 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Execution Horizon Prediction for Chunk-based Robot Policies
Jun 09, 2026Action chunking has become a standard design in modern robot policies, from diffusion/flow policies to vision-language-action models, where the policy predicts a sequence of actions and executes a fixed number of them instead of acting one step at a time. However, this paradigm relies on a key assumption: a fixed execution horizon. During chunk execution, the policy operates open-loop, which is particularly problematic for fine-grained manipulation tasks that require frequent replanning. In practice, the execution horizon is typically chosen through empirical tuning and is highly task-dependent. To this end, we propose Dynamic Execution Horizon Prediction (DEHP), an effective method that trains a lightweight execution-horizon prediction branch using online reinforcement learning while keeping the pretrained chunk policy completely frozen. This makes the method compatible with black-box chunk policies and isolates the effect of adapting the execution horizon from changes to the underlying action generator. Across our evaluations, DEHP improves the success rate of different high-precision and long-horizon manipulation tasks by a large margin. Our qualitative analysis further shows that DEHP predicts shorter execution horizons during fine-grained stages of the task and longer horizons during free-space motion. In this way, DEHP balances the efficiency of open-loop chunk execution with the reactivity of closed-loop single-step control. Project page: https://dehp-chunking.github.io/
MATTERIX: toward a digital twin for robotics-assisted chemistry laboratory automation
Jan 19, 2026Accelerated materials discovery is critical for addressing global challenges. However, developing new laboratory workflows relies heavily on real-world experimental trials, and this can hinder scalability because of the need for numerous physical make-and-test iterations. Here we present MATTERIX, a multiscale, graphics processing unit-accelerated robotic simulation framework designed to create high-fidelity digital twins of chemistry laboratories, thus accelerating workflow development. This multiscale digital twin simulates robotic physical manipulation, powder and liquid dynamics, device functionalities, heat transfer and basic chemical reaction kinetics. This is enabled by integrating realistic physics simulation and photorealistic rendering with a modular graphics processing unit-accelerated semantics engine, which models logical states and continuous behaviors to simulate chemistry workflows across different levels of abstraction. MATTERIX streamlines the creation of digital twin environments through open-source asset