 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Sampling-Based Motion Planning on Riemannian Manifolds
Feb 01, 2026In many robot motion planning problems, task objectives and physical constraints induce non-Euclidean geometry on the configuration space, yet many planners operate using Euclidean distances that ignore this structure. We address the problem of planning collision-free motions that minimize length under configuration-dependent Riemannian metrics, corresponding to geodesics on the configuration manifold. Conventional numerical methods for computing such paths do not scale well to high-dimensional systems, while sampling-based planners trade scalability for geometric fidelity. To bridge this gap, we propose a sampling-based motion planning framework that operates directly on Riemannian manifolds. We introduce a computationally efficient midpoint-based approximation of the Riemannian geodesic distance and prove that it matches the true Riemannian distance with third-order accuracy. Building on this approximation, we design a local planner that traces the manifold using first-order retractions guided by Riemannian natural gradients. Experiments on a two-link planar arm and a 7-DoF Franka manipulator under a kinetic-energy metric, as well as on rigid-body planning in $\mathrm{SE}(2)$ with non-holonomic motion constraints, demonstrate that our approach consistently produces lower-cost trajectories than Euclidean-based planners and classical numerical geodesic-solver baselines.
VibES: Induced Vibration for Persistent Event-Based Sensing
Aug 26, 2025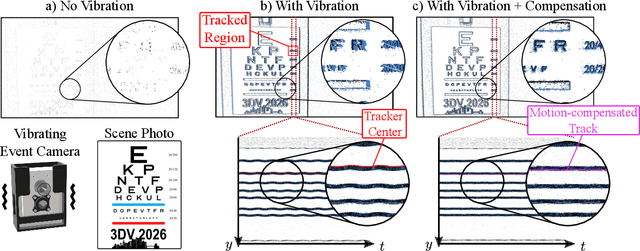
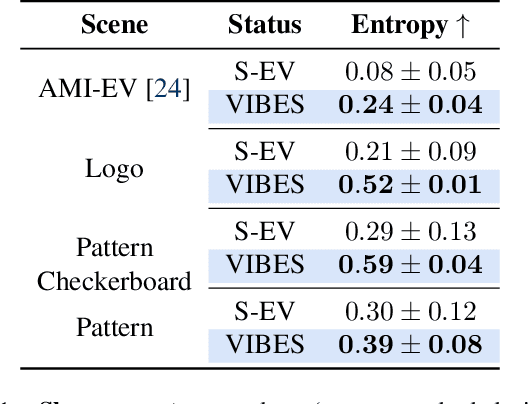
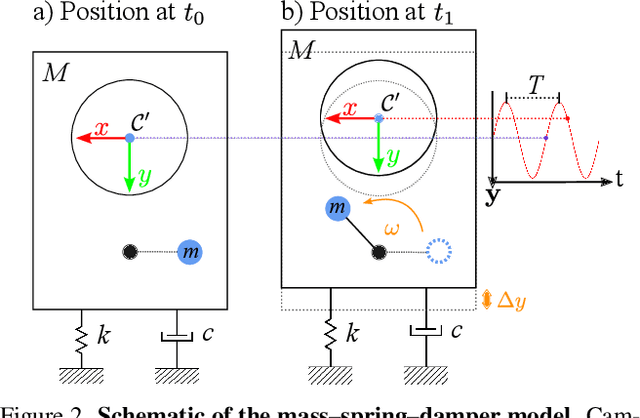
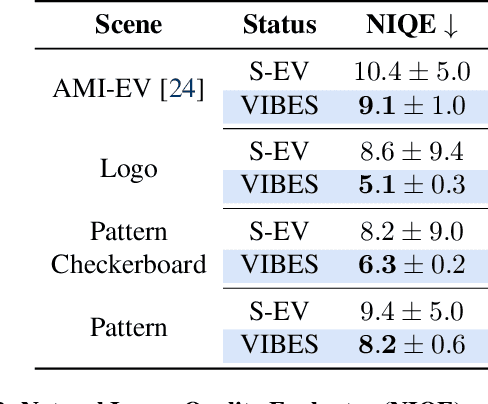
Event cameras are a bio-inspired class of sensors that asynchronously measure per-pixel intensity changes. Under fixed illumination conditions in static or low-motion scenes, rigidly mounted event cameras are unable to generate any events, becoming unsuitable for most computer vision tasks. To address this limitation, recent work has investigated motion-induced event stimulation that often requires complex hardware or additional optical components. In contrast, we introduce a lightweight approach to sustain persistent event generation by employing a simple rotating unbalanced mass to induce periodic vibrational motion. This is combined with a motion-compensation pipeline that removes the injected motion and yields clean, motion-corrected events for downstream perception tasks. We demonstrate our approach with a hardware prototype and evaluate it on real-world captured datasets. Our method reliably recovers motion parameters and improves both image reconstruction and edge detection over event-based sensing without motion induction.
