 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cross-Spectral Point Features with Task-Oriented Training
May 19, 2025Unmanned aerial vehicles (UAVs) enable operations in remote and hazardous environments, yet the visible-spectrum, camera-based navigation systems often relied upon by UAVs struggle in low-visibility conditions. Thermal cameras, which capture long-wave infrared radiation, are able to function effectively in darkness and smoke, where visible-light cameras fail. This work explores learned cross-spectral (thermal-visible) point features as a means to integrate thermal imagery into established camera-based navigation systems. Existing methods typically train a feature network's detection and description outputs directly, which often focuses training on image regions where thermal and visible-spectrum images exhibit similar appearance. Aiming to more fully utilize the available data, we propose a method to train the feature network on the tasks of matching and registration. We run our feature network on thermal-visible image pairs, then feed the network response into a differentiable registration pipeline. Losses are applied to the matching and registration estimates of this pipeline. Our selected model, trained on the task of matching, achieves a registration error (corner error) below 10 pixels for more than 75% of estimates on the MultiPoint dataset. We further demonstrate that our model can also be used with a classical pipeline for matching and registration.
Value-Penalized Auxiliary Control from Examples for Learning without Rewards or Demonstrations
Jul 03, 2024Learning from examples of success is an appealing approach to reinforcement learning that eliminates many of the disadvantages of using hand-crafted reward functions or full expert-demonstration trajectories, both of which can be difficult to acquire, biased, or suboptimal. However, learning from examples alone dramatically increases the exploration challenge, especially for complex tasks. This work introduces value-penalized auxiliary control from examples (VPACE); we significantly improve exploration in example-based control by adding scheduled auxiliary control and examples of auxiliary tasks. Furthermore, we identify a value-calibration problem, where policy value estimates can exceed their theoretical limits based on successful data. We resolve this problem, which is exacerbated by learning auxiliary tasks, through the addition of an above-success-level value penalty. Across three simulated and one real robotic manipulation environment, and 21 different main tasks, we show that our approach substantially improves learning efficiency. Videos, code, and datasets are available at https://papers.starslab.ca/vpace.
Working Backwards: Learning to Place by Picking
Dec 04, 2023



We present Learning to Place by Picking (LPP), a method capable of autonomously collecting demonstrations for a family of placing tasks in which objects must be manipulated to specific locations. With LPP, we approach the learning of robotic object placement policies by reversing the grasping process and exploiting the inherent symmetry of the pick and place problems. Specifically, we obtain placing demonstrations from a set of grasp sequences of objects that are initially located at their target placement locations. Our system is capable of collecting hundreds of demonstrations without human intervention by using a combination of tactile sensing and compliant control for grasps. We train a policy directly from visual observations through behaviour cloning, using the autonomously-collected demonstrations. By doing so, the policy can generalize to object placement scenarios outside of the training environment without privileged information (e.g., placing a plate picked up from a table and not at the original placement location). We validate our approach on home robotic scenarios that include dishwasher loading and table setting. Our approach yields robotic placing policies that outperform policies trained with kinesthetic teaching, both in terms of performance and data efficiency, while requiring no human supervision.