libraries and interfaces, while enabling flexible workflow design via hierarchical plan definition and a modular skill library that incorporates learning-based methods. Our approach demonstrates sim-to-real transfer in robotic chemistry setups, reducing reliance on costly real-world experiments and enabling the testing of hypothetical automated workflows in silico. The project website is available at https://accelerationconsortium.github.io/Matterix/ .
AnyPlace: Learning Generalized Object Placement for Robot Manipulation
Feb 06, 2025Object placement in robotic tasks is inherently challenging due to the diversity of object geometries and placement configurations. To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models. We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle -- such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement. More at: https://any-place.github.io.
Automated Planning Domain Inference for Task and Motion Planning
Oct 21, 2024
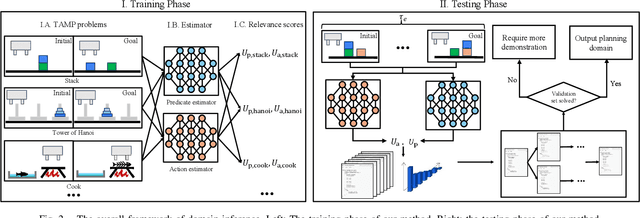
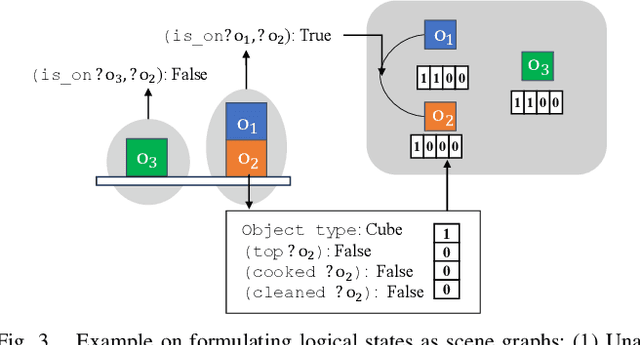
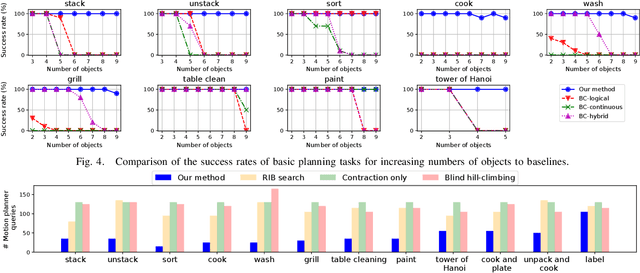
Task and motion planning (TAMP) frameworks address long and complex planning problems by integrating high-level task planners with low-level motion planners. However, existing TAMP methods rely heavily on the manual design of planning domains that specify the preconditions and postconditions of all high-level actions. This paper proposes a method to automate planning domain inference from a handful of test-time trajectory demonstrations, reducing the reliance on human design. Our approach incorporates a deep learning-based estimator that predicts the appropriate components of a domain for a new task and a search algorithm that refines this prediction, reducing the size and ensuring the utility of the inferred domain. Our method is able to generate new domains from minimal demonstrations at test time, enabling robots to handle complex tasks more efficiently. We demonstrate that our approach outperforms behavior cloning baselines, which directly imitate planner behavior, in terms of planning performance and generalization across a variety of tasks. Additionally, our method reduces computational costs and data amount requirements at test time for inferring new planning domains.
CLIMB: Language-Guided Continual Learning for Task Planning with Iterative Model Building
Oct 17, 2024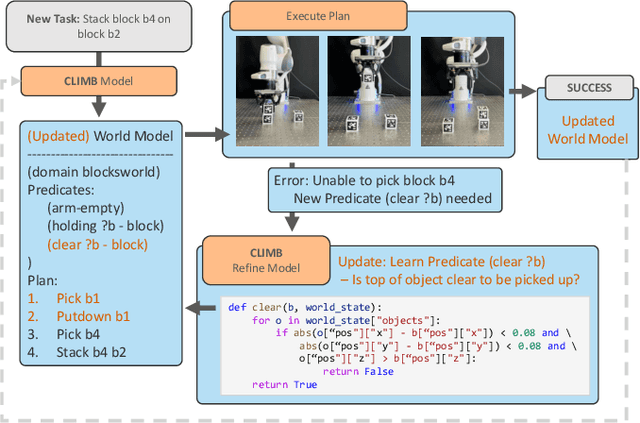
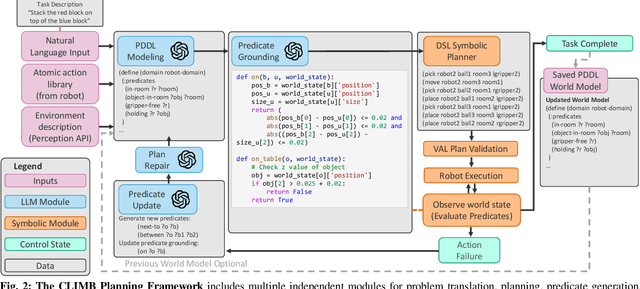
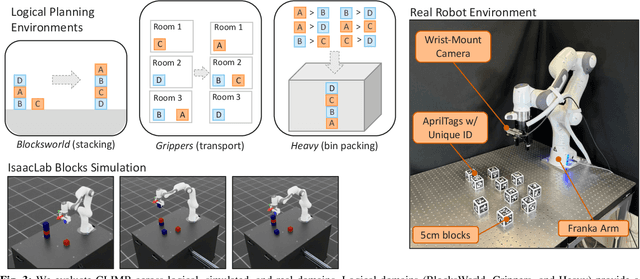
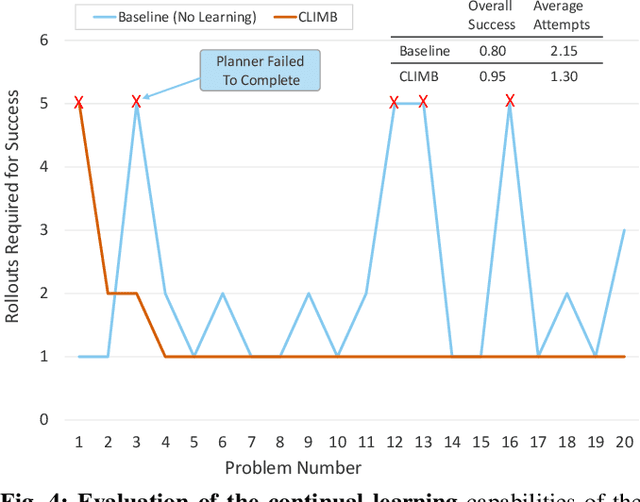
