 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar-Inertial Odometry with Online Spatio-Temporal Calibration via Continuous-Time IMU Modeling
Mar 20, 2026Radar-Inertial Odometry (RIO) has emerged as a robust alternative to vision- and LiDAR-based odometry in challenging conditions such as low light, fog, featureless environments, or in adverse weather. However, many existing RIO approaches assume known radar-IMU extrinsic calibration or rely on sufficient motion excitation for online extrinsic estimation, while temporal misalignment between sensors is often neglected or treated independently. In this work, we present a RIO framework that performs joint online spatial and temporal calibration within a factor-graph optimization formulation, based on continuous-time modeling of inertial measurements using uniform cubic B-splines. The proposed continuous-time representation of acceleration and angular velocity accurately captures the asynchronous nature of radar-IMU measurements, enabling reliable convergence of both the temporal offset and extrinsic calibration parameters, without relying on scan matching, target tracking, or environment-specific assumptions.
Impact of Temporal Delay on Radar-Inertial Odometry
Mar 04, 2025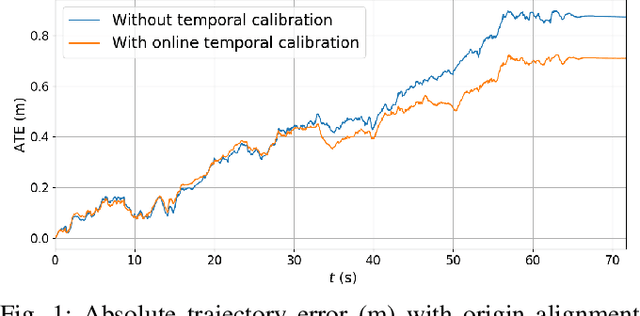
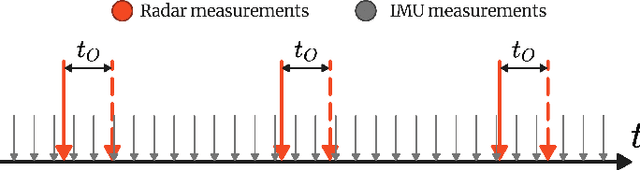
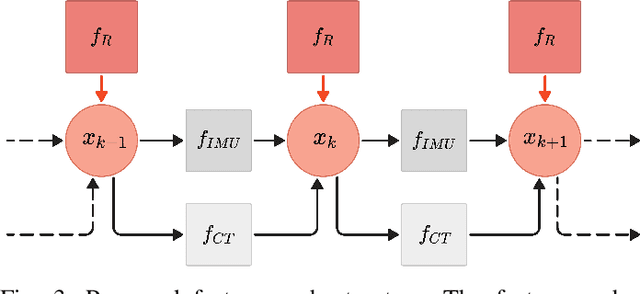
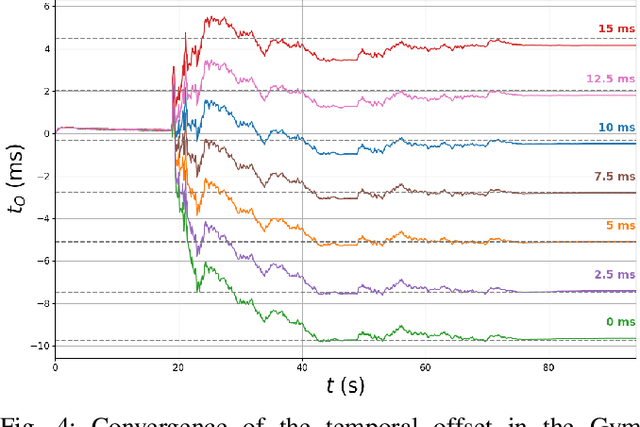
Accurate ego-motion estimation is a critical component of any autonomous system. Conventional ego-motion sensors, such as cameras and LiDARs, may be compromised in adverse environmental conditions, such as fog, heavy rain, or dust. Automotive radars, known for their robustness to such conditions, present themselves as complementary sensors or a promising alternative within the ego-motion estimation frameworks. In this paper we propose a novel Radar-Inertial Odometry (RIO) system that integrates an automotive radar and an inertial measurement unit. The key contribution is the integration of online temporal delay calibration within the factor graph optimization framework that compensates for potential time offsets between radar and IMU measurements. To validate the proposed approach we have conducted thorough experimental analysis on real-world radar and IMU data. The results show that, even without scan matching or target tracking, integration of online temporal calibration significantly reduces localization error compared to systems that disregard time synchronization, thus highlighting the important role of, often neglected, accurate temporal alignment in radar-based sensor fusion systems for autonomous navigation.