Push it to the Demonstrated Limit: Multimodal Visuotactile Imitation Learning with Force Matching
Nov 02, 2023
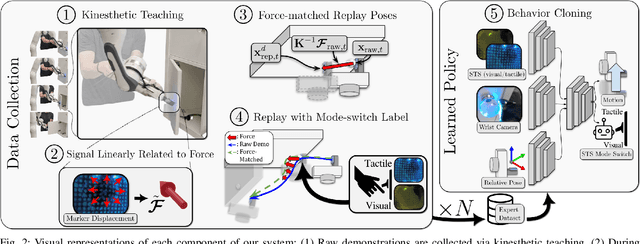
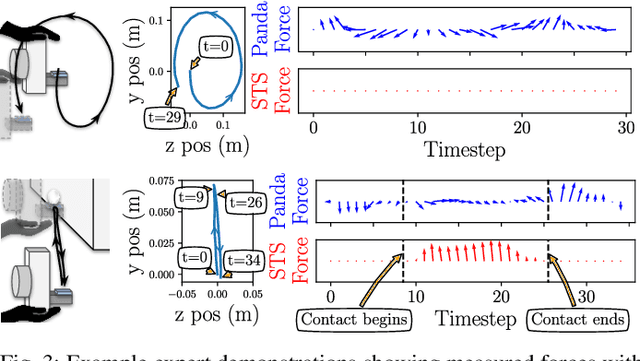
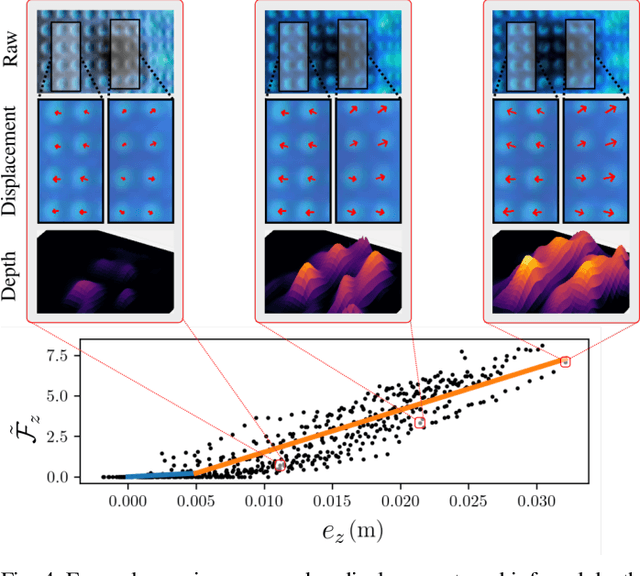
Optical tactile sensors have emerged as an effective means to acquire dense contact information during robotic manipulation. A recently-introduced `see-through-your-skin' (STS) variant of this type of sensor has both visual and tactile modes, enabled by leveraging a semi-transparent surface and controllable lighting. In this work, we investigate the benefits of pairing visuotactile sensing with imitation learning for contact-rich manipulation tasks. First, we use tactile force measurements and a novel algorithm during kinesthetic teaching to yield a force profile that better matches that of the human demonstrator. Second, we add visual/tactile STS mode switching as a control policy output, simplifying the application of the sensor. Finally, we study multiple observation configurations to compare and contrast the value of visual/tactile data (both with and without mode switching) with visual data from a wrist-mounted eye-in-hand camera. We perform an extensive series of experiments on a real robotic manipulator with door-opening and closing tasks, including over 3,000 real test episodes. Our results highlight the importance of tactile sensing for imitation learning, both for data collection to allow force matching, and for policy execution to allow accurate task feedback.