Intelligent and reliable task planning is a core capability for generalized robotics, requiring a descriptive domain representation that sufficiently models all object and state information for the scene. We present CLIMB, a continual learning framework for robot task planning that leverages foundation models and execution feedback to guide domain model construction. CLIMB can build a model from a natural language description, learn non-obvious predicates while solving tasks, and store that information for future problems. We demonstrate the ability of CLIMB to improve performance in common planning environments compared to baseline methods. We also develop the BlocksWorld++ domain, a simulated environment with an easily usable real counterpart, together with a curriculum of tasks with progressing difficulty for evaluating continual learning. Additional details and demonstrations for this system can be found at https://plan-with-climb.github.io/ .
ORGANA: A Robotic Assistant for Automated Chemistry Experimentation and Characterization
Jan 13, 2024



Chemistry experimentation is often resource- and labor-intensive. Despite the many benefits incurred by the integration of advanced and special-purpose lab equipment, many aspects of experimentation are still manually conducted by chemists, for example, polishing an electrode in electrochemistry experiments. Traditional lab automation infrastructure faces challenges when it comes to flexibly adapting to new chemistry experiments. To address this issue, we propose a human-friendly and flexible robotic system, ORGANA, that automates a diverse set of chemistry experiments. It is capable of interacting with chemists in the lab through natural language, using Large Language Models (LLMs). ORGANA keeps scientists informed by providing timely reports that incorporate statistical analyses. Additionally, it actively engages with users when necessary for disambiguation or troubleshooting. ORGANA can reason over user input to derive experiment goals, and plan long sequences of both high-level tasks and low-level robot actions while using feedback from the visual perception of the environment. It also supports scheduling and parallel execution for experiments that require resource allocation and coordination between multiple robots and experiment stations. We show that ORGANA successfully conducts a diverse set of chemistry experiments, including solubility assessment, pH measurement, recrystallization, and electrochemistry experiments. For the latter, we show that ORGANA robustly executes a long-horizon plan, comprising 19 steps executed in parallel, to characterize the electrochemical properties of quinone derivatives, a class of molecules used in rechargeable flow batteries. Our user study indicates that ORGANA significantly improves many aspects of user experience while reducing their physical workload. More details about ORGANA can be found at https://ac-rad.github.io/organa/.