RAVE: A Framework for Radar Ego-Velocity Estimation
Jun 27, 2024



State estimation is an essential component of autonomous systems, usually relying on sensor fusion that integrates data from cameras, LiDARs and IMUs. Recently, radars have shown the potential to improve the accuracy and robustness of state estimation and perception, especially in challenging environmental conditions such as adverse weather and low-light scenarios. In this paper, we present a framework for ego-velocity estimation, which we call RAVE, that relies on 3D automotive radar data and encompasses zero velocity detection, outlier rejection, and velocity estimation. In addition, we propose a simple filtering method to discard infeasible ego-velocity estimates. We also conduct a systematic analysis of how different existing outlier rejection techniques and optimization loss functions impact estimation accuracy. Our evaluation on three open-source datasets demonstrates the effectiveness of the proposed filter and a significant positive impact of RAVE on the odometry accuracy. Furthermore, we release an open-source implementation of the proposed framework for radar ego-velocity estimation accompanied with a ROS interface.
GenDepth: Generalizing Monocular Depth Estimation for Arbitrary Camera Parameters via Ground Plane Embedding
Dec 10, 2023Learning-based monocular depth estimation leverages geometric priors present in the training data to enable metric depth perception from a single image, a traditionally ill-posed problem. However, these priors are often specific to a particular domain, leading to limited generalization performance on unseen data. Apart from the well studied environmental domain gap, monocular depth estimation is also sensitive to the domain gap induced by varying camera parameters, an aspect that is often overlooked in current state-of-the-art approaches. This issue is particularly evident in autonomous driving scenarios, where datasets are typically collected with a single vehicle-camera setup, leading to a bias in the training data due to a fixed perspective geometry. In this paper, we challenge this trend and introduce GenDepth, a novel model capable of performing metric depth estimation for arbitrary vehicle-camera setups. To address the lack of data with sufficiently diverse camera parameters, we first create a bespoke synthetic dataset collected with different vehicle-camera systems. Then, we design GenDepth to simultaneously optimize two objectives: (i) equivariance to the camera parameter variations on synthetic data, (ii) transferring the learned equivariance to real-world environmental features using a single real-world dataset with a fixed vehicle-camera system. To achieve this, we propose a novel embedding of camera parameters as the ground plane depth and present a novel architecture that integrates these embeddings with adversarial domain alignment. We validate GenDepth on several autonomous driving datasets, demonstrating its state-of-the-art generalization capability for different vehicle-camera systems.
Motion Planning in Dynamic Environments Using Context-Aware Human Trajectory Prediction
Jan 13, 2022
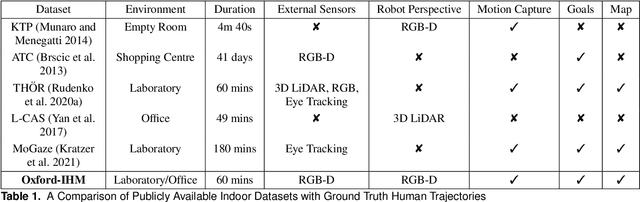
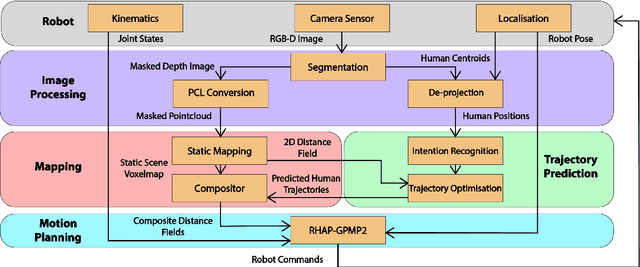

Over the years, the separate fields of motion planning, mapping, and human trajectory prediction have advanced considerably. However, the literature is still sparse in providing practical frameworks that enable mobile manipulators to perform whole-body movements and account for the predicted motion of moving obstacles. Previous optimisation-based motion planning approaches that use distance fields have suffered from the high computational cost required to update the environment representation. We demonstrate that GPU-accelerated predicted composite distance fields significantly reduce the computation time compared to calculating distance fields from scratch. We integrate this technique with a complete motion planning and perception framework that accounts for the predicted motion of humans in dynamic environments, enabling reactive and pre-emptive motion planning that incorporates predicted motions. To achieve this, we propose and implement a novel human trajectory prediction method that combines intention recognition with trajectory optimisation-based motion planning. We validate our resultant framework on a real-world Toyota Human Support Robot (HSR) using live RGB-D sensor data from the onboard camera. In addition to providing analysis on a publicly available dataset, we release the Oxford Indoor Human Motion (Oxford-IHM) dataset and demonstrate state-of-the-art performance in human trajectory prediction. The Oxford-IHM dataset is a human trajectory prediction dataset in which people walk between regions of interest in an indoor environment. Both static and robot-mounted RGB-D cameras observe the people while tracked with a motion-capture system.