Learning from Guided Play: Improving Exploration for Adversarial Imitation Learning with Simple Auxiliary Tasks
Dec 30, 2022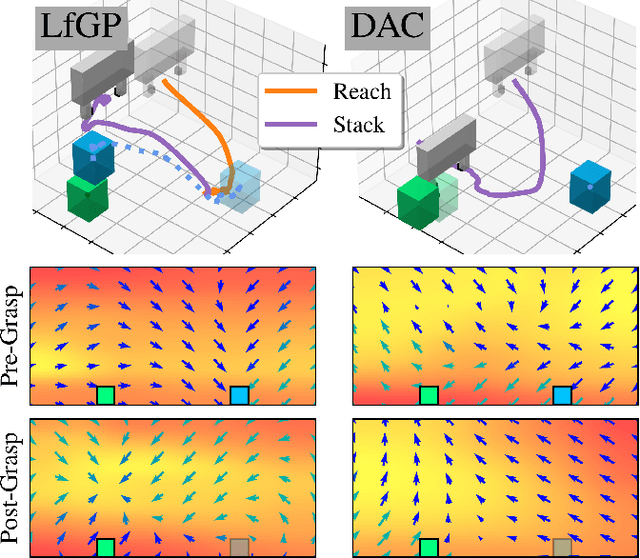

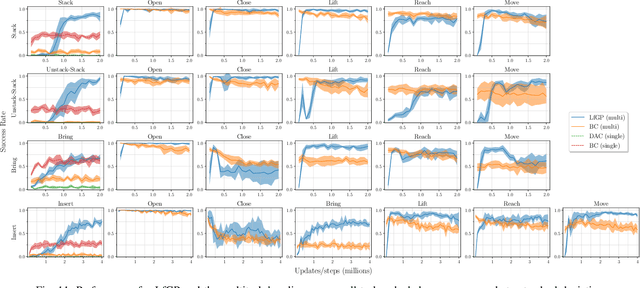
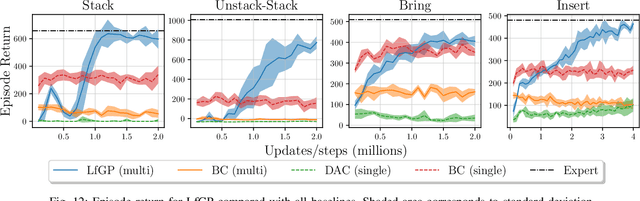
Adversarial imitation learning (AIL) has become a popular alternative to supervised imitation learning that reduces the distribution shift suffered by the latter. However, AIL requires effective exploration during an online reinforcement learning phase. In this work, we show that the standard, naive approach to exploration can manifest as a suboptimal local maximum if a policy learned with AIL sufficiently matches the expert distribution without fully learning the desired task. This can be particularly catastrophic for manipulation tasks, where the difference between an expert and a non-expert state-action pair is often subtle. We present Learning from Guided Play (LfGP), a framework in which we leverage expert demonstrations of multiple exploratory, auxiliary tasks in addition to a main task. The addition of these auxiliary tasks forces the agent to explore states and actions that standard AIL may learn to ignore. Additionally, this particular formulation allows for the reusability of expert data between main tasks. Our experimental results in a challenging multitask robotic manipulation domain indicate that LfGP significantly outperforms both AIL and behaviour cloning, while also being more expert sample efficient than these baselines. To explain this performance gap, we provide further analysis of a toy problem that highlights the coupling between a local maximum and poor exploration, and also visualize the differences between the learned models from AIL and LfGP.
Learning Sequential Latent Variable Models from Multimodal Time Series Data
Apr 21, 2022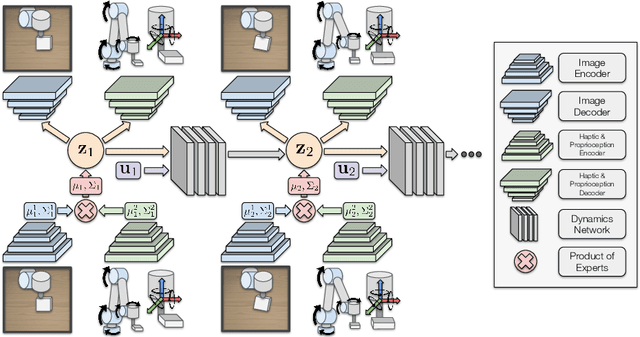

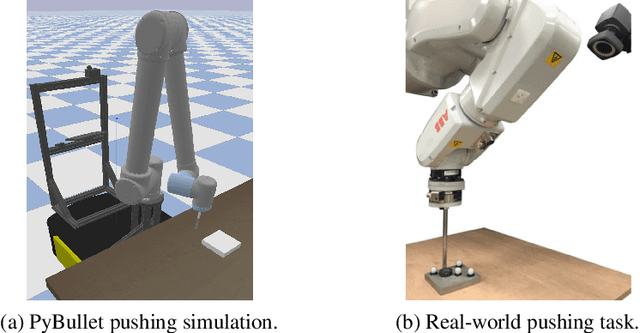

Sequential modelling of high-dimensional data is an important problem that appears in many domains including model-based reinforcement learning and dynamics identification for control. Latent variable models applied to sequential data (i.e., latent dynamics models) have been shown to be a particularly effective probabilistic approach to solve this problem, especially when dealing with images. However, in many application areas (e.g., robotics), information from multiple sensing modalities is available -- existing latent dynamics methods have not yet been extended to effectively make use of such multimodal sequential data. Multimodal sensor streams can be correlated in a useful manner and often contain complementary information across modalities. In this work, we