 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting Failures with FIRE: Failure Identification to Reduce Expert Burden in Intervention-Based Learning
Paper and Code
Jul 01, 2020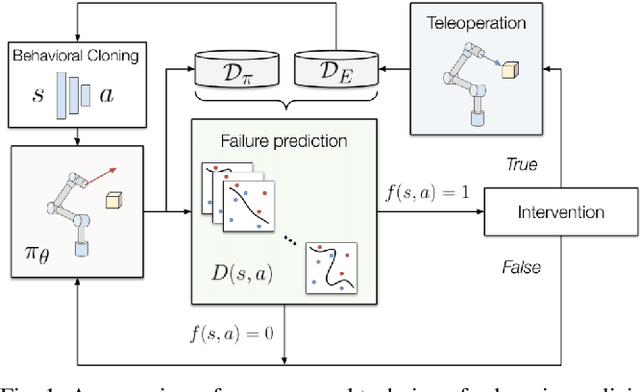
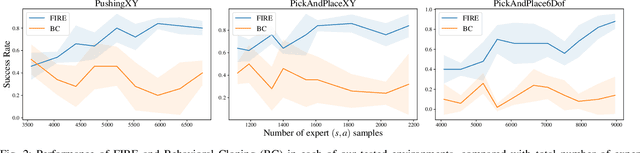
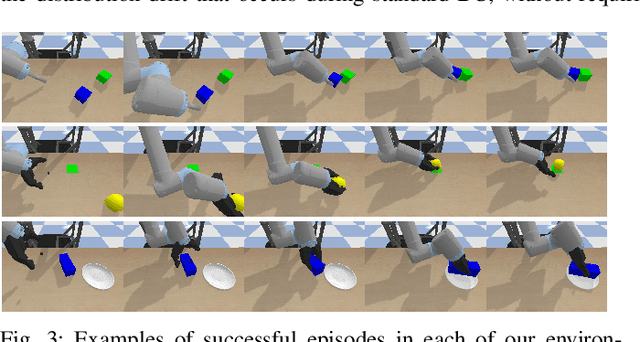
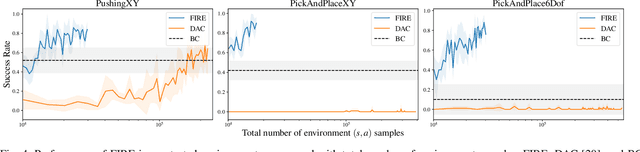
Supervised imitation learning, also known as behavior cloning, suffers from distribution drift leading to failures during policy execution. One approach to mitigating this issue is to allow an expert to correct the agent's actions during task execution, based on the expert's determination that the agent has reached a `point of no return'. The agent's policy is then retraining using these new corrective data. This approach alone can allow high-performance agents to be learned, but at a high cost: the expert must vigilantly observe execution until the policy reaches a specified level of success, and even at that point, there is no guarantee that the policy will always succeed. To address these limitations, we present FIRE (Failure Identification to Reduce Expert burden), a system that can predict when a running policy will fail, halt its execution, and request a correction from the expert. Unlike existing approaches that learn only from expert data, our approach learns from both expert and non-expert data, akin to adversarial learning. We demonstrate experimentally for a series of challenging manipulation tasks that our method is able to recognize state-action pairs that lead to failures. This allows seamless integration into an intervention-based learning system, where we show an order-of-magnitude gain in sample efficiency compared with a state-of-the-art inverse reinforcement learning methods and drastically improved performance over an equivalent amount of data learned with behavior cloning.