Learning Cross-Spectral Point Features with Task-Oriented Training
May 19, 2025Unmanned aerial vehicles (UAVs) enable operations in remote and hazardous environments, yet the visible-spectrum, camera-based navigation systems often relied upon by UAVs struggle in low-visibility conditions. Thermal cameras, which capture long-wave infrared radiation, are able to function effectively in darkness and smoke, where visible-light cameras fail. This work explores learned cross-spectral (thermal-visible) point features as a means to integrate thermal imagery into established camera-based navigation systems. Existing methods typically train a feature network's detection and description outputs directly, which often focuses training on image regions where thermal and visible-spectrum images exhibit similar appearance. Aiming to more fully utilize the available data, we propose a method to train the feature network on the tasks of matching and registration. We run our feature network on thermal-visible image pairs, then feed the network response into a differentiable registration pipeline. Losses are applied to the matching and registration estimates of this pipeline. Our selected model, trained on the task of matching, achieves a registration error (corner error) below 10 pixels for more than 75% of estimates on the MultiPoint dataset. We further demonstrate that our model can also be used with a classical pipeline for matching and registration.
Risk-Averse Traversal of Graphs with Stochastic and Correlated Edge Costs for Safe Global Planetary Mobility
May 19, 2025In robotic planetary surface exploration, strategic mobility planning is an important task that involves finding candidate long-distance routes on orbital maps and identifying segments with uncertain traversability. Then, expert human operators establish safe, adaptive traverse plans based on the actual navigation difficulties encountered in these uncertain areas. In this paper, we formalize this challenge as a new, risk-averse variant of the Canadian Traveller Problem (CTP) tailored to global planetary mobility. The objective is to find a traverse policy minimizing a conditional value-at-risk (CVaR) criterion, which is a risk measure with an intuitive interpretation. We propose a novel search algorithm that finds exact CVaR-optimal policies. Our approach leverages well-established optimal AND-OR search techniques intended for (risk-agnostic) expectation minimization and extends these methods to the risk-averse domain. We validate our approach through simulated long-distance planetary surface traverses; we employ real orbital maps of the Martian surface to construct problem instances and use terrain maps to express traversal probabilities in uncertain regions. Our results illustrate different adaptive decision-making schemes depending on the level of risk aversion. Additionally, our problem setup allows accounting for traversability correlations between similar areas of the environment. In such a case, we empirically demonstrate how information-seeking detours can mitigate risk.
Structured Pneumatic Fingerpads for Actively Tunable Grip Friction
Feb 02, 2025
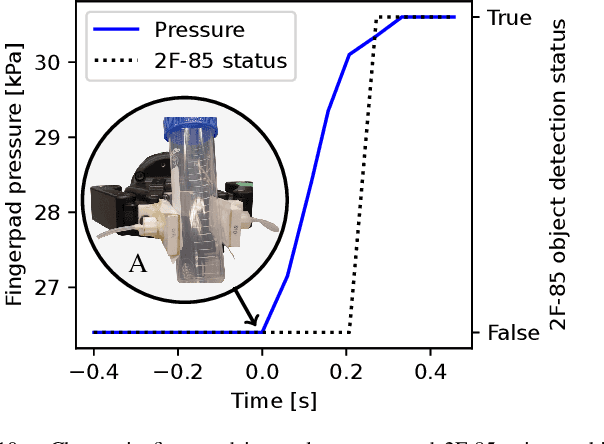
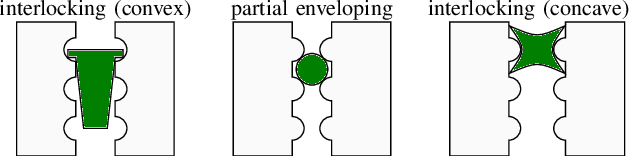
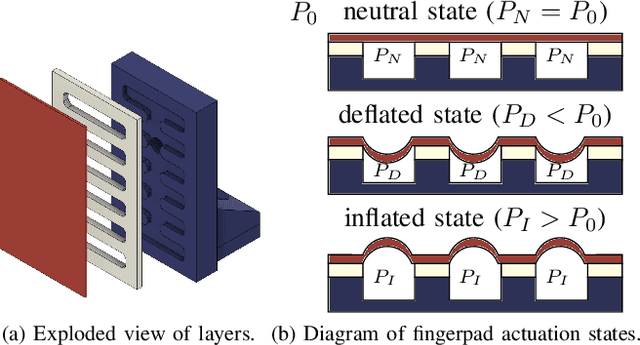
Grip surfaces with tunable friction can actively modify contact conditions, enabling transitions between higher- and lower-friction states for grasp adjustment. Friction can be increased to grip securely and then decreased to gently release (e.g., for handovers) or manipulate in-hand. Recent friction-tuning surface designs using soft pneumatic chambers show good control over grip friction; however, most require complex fabrication processes and/or custom gripper hardware. We present a practical structured fingerpad design for friction tuning that uses less than \$1 USD of materials, takes only seconds to repair, and is easily adapted to existing grippers. Our design uses surface morphology changes to tune friction. The fingerpad is actuated by pressurizing its internal chambers, thereby deflecting its flexible grip surface out from or into these chambers. We characterize the friction-tuning capabilities of our design by measuring the shear force required to pull an object from a gripper equipped with two independently actuated fingerpads. Our results show that varying actuation pressure and timing changes the magnitude of friction forces on a gripped object by up to a factor of 2.8. We demonstrate additional features including macro-scale interlocking behaviour and pressure-based object detection.