A Riemannian Metric for Geometry-Aware Singularity Avoidance by Articulated Robots
Mar 09, 2021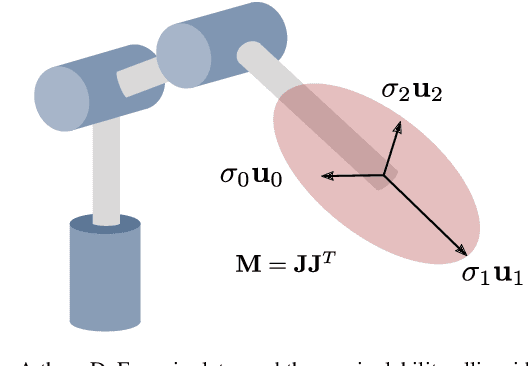

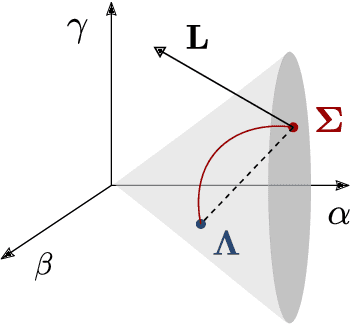
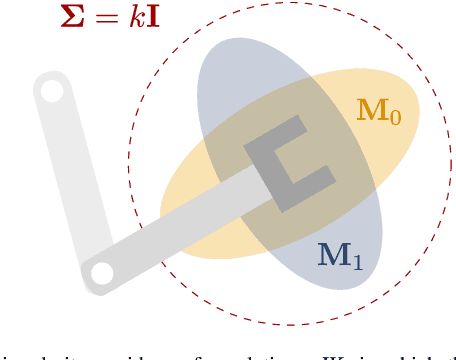
Articulated robots such as manipulators increasingly must operate in uncertain and dynamic environments where interaction (with human coworkers, for example) is necessary. In these situations, the capacity to quickly adapt to unexpected changes in operational space constraints is essential. At certain points in a manipulator's configuration space, termed singularities, the robot loses one or more degrees of freedom (DoF) and is unable to move in specific operational space directions. The inability to move in arbitrary directions in operational space compromises adaptivity and, potentially, safety. We introduce a geometry-aware singularity index,defined using a Riemannian metric on the manifold of symmetric positive definite matrices, to provide a measure of proximity to singular configurations. We demonstrate that our index avoids some of the failure modes and difficulties inherent to other common indices. Further, we show that this index can be differentiated easily, making it compatible with local optimization approaches used for operational space control. Our experimental results establish that, for reaching and path following tasks, optimization based on our index outperforms a common manipulability maximization technique, ensuring singularity-robust motions.
