 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Open-source Tendon-driven Robot Arm for Learning Control of Dynamic Motions
Jul 10, 2023



A long-lasting goal of robotics research is to operate robots safely, while achieving high performance which often involves fast motions. Traditional motor-driven systems frequently struggle to balance these competing demands. Addressing this trade-off is crucial for advancing fields such as manufacturing and healthcare, where seamless collaboration between robots and humans is essential. We introduce a four degree-of-freedom (DoF) tendon-driven robot arm, powered by pneumatic artificial muscles (PAMs), to tackle this challenge. Our new design features low friction, passive compliance, and inherent impact resilience, enabling rapid, precise, high-force, and safe interactions during dynamic tasks. In addition to fostering safer human-robot collaboration, the inherent safety properties are particularly beneficial for reinforcement learning, where the robot's ability to explore dynamic motions without causing self-damage is crucial. We validate our robotic arm through various experiments, including long-term dynamic motions, impact resilience tests, and assessments of its ease of control. On a challenging dynamic table tennis task, we further demonstrate our robot's capabilities in rapid and precise movements. By showcasing our new design's potential, we aim to inspire further research on robotic systems that balance high performance and safety in diverse tasks. Our open-source hardware design, software, and a large dataset of diverse robot motions can be found at https://webdav.tuebingen.mpg.de/pamy2/.
Synchronizing Machine Learning Algorithms, Realtime Robotic Control and Simulated Environment with o80
Jun 16, 2023Robotic applications require the integration of various modalities, encompassing perception, control of real robots and possibly the control of simulated environments. While the state-of-the-art robotic software solutions such as ROS 2 provide most of the required features, flexible synchronization between algorithms, data streams and control loops can be tedious. o80 is a versatile C++ framework for robotics which provides a shared memory model and a command framework for real-time critical systems. It enables expert users to set up complex robotic systems and generate Python bindings for scientists. o80's unique feature is its flexible synchronization between processes, including the traditional blocking commands and the novel ``bursting mode'', which allows user code to control the execution of the lower process control loop. This makes it particularly useful for setups that mix real and simulated environments.
Hindsight States: Blending Sim and Real Task Elements for Efficient Reinforcement Learning
Mar 09, 2023Reinforcement learning has shown great potential in solving complex tasks when large amounts of data can be generated with little effort. In robotics, one approach to generate training data builds on simulations based on dynamics models derived from first principles. However, for tasks that, for instance, involve complex soft robots, devising such models is substantially more challenging. Being able to train effectively in increasingly complicated scenarios with reinforcement learning enables to take advantage of complex systems such as soft robots. Here, we leverage the imbalance in complexity of the dynamics to learn more sample-efficiently. We (i) abstract the task into distinct components, (ii) off-load the simple dynamics parts into the simulation, and (iii) multiply these virtual parts to generate more data in hindsight. Our new method, Hindsight States (HiS), uses this data and selects the most useful transitions for training. It can be used with an arbitrary off-policy algorithm. We validate our method on several challenging simulated tasks and demonstrate that it improves learning both alone and when combined with an existing hindsight algorithm, Hindsight Experience Replay (HER). Finally, we evaluate HiS on a physical system and show that it boosts performance on a complex table tennis task with a muscular robot. Videos and code of the experiments can be found on webdav.tuebingen.mpg.de/his/.