FlowCLAS: Enhancing Normalizing Flow Via Contrastive Learning For Anomaly Segmentation
Nov 29, 2024



Anomaly segmentation is a valuable computer vision task for safety-critical applications that need to be aware of unexpected events. Current state-of-the-art (SOTA) scene-level anomaly segmentation approaches rely on diverse inlier class labels during training, limiting their ability to leverage vast unlabeled datasets and pre-trained vision encoders. These methods may underperform in domains with reduced color diversity and limited object classes. Conversely, existing unsupervised methods struggle with anomaly segmentation with the diverse scenes of less restricted domains. To address these challenges, we introduce FlowCLAS, a novel self-supervised framework that utilizes vision foundation models to extract rich features and employs a normalizing flow network to learn their density distribution. We enhance the model's discriminative power by incorporating Outlier Exposure and contrastive learning in the latent space. FlowCLAS significantly outperforms all existing methods on the ALLO anomaly segmentation benchmark for space robotics and demonstrates competitive results on multiple road anomaly segmentation benchmarks for autonomous driving, including Fishyscapes Lost&Found and Road Anomaly. These results highlight FlowCLAS's effectiveness in addressing the unique challenges of space anomaly segmentation while retaining SOTA performance in the autonomous driving domain without reliance on inlier segmentation labels.
Robustness Assessment of Static Structures for Efficient Object Handling
Nov 14, 2024



This work establishes a solution to the problem of assessing the robustness of multi-object assemblies to external forces. Our physically-grounded approach handles arbitrary static structures made from rigid objects of any shape and mass distribution without relying on heuristics or approximations. The result is a method that provides a foundation for autonomous robot decision-making when interacting with objects in frictional contact. Our strategy decouples slipping from toppling, enabling independent assessments of these two phenomena, with a shared robustness representation being key to combining the results into an accurate robustness assessment. Our algorithms can be used by motion planners to produce efficient assembly transportation plans, and by object placement planners to select poses that improve the strength of an assembly. Compared to prior work, our approach is more generally applicable than commonly used heuristics and more efficient than dynamics simulations.
Automated Planning Domain Inference for Task and Motion Planning
Oct 21, 2024
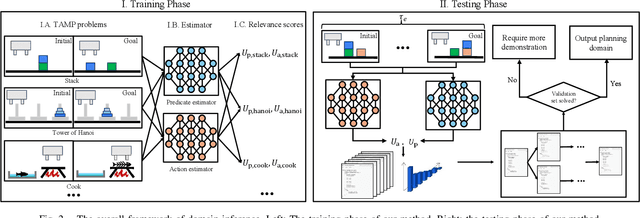
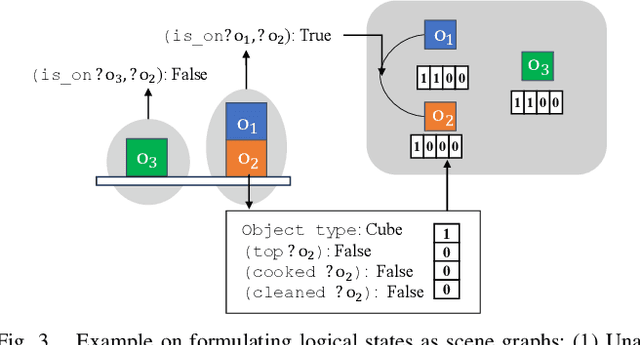
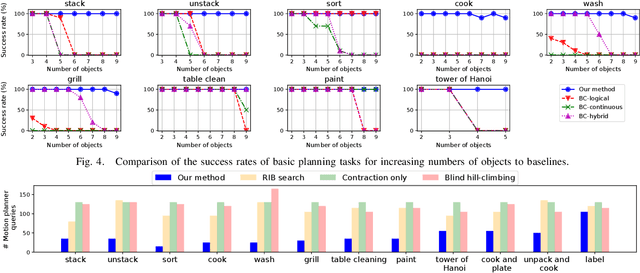
Task and motion planning (TAMP) frameworks address long and complex planning problems by integrating high-level task planners with low-level motion planners. However, existing TAMP methods rely heavily on the manual design of planning domains that specify the preconditions and postconditions of all high-level actions. This paper proposes a method to automate planning domain inference from a handful of test-time trajectory demonstrations, reducing the reliance on human design. Our approach incorporates a deep learning-based estimator that predicts the appropriate components of a domain for a new task and a search algorithm that refines this prediction, reducing the size and ensuring the utility of the inferred domain. Our method is able to generate new domains from minimal demonstrations at test time, enabling robots to handle complex tasks more efficiently. We demonstrate that our approach outperforms behavior cloning baselines, which directly imitate planner behavior, in terms of planning performance and generalization across a variety of tasks. Additionally, our method reduces computational costs and data amount requirements at test time for inferring new planning domains.