Model-free Reinforcement Learning for Robust Locomotion Using Trajectory Optimization for Exploration
Jul 14, 2021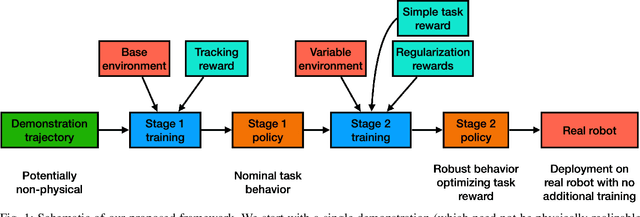

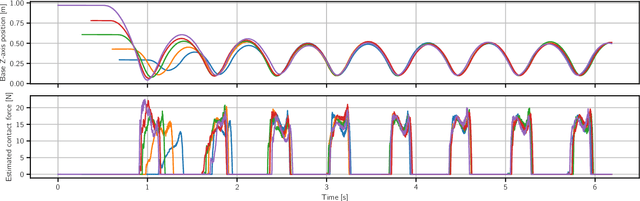
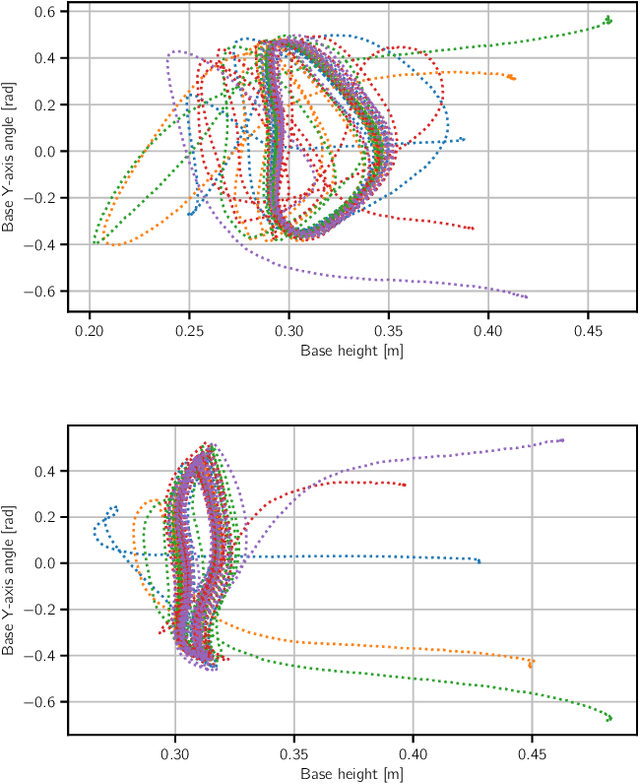
In this work we present a general, two-stage reinforcement learning approach for going from a single demonstration trajectory to a robust policy that can be deployed on hardware without any additional training. The demonstration is used in the first stage as a starting point to facilitate initial exploration. In the second stage, the relevant task reward is optimized directly and a policy robust to environment uncertainties is computed. We demonstrate and examine in detail performance and robustness of our approach on highly dynamic hopping and bounding tasks on a real quadruped robot.
TriFinger: An Open-Source Robot for Learning Dexterity
Aug 08, 2020



Dexterous object manipulation remains an open problem in robotics, despite the rapid progress in machine learning during the past decade. We argue that a hindrance is the high cost of experimentation on real systems, in terms of both time and money. We address this problem by proposing an open-source robotic platform which can safely operate without human supervision. The hardware is inexpensive (about \SI{5000}[\$]{}) yet highly dynamic, robust, and capable of complex interaction with external objects. The software operates at 1-kilohertz and performs safety checks to prevent the hardware from breaking. The easy-to-use front-end (in C++ and Python) is suitable for real-time control as well as deep reinforcement learning. In addition, the software framework is largely robot-agnostic and can hence be used independently of the hardware proposed herein. Finally, we illustrate the potential of the proposed platform through a number of experiments, including real-time optimal control, deep reinforcement learning from scratch, throwing, and writing.