Learning Event-triggered Control from Data through Joint Optimization
Aug 11, 2020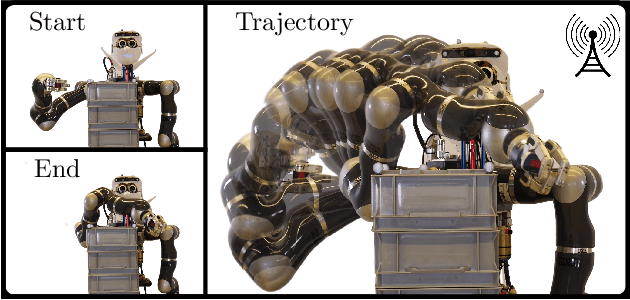
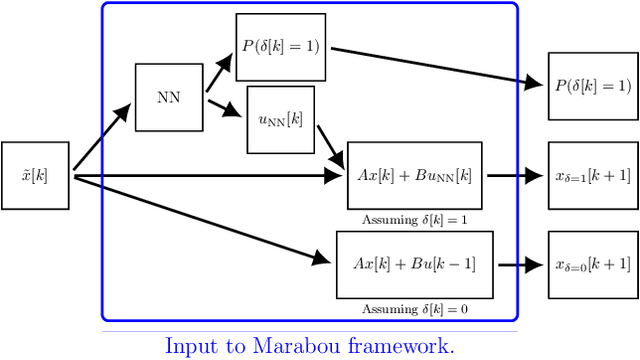
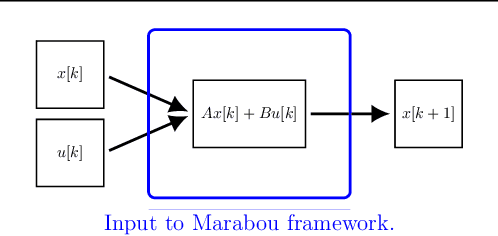
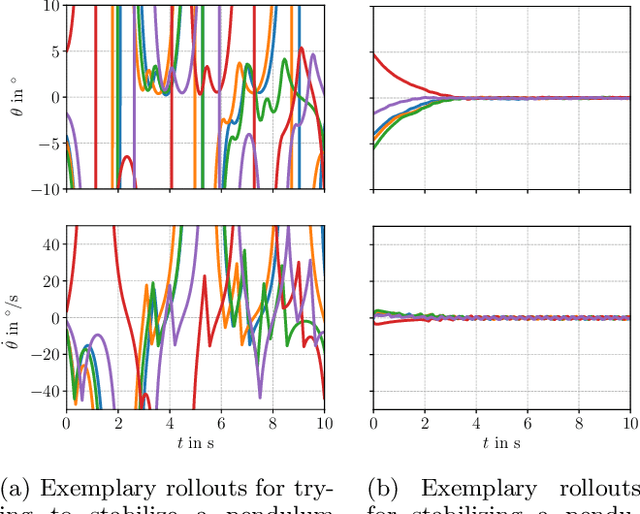
We present a framework for model-free learning of event-triggered control strategies. Event-triggered methods aim to achieve high control performance while only closing the feedback loop when needed. This enables resource savings, e.g., network bandwidth if control commands are sent via communication networks, as in networked control systems. Event-triggered controllers consist of a communication policy, determining when to communicate, and a control policy, deciding what to communicate. It is essential to jointly optimize the two policies since individual optimization does not necessarily yield the overall optimal solution. To address this need for joint optimization, we propose a novel algorithm based on hierarchical reinforcement learning. The resulting algorithm is shown to accomplish high-performance control in line with resource savings and scales seamlessly to nonlinear and high-dimensional systems. The method's applicability to real-world scenarios is demonstrated through experiments on a six degrees of freedom real-time controlled manipulator. Further, we propose an approach towards evaluating the stability of the learned neural network policies.
TriFinger: An Open-Source Robot for Learning Dexterity
Aug 08, 2020



Dexterous object manipulation remains an open problem in robotics, despite the rapid progress in machine learning during the past decade. We argue that a hindrance is the high cost of experimentation on real systems, in terms of both time and money. We address this problem by proposing an open-source robotic platform which can safely operate without human supervision. The hardware is inexpensive (about \SI{5000}[\$]{}) yet highly dynamic, robust, and capable of complex interaction with external objects. The software operates at 1-kilohertz and performs safety checks to prevent the hardware from breaking. The easy-to-use front-end (in C++ and Python) is suitable for real-time control as well as deep reinforcement learning. In addition, the software framework is largely robot-agnostic and can hence be used independently of the hardware proposed herein. Finally, we illustrate the potential of the proposed platform through a number of experiments, including real-time optimal control, deep reinforcement learning from scratch, throwing, and writing.
