable than standard cameras in environments of challenging illumination and in high-speed scenarios, thus developing odometry algorithms based solely on event cameras offers exciting new possibilities for autonomous systems and robots. In this paper, we propose a novel stereo visual odometry method for event cameras based on feature detection and matching with careful feature management, while pose estimation is done by reprojection error minimization. We evaluate the performance of the proposed method on two publicly available datasets: MVSEC sequences captured by an indoor flying drone and DSEC outdoor driving sequences. MVSEC offers accurate ground truth from motion capture, while for DSEC, which does not offer ground truth, in order to obtain a reference trajectory on the standard camera frames we used our SOFT visual odometry, one of the highest ranking algorithms on the KITTI scoreboards. We compared our method to the ESVO method, which is the first and still the only stereo event odometry method, showing on par performance on the MVSEC sequences, while on the DSEC dataset ESVO, unlike our method, was unable to handle outdoor driving scenario with default parameters. Furthermore, two important advantages of our method over ESVO are that it adapts tracking frequency to the asynchronous event rate and does not require initialization.
Ensemble of LSTMs and feature selection for human action prediction
Jan 14, 2021
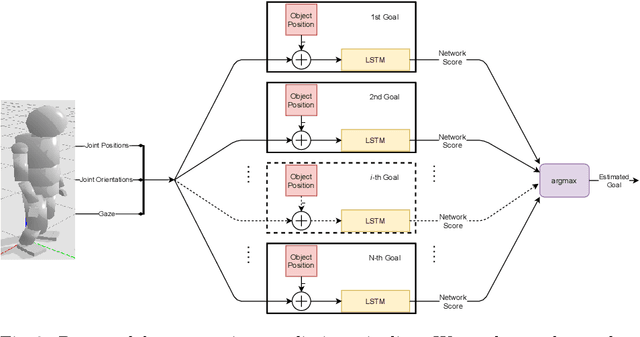
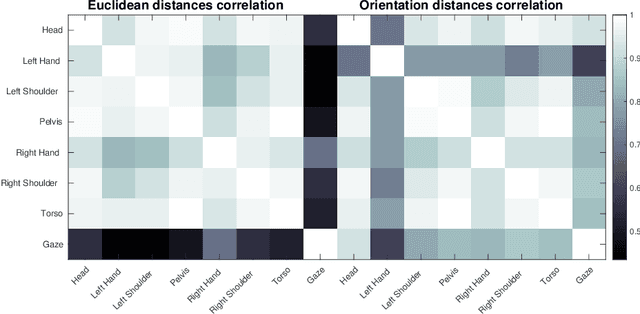
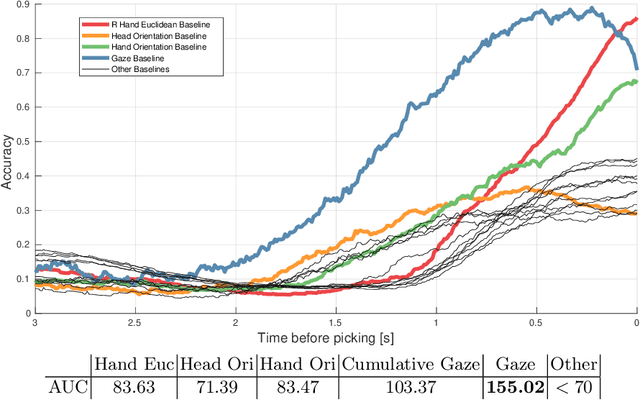
As robots are becoming more and more ubiquitous in human environments, it will be necessary for robotic systems to better understand and predict human actions. However, this is not an easy task, at times not even for us humans, but based on a relatively structured set of possible actions, appropriate cues, and the right model, this problem can be computationally tackled. In this paper, we propose to use an ensemble of long-short term memory (LSTM) networks for human action prediction. To train and evaluate models, we used the MoGaze dataset - currently the most comprehensive dataset capturing poses of human joints and the human gaze. We have thoroughly analyzed the MoGaze dataset and selected a reduced set of cues for this task. Our model can predict (i) which of the labeled objects the human is going to grasp, and (ii) which of the macro locations the human is going to visit (such as table or shelf). We have exhaustively evaluated the proposed method and compared it to individual cue baselines. The results suggest that our LSTM model slightly outperforms the gaze baseline in single object picking accuracy, but achieves better accuracy in macro object prediction. Furthermore, we have also analyzed the prediction accuracy when the gaze is not used, and in this case, the LSTM model considerably outperformed the best single cue baseline