Ensemble of LSTMs and feature selection for human action prediction
Jan 14, 2021
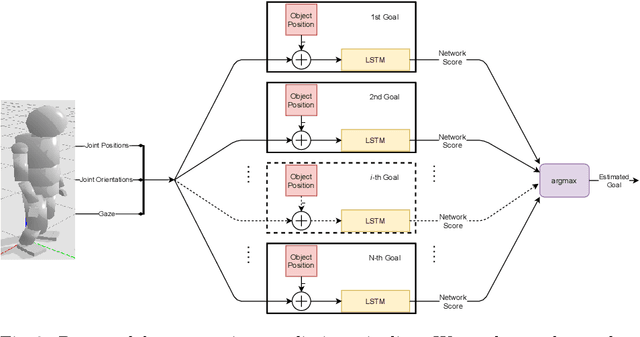
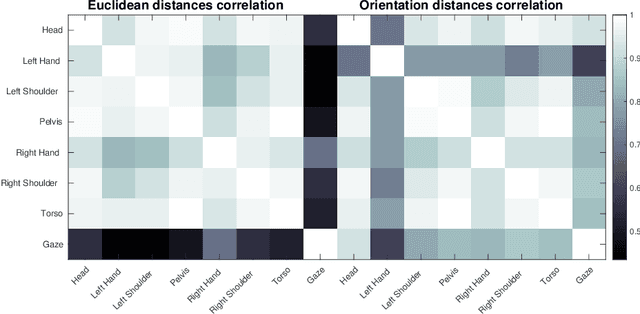
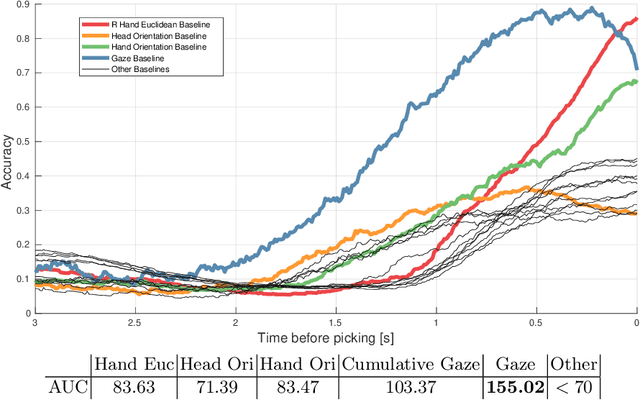
As robots are becoming more and more ubiquitous in human environments, it will be necessary for robotic systems to better understand and predict human actions. However, this is not an easy task, at times not even for us humans, but based on a relatively structured set of possible actions, appropriate cues, and the right model, this problem can be computationally tackled. In this paper, we propose to use an ensemble of long-short term memory (LSTM) networks for human action prediction. To train and evaluate models, we used the MoGaze dataset - currently the most comprehensive dataset capturing poses of human joints and the human gaze. We have thoroughly analyzed the MoGaze dataset and selected a reduced set of cues for this task. Our model can predict (i) which of the labeled objects the human is going to grasp, and (ii) which of the macro locations the human is going to visit (such as table or shelf). We have exhaustively evaluated the proposed method and compared it to individual cue baselines. The results suggest that our LSTM model slightly outperforms the gaze baseline in single object picking accuracy, but achieves better accuracy in macro object prediction. Furthermore, we have also analyzed the prediction accuracy when the gaze is not used, and in this case, the LSTM model considerably outperformed the best single cue baseline
Fast Manipulability Maximization Using Continuous-Time Trajectory Optimization
Aug 08, 2019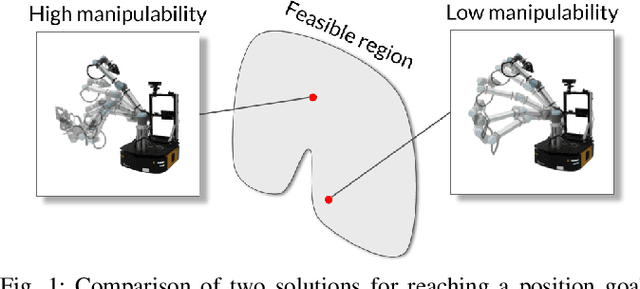
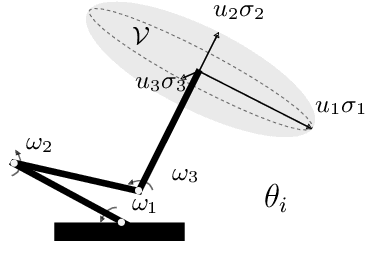
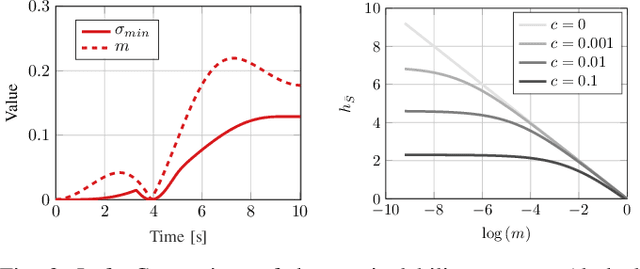
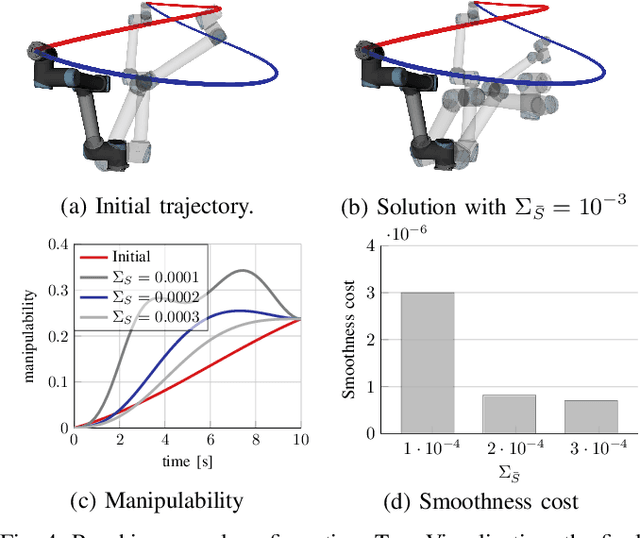
A significant challenge in manipulation motion planning is to ensure agility in the face of unpredictable changes during task execution. This requires the identification and possible modification of suitable joint-space trajectories, since the joint velocities required to achieve a specific end-effector motion vary with manipulator configuration. For a given manipulator configuration, the joint space-to-task space velocity mapping is