present a self-supervised generative modelling framework to jointly learn a probabilistic latent state representation of multimodal data and the respective dynamics. Using synthetic and real-world datasets from a multimodal robotic planar pushing task, we demonstrate that our approach leads to significant improvements in prediction and representation quality. Furthermore, we compare to the common learning baseline of concatenating each modality in the latent space and show that our principled probabilistic formulation performs better. Finally, despite being fully self-supervised, we demonstrate that our method is nearly as effective as an existing supervised approach that relies on ground truth labels.
Learning from Guided Play: A Scheduled Hierarchical Approach for Improving Exploration in Adversarial Imitation Learning
Dec 16, 2021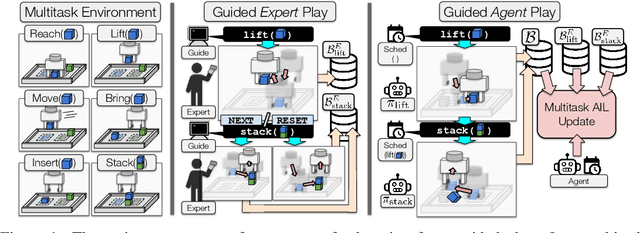
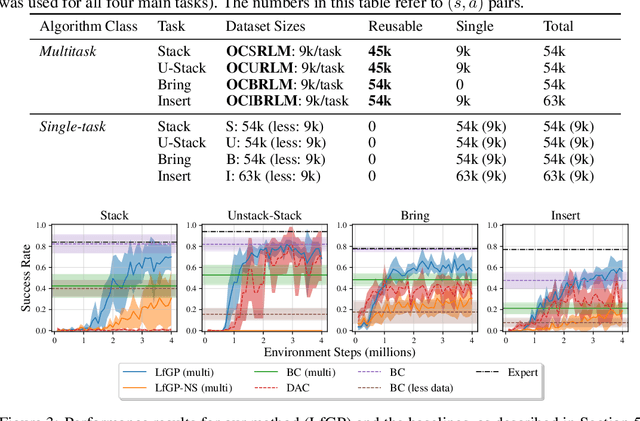

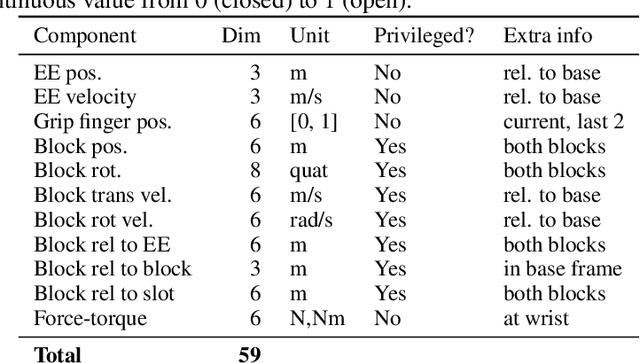
Effective exploration continues to be a significant challenge that prevents the deployment of reinforcement learning for many physical systems. This is particularly true for systems with continuous and high-dimensional state and action spaces, such as robotic manipulators. The challenge is accentuated in the sparse rewards setting, where the low-level state information required for the design of dense rewards is unavailable. Adversarial imitation learning (AIL) can partially overcome this barrier by leveraging expert-generated demonstrations of optimal behaviour and providing, essentially, a replacement for dense reward information. Unfortunately, the availability of expert demonstrations does not necessarily improve an agent's capability to explore effectively and, as we empirically show, can lead to inefficient or stagnated learning. We present Learning from Guided Play (LfGP), a framework in which we leverage expert demonstrations of, in addition to a main task, multiple auxiliary tasks. Subsequently, a hierarchical model is used to learn each task reward and policy through a modified AIL procedure, in which exploration of all tasks is enforced via a scheduler composing different tasks together. This affords many benefits: learning efficiency is improved for main tasks with challenging bottleneck transitions, expert data becomes reusable between tasks, and transfer learning through the reuse of learned auxiliary task models becomes possible. Our experimental results in a challenging multitask robotic manipulation domain indicate that our method compares favourably to supervised imitation learning and to a state-of-the-art AIL method. Code is available at https://github.com/utiasSTARS/lfgp.