Learning to Play Table Tennis From Scratch using Muscular Robots
Jun 10, 2020
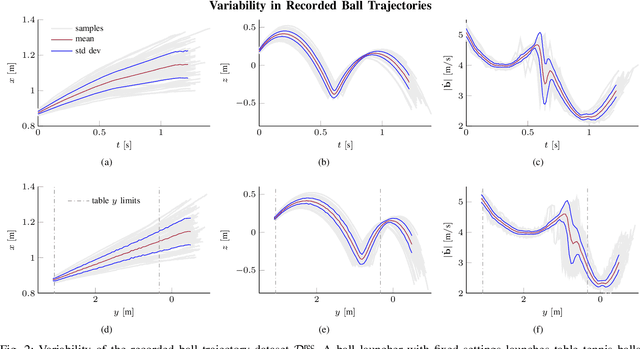
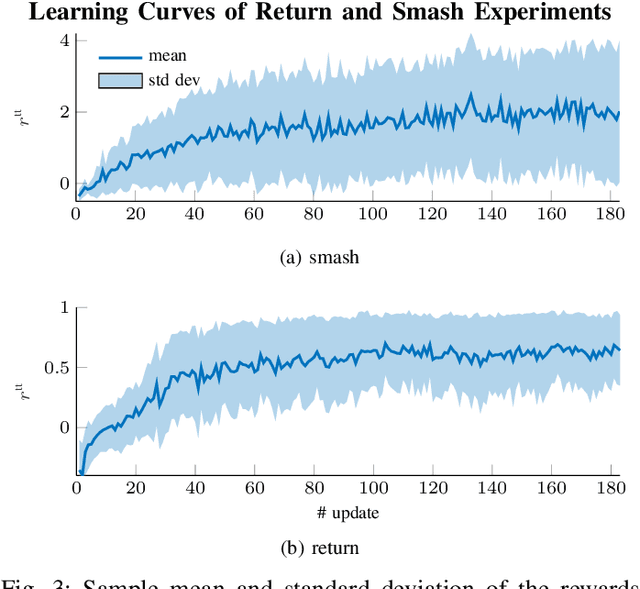
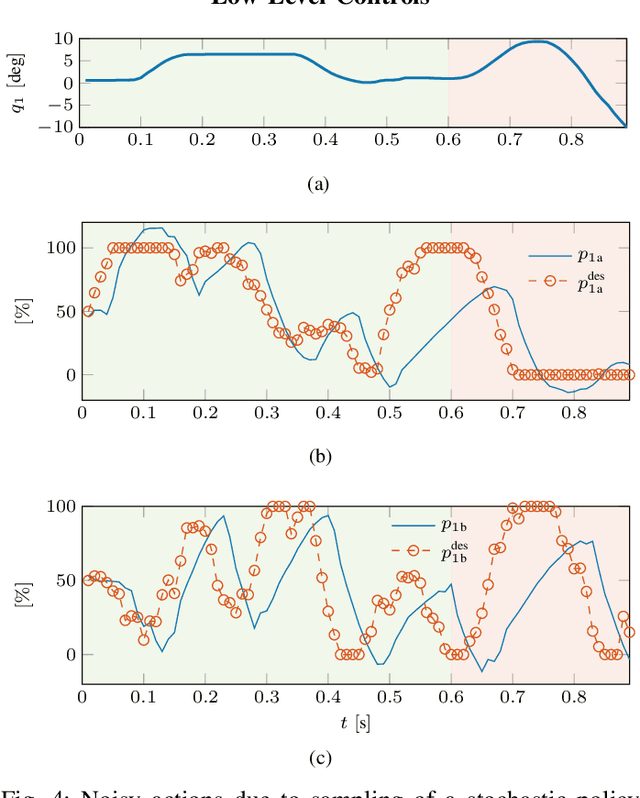
Dynamic tasks like table tennis are relatively easy to learn for humans but pose significant challenges to robots. Such tasks require accurate control of fast movements and precise timing in the presence of imprecise state estimation of the flying ball and the robot. Reinforcement Learning (RL) has shown promise in learning of complex control tasks from data. However, applying step-based RL to dynamic tasks on real systems is safety-critical as RL requires exploring and failing safely for millions of time steps in high-speed regimes. In this paper, we demonstrate that safe learning of table tennis using model-free Reinforcement Learning can be achieved by using robot arms driven by pneumatic artificial muscles (PAMs). Softness and back-drivability properties of PAMs prevent the system from leaving the safe region of its state space. In this manner, RL empowers the robot to return and smash real balls with 5 m\s and 12m\s on average to a desired landing point. Our setup allows the agent to learn this safety-critical task (i) without safety constraints in the algorithm, (ii) while maximizing the speed of returned balls directly in the reward function (iii) using a stochastic policy that acts directly on the low-level controls of the real system and (iv) trains for thousands of trials (v) from scratch without any prior knowledge. Additionally, we present HYSR, a practical hybrid sim and real training that avoids playing real balls during training by randomly replaying recorded ball trajectories in simulation and applying actions to the real robot. This work is the first to (a) fail-safe learn of a safety-critical dynamic task using anthropomorphic robot arms, (b) learn a precision-demanding problem with a PAM-driven system despite the control challenges and (c) train robots to play table tennis without real balls. Videos and datasets are available at muscularTT.embodied.ml.