characterized by a quantity known as the manipulability index. In contrast to previous control-based approaches, we examine the maximization of manipulability during planning as a way of achieving adaptable and safe joint space-to-task space motion mappings in various scenarios. By representing the manipulator trajectory as a continuous-time Gaussian process (GP), we are able to leverage recent advances in trajectory optimization to maximize the manipulability index during trajectory generation. Moreover, the sparsity of our chosen representation reduces the typically large computational cost associated with maximizing manipulability when additional constraints exist. Results from simulation studies and experiments with a real manipulator demonstrate increases in manipulability, while maintaining smooth trajectories with more dexterous (and therefore more agile) arm configurations.
Stochastic Optimization for Trajectory Planning with Heteroscedastic Gaussian Processes
Jul 17, 2019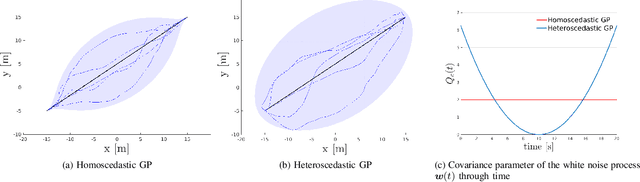
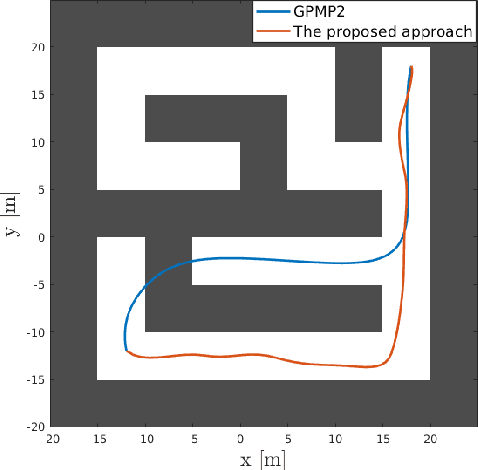
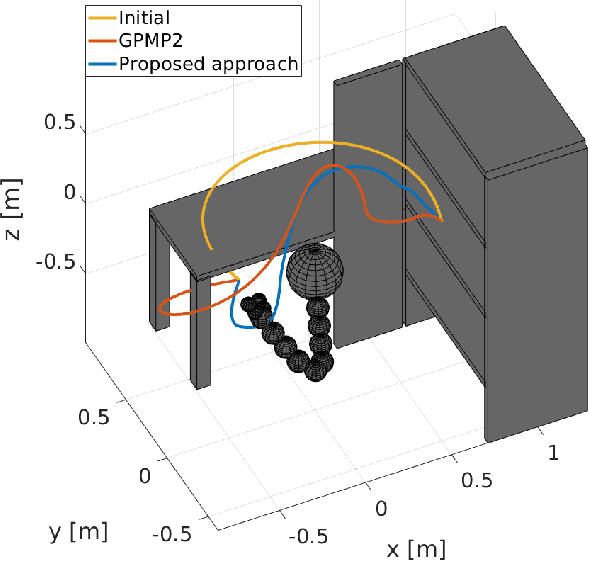
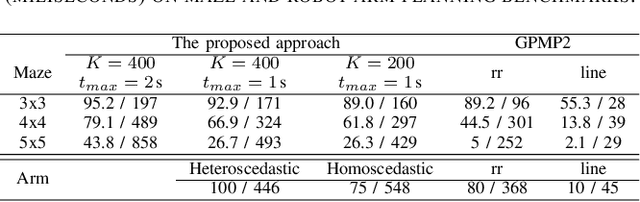
Trajectory optimization methods for motion planning attempt to generate trajectories that minimize a suitable objective function. Such methods efficiently find solutions even for high degree-of-freedom robots. However, a globally optimal solution is often intractable in practice and state-of-the-art trajectory optimization methods are thus prone to local minima, especially in cluttered environments. In this paper, we propose a novel motion planning algorithm that employs stochastic optimization based on the cross-entropy method in order to tackle the local minima problem. We represent trajectories as samples from a continuous-time Gaussian process and introduce heteroscedasticity to generate powerful trajectory priors better suited for collision avoidance in motion planning problems. Our experimental evaluation shows that the proposed approach yields a more thorough exploration of the solution space and a higher success rate in complex environments than a current Gaussian process based state-of-the-art trajectory optimization method, namely GPMP2, while having comparable execution time.