Seeing All the Angles: Learning Multiview Manipulation Policies for Contact-Rich Tasks from Demonstrations
Apr 28, 2021
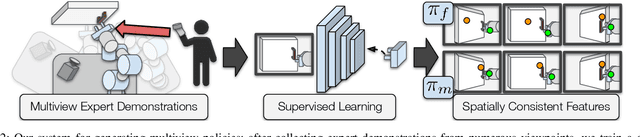
Learned visuomotor policies have shown considerable success as an alternative to traditional, hand-crafted frameworks for robotic manipulation tasks. Surprisingly, the extension of these methods to the multiview domain is relatively unexplored. A successful multiview policy could be deployed on a mobile manipulation platform, allowing it to complete a task regardless of its view of the scene. In this work, we demonstrate that a multiview policy can be found through imitation learning by collecting data from a variety of viewpoints. We illustrate the general applicability of the method by learning to complete several challenging multi-stage and contact-rich tasks, from numerous viewpoints, both in a simulated environment and on a real mobile manipulation platform. Furthermore, we analyze our policies to determine the benefits of learning from multiview data compared to learning with data from a fixed perspective. We show that learning from multiview data has little, if any, penalty to performance for a fixed-view task compared to learning with an equivalent amount of fixed-view data. Finally, we examine the visual features learned by the multiview and fixed-view policies. Our results indicate that multiview policies implicitly learn to identify spatially correlated features with a degree of view-invariance.
Fighting Failures with FIRE: Failure Identification to Reduce Expert Burden in Intervention-Based Learning
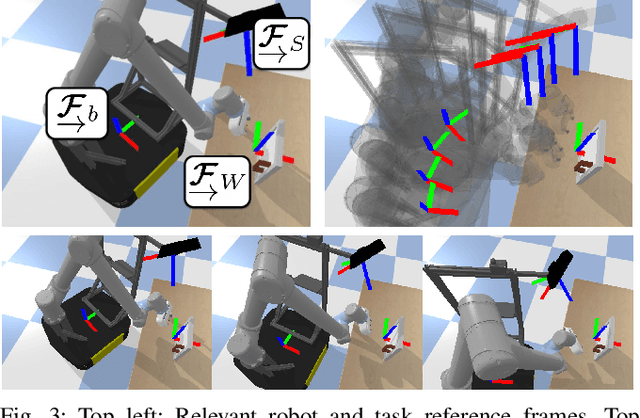
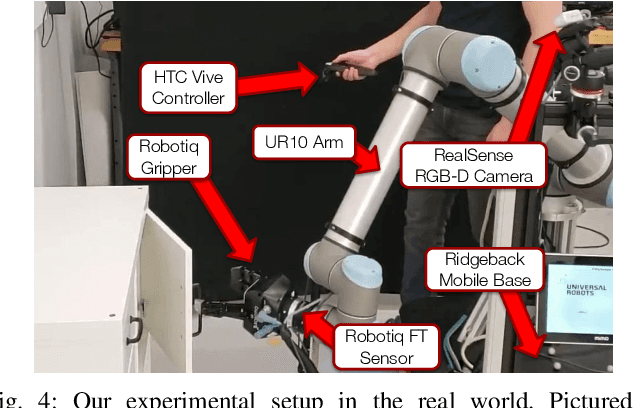