Safe and Fast Tracking Control on a Robot Manipulator: Robust MPC and Neural Network Control
Dec 22, 2019
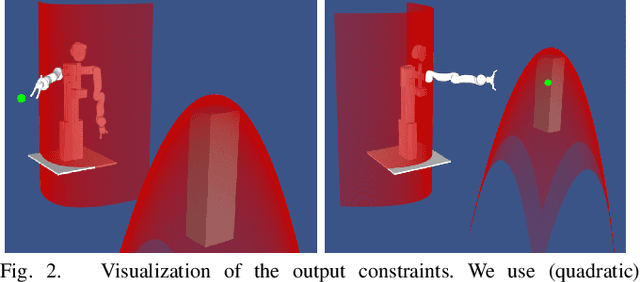
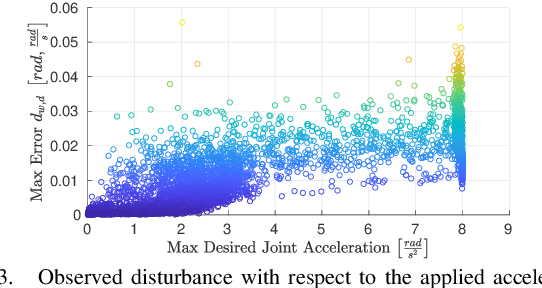
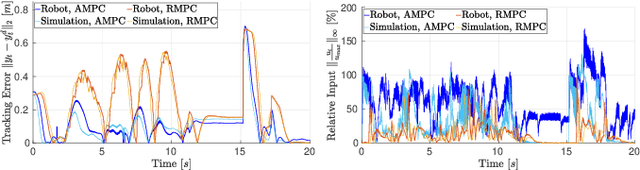
Fast feedback control and safety guarantees are essential in modern robotics. We present an approach that achieves both by combining novel robust model predictive control (MPC) with function approximation via (deep) neural networks (NNs). The result is a new approach for complex tasks with nonlinear, uncertain, and constrained dynamics as are common in robotics. Specifically, we leverage recent results in MPC research to propose a new robust setpoint tracking MPC algorithm, which achieves reliable and safe tracking of a dynamic setpoint while guaranteeing stability and constraint satisfaction. The presented robust MPC scheme constitutes a one-layer approach that unifies the often separated planning and control layers, by directly computing the control command based on a reference and possibly obstacle positions. As a separate contribution, we show how the computation time of the MPC can be drastically reduced by approximating the MPC law with a NN controller. The NN is trained and validated from offline samples of the MPC, yielding statistical guarantees, and used in lieu thereof at run time. Our experiments on a state-of-the-art robot manipulator are the first to show that both the proposed robust and approximate MPC schemes scale to real-world robotic systems.
An Open Torque-Controlled Modular Robot Architecture for Legged Locomotion Research
Sep 30, 2019

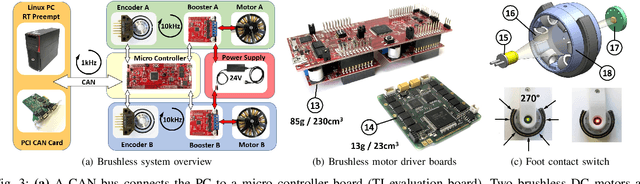
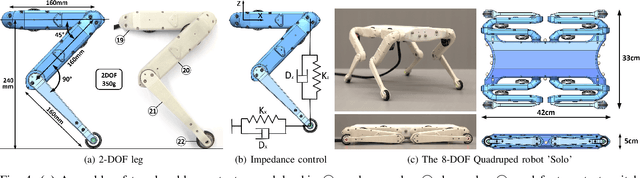
We present a new open-source torque-controlled legged robot system, with a low cost and low complexity actuator module at its core. It consists of a low-weight high torque brushless DC motor and a low gear ratio transmission suitable for impedance and force control. We also present a novel foot contact sensor suitable for legged locomotion with hard impacts. A 2.2 kg quadruped robot with a large range of motion is assembled from 8 identical actuator modules and 4 lower legs with foot contact sensors. To the best of our knowledge, it is the most lightest force-controlled quadruped robot. We leverage standard plastic 3D printing and off-the-shelf parts, resulting in light-weight and inexpensive robots, allowing for rapid distribution and duplication within the research community. In order to quantify the capabilities of our design, we systematically measure the achieved impedance at the foot in static and dynamic scenarios. We measured up to 10.8 dimensionless leg stiffness without active damping, which is comparable to the leg stiffness of a running human. Finally, in order to demonstrate the capabilities of our quadruped robot, we propose a novel controller which combines feedforward contact forces computed from a kino-dynamic optimizer with impedance control of the robot center of mass and base orientation. The controller is capable of regulating complex motions which are robust to environmental uncertainty.