Stable Object Placement Planning From Contact Point Robustness
Oct 16, 2024
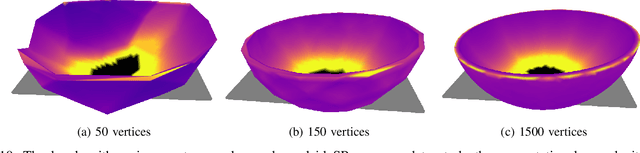
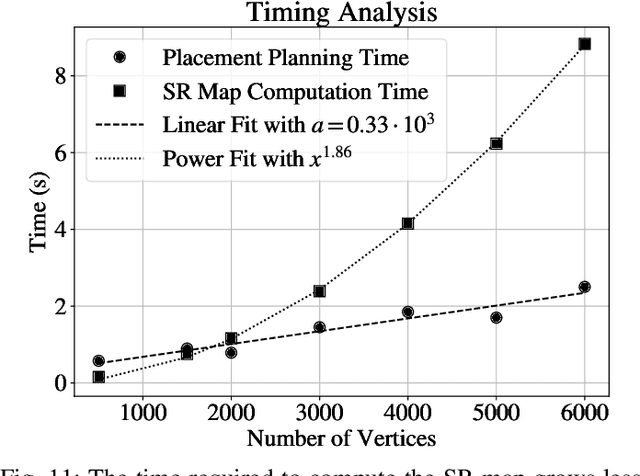
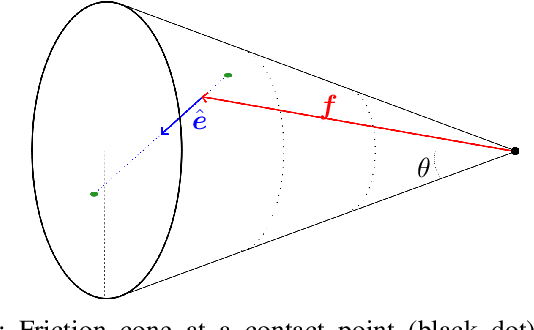
We introduce a planner designed to guide robot manipulators in stably placing objects within intricate scenes. Our proposed method reverses the traditional approach to object placement: our planner selects contact points first and then determines a placement pose that solicits the selected points. This is instead of sampling poses, identifying contact points, and evaluating pose quality. Our algorithm facilitates stability-aware object placement planning, imposing no restrictions on object shape, convexity, or mass density homogeneity, while avoiding combinatorial computational complexity. Our proposed stability heuristic enables our planner to find a solution about 20 times faster when compared to the same algorithm not making use of the heuristic and eight times faster than a state-of-the-art method that uses the traditional sample-and-evaluate approach. Our proposed planner is also more successful in finding stable placements than the five other benchmarked algorithms. Derived from first principles and validated in ten real robot experiments, our planner offers a general and scalable method to tackle the problem of object placement planning with rigid objects.
ALLO: A Photorealistic Dataset and Data Generation Pipeline for Anomaly Detection During Robotic Proximity Operations in Lunar Orbit
Sep 30, 2024



NASA's forthcoming Lunar Gateway space station, which will be uncrewed most of the time, will need to operate with an unprecedented level of autonomy. Enhancing autonomy on the Gateway presents several unique challenges, one of which is to equip the Canadarm3, the Gateway's external robotic system, with the capability to perform worksite monitoring. Monitoring will involve using the arm's inspection cameras to detect any anomalies within the operating environment, a task complicated by the widely-varying lighting conditions in space. In this paper, we introduce the visual anomaly detection and localization task for space applications and establish a benchmark with our novel synthetic dataset called ALLO (for Anomaly Localization in Lunar Orbit). We develop a complete data generation pipeline to create ALLO, which we use to evaluate the performance of state-of-the-art visual anomaly detection algorithms. Given the low tolerance for risk during space operations and the lack of relevant data, we emphasize the need for novel, robust, and accurate anomaly detection methods to handle the challenging visual conditions found in lunar orbit and beyond.