Jul 01, 2020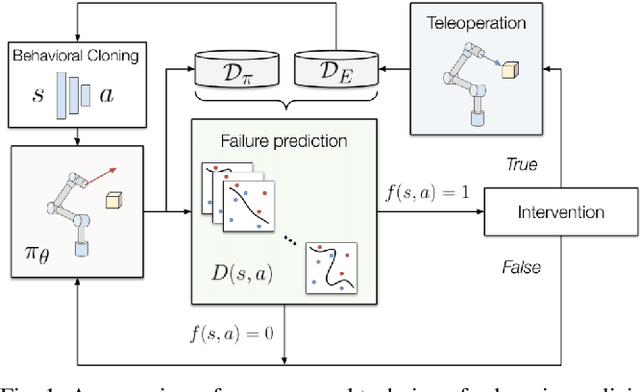
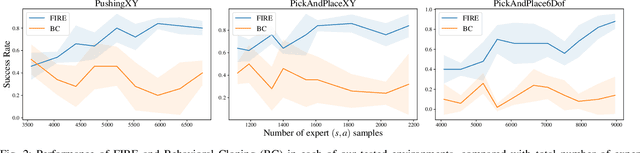
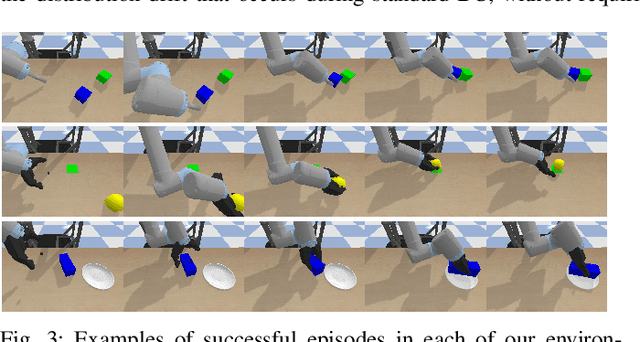
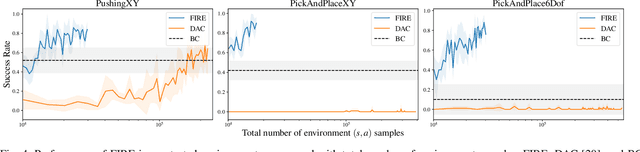
Supervised imitation learning, also known as behavior cloning, suffers from distribution drift leading to failures during policy execution. One approach to mitigating this issue is to allow an expert to correct the agent's actions during task execution, based on the expert's determination that the agent has reached a `point of no return'. The agent's policy is then retraining using these new corrective data. This approach alone can allow high-performance agents to be learned, but at a high cost: the expert must vigilantly observe execution until the policy reaches a specified level of success, and even at that point, there is no guarantee that the policy will always succeed. To address these limitations, we present FIRE (Failure Identification to Reduce Expert burden), a system that can predict when a running policy will fail, halt its execution, and request a correction from the expert. Unlike existing approaches that learn only from expert data, our approach learns from both expert and non-expert data, akin to adversarial learning. We demonstrate experimentally for a series of challenging manipulation tasks that our method is able to recognize state-action pairs that lead to failures. This allows seamless integration into an intervention-based learning system, where we show an order-of-magnitude gain in sample efficiency compared with a state-of-the-art inverse reinforcement learning methods and drastically improved performance over an equivalent amount of data learned with behavior cloning.