Learning to Explore in Motion and Interaction Tasks
Aug 10, 2019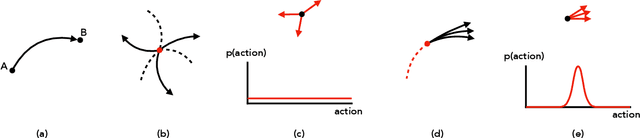
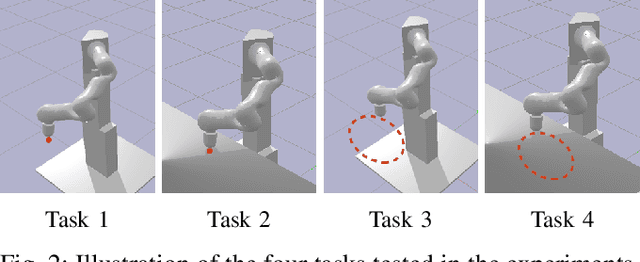
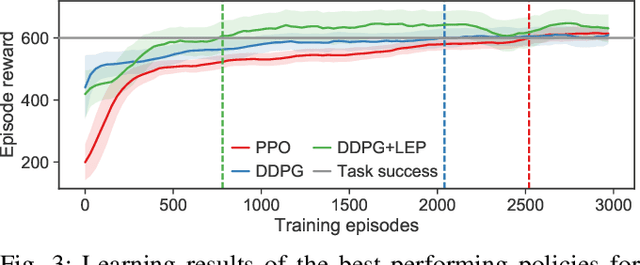
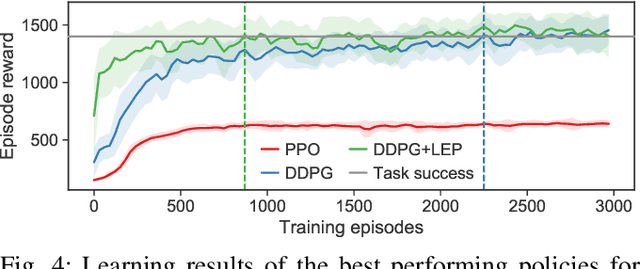
Model free reinforcement learning suffers from the high sampling complexity inherent to robotic manipulation or locomotion tasks. Most successful approaches typically use random sampling strategies which leads to slow policy convergence. In this paper we present a novel approach for efficient exploration that leverages previously learned tasks. We exploit the fact that the same system is used across many tasks and build a generative model for exploration based on data from previously solved tasks to improve learning new tasks. The approach also enables continuous learning of improved exploration strategies as novel tasks are learned. Extensive simulations on a robot manipulator performing a variety of motion and contact interaction tasks demonstrate the capabilities of the approach. In particular, our experiments suggest that the exploration strategy can more than double learning speed, especially when rewards are sparse. Moreover, the algorithm is robust to task variations and parameter tuning, making it beneficial for complex robotic problems.
Learning Variable Impedance Control for Contact Sensitive Tasks
Jul 17, 2019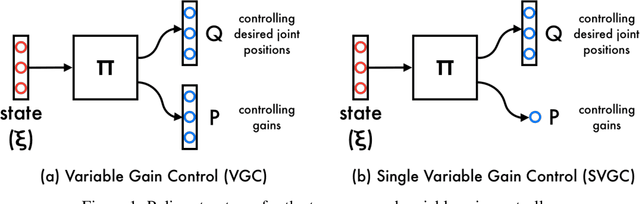


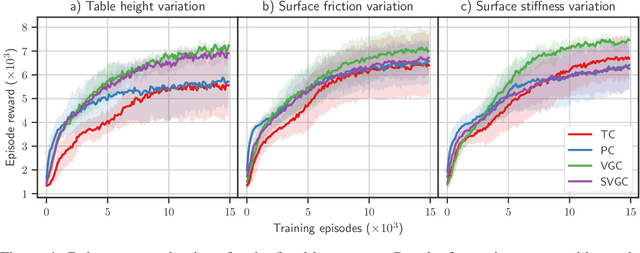
Reinforcement learning algorithms have shown great success in solving different problems ranging from playing video games to robotics. However, they struggle to solve delicate robotic problems, especially those involving contact interactions. Though in principle a policy outputting joint torques should be able to learn these tasks, in practice we see that they have difficulty to robustly solve the problem without any structure in the action space. In this paper, we investigate how the choice of action space can give robust performance in presence of contact uncertainties. We propose to learn a policy that outputs impedance and desired position in joint space as a function of system states without imposing any other structure to the problem. We compare the performance of this approach to torque and position control policies under different contact uncertainties. Extensive simulation results on two different systems, a hopper (floating-base) with intermittent contacts and a manipulator (fixed-base) wiping a table, show that our proposed approach outperforms policies outputting torque or position in terms of both learning rate and robustness to environment uncertainty.