Spatio-Temporal Multisensor Calibration Based on Gaussian Processes Moving Object Tracking
Apr 08, 2019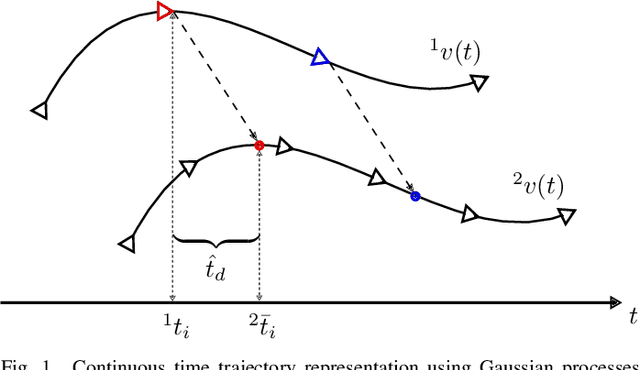
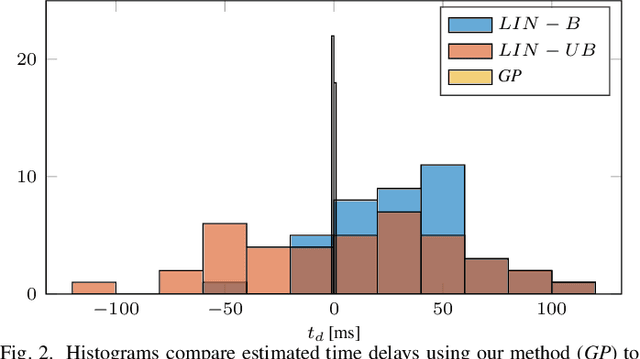
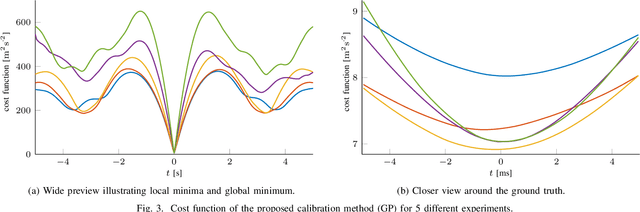
Perception is one of the key abilities of autonomous mobile robotic systems, which often relies on fusion of heterogeneous sensors. Although this heterogeneity presents a challenge for sensor calibration, it is also the main prospect for reliability and robustness of autonomous systems. In this paper, we propose a method for multisensor calibration based on Gaussian processes (GPs) estimated moving object trajectories, resulting with temporal and extrinsic parameters. The appealing properties of the proposed temporal calibration method are: coordinate frame invariance, thus avoiding prior extrinsic calibration, theoretically grounded batch state estimation and interpolation using GPs, computational efficiency with O(n) complexity, leveraging data already available in autonomous robot platforms, and the end result enabling 3D point-to-point extrinsic multisensor calibration. The proposed method is validated both in simulations and real-world experiments. For real-world experiment we evaluated the method on two multisensor systems: an externally triggered stereo camera, thus having temporal ground truth readily available, and a heterogeneous combination of a camera and motion capture system. The results show that the estimated time delays are accurate up to a fraction of the fastest sensor sampling time.