Fast Manipulability Maximization Using Continuous-Time Trajectory Optimization
Aug 08, 2019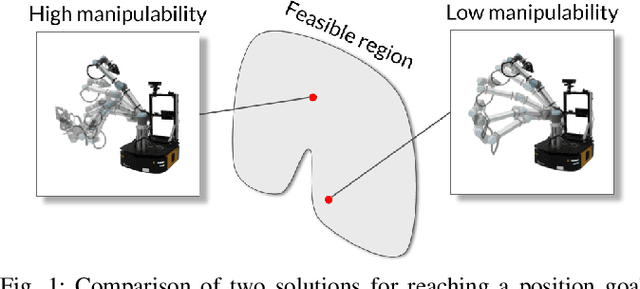
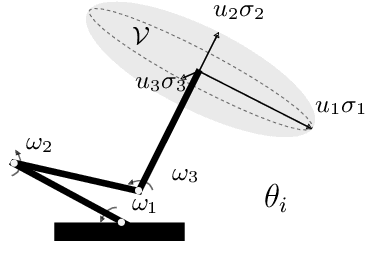
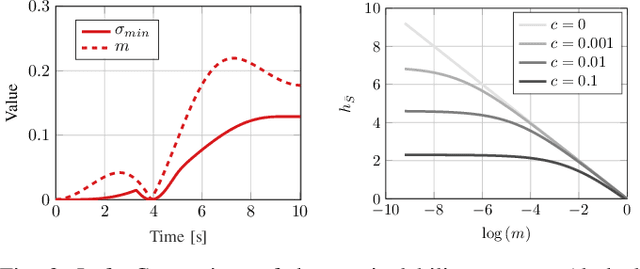
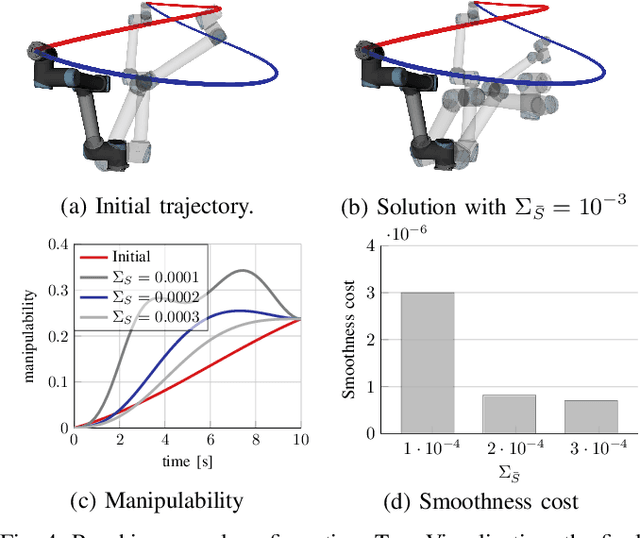
A significant challenge in manipulation motion planning is to ensure agility in the face of unpredictable changes during task execution. This requires the identification and possible modification of suitable joint-space trajectories, since the joint velocities required to achieve a specific end-effector motion vary with manipulator configuration. For a given manipulator configuration, the joint space-to-task space velocity mapping is characterized by a quantity known as the manipulability index. In contrast to previous control-based approaches, we examine the maximization of manipulability during planning as a way of achieving adaptable and safe joint space-to-task space motion mappings in various scenarios. By representing the manipulator trajectory as a continuous-time Gaussian process (GP), we are able to leverage recent advances in trajectory optimization to maximize the manipulability index during trajectory generation. Moreover, the sparsity of our chosen representation reduces the typically large computational cost associated with maximizing manipulability when additional constraints exist. Results from simulation studies and experiments with a real manipulator demonstrate increases in manipulability, while maintaining smooth trajectories with more dexterous (and therefore more agile) arm configurations.