Automated Generation of Reactive Programs from Human Demonstration for Orchestration of Robot Behaviors
Mar 13, 2019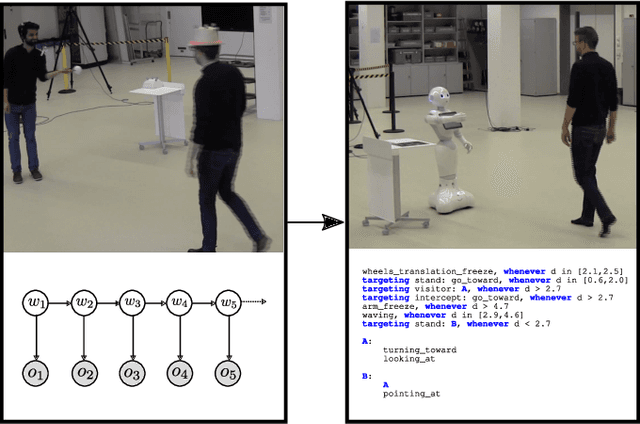
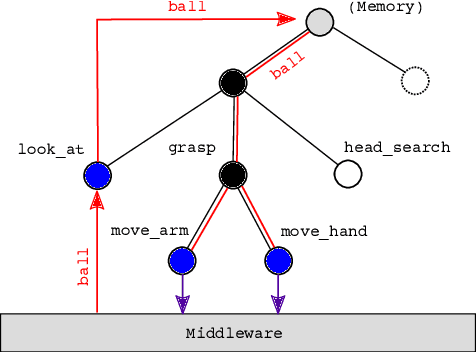
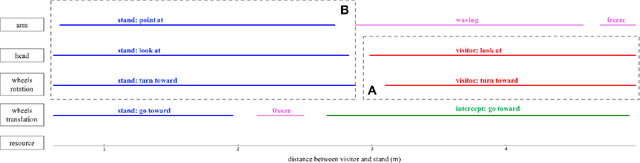

Social robots or collaborative robots that have to interact with people in a reactive way are difficult to program. This difficulty stems from the different skills required by the programmer: to provide an engaging user experience the behavior must include a sense of aesthetics while robustly operating in a continuously changing environment. The Playful framework allows composing such dynamic behaviors using a basic set of action and perception primitives. Within this framework, a behavior is encoded as a list of declarative statements corresponding to high-level sensory-motor couplings. To facilitate non-expert users to program such behaviors, we propose a Learning from Demonstration (LfD) technique that maps motion capture of humans directly to a Playful script. The approach proceeds by identifying the sensory-motor couplings that are active at each step using the Viterbi path in a Hidden Markov Model (HMM). Given these activation patterns, binary classifiers called evaluations are trained to associate activations to sensory data. Modularity is increased by clustering the sensory-motor couplings, leading to a hierarchical tree structure. The novelty of the proposed approach is that the learned behavior is encoded not in terms of trajectories in a task space, but as couplings between sensory information and high-level motor actions. This provides advantages in terms of behavioral generalization and reactivity displayed by the robot.
Real-time Perception meets Reactive Motion Generation
Oct 06, 2017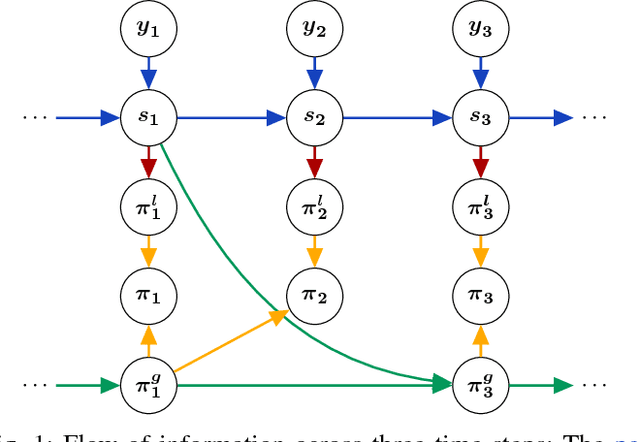



We address the challenging problem of robotic grasping and manipulation in the presence of uncertainty. This uncertainty is due to noisy sensing, inaccurate models and hard-to-predict environment dynamics. We quantify the importance of continuous, real-time perception and its tight integration with reactive motion generation methods in dynamic manipulation scenarios. We compare three different systems that are instantiations of the most common architectures in the field: (i) a traditional sense-plan-act approach that is still widely used, (ii) a myopic controller that only reacts to local environment dynamics and (iii) a reactive planner that integrates feedback control and motion optimization. All architectures rely on the same components for real-time perception and reactive motion generation to allow a quantitative evaluation. We extensively evaluate the systems on a real robotic platform in four scenarios that exhibit either a challenging workspace geometry or a dynamic environment. In 333 experiments, we quantify the robustness and accuracy that is due to integrating real-time feedback at different time scales in a reactive motion generation system. We also report on the lessons learned for system building.