 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriority-Driven Control and Communication in Decentralized Multi-Agent Systems via Reinforcement Learning
May 11, 2026Event-triggered control provides a mechanism for avoiding excessive use of constrained communication bandwidth in networked multi-agent systems. However, most existing methods rely on accurate system models, which may be unavailable in practice. In this work, we propose a model-free, priority-driven reinforcement learning algorithm that learns communication priorities and control policies jointly from data in decentralized multi-agent systems. By learning communication priorities, we circumvent the hybrid action space typical in event-triggered control with binary communication decisions. We evaluate our algorithm on benchmark tasks and demonstrate that it outperforms the baseline method.
Safe learning-based control via function-based uncertainty quantification
Apr 01, 2026Uncertainty quantification is essential when deploying learning-based control methods in safety-critical systems. This is commonly realized by constructing uncertainty tubes that enclose the unknown function of interest, e.g., the reward and constraint functions or the underlying dynamics model, with high probability. However, existing approaches for uncertainty quantification typically rely on restrictive assumptions on the unknown function, such as known bounds on functional norms or Lipschitz constants, and struggle with discontinuities. In this paper, we model the unknown function as a random function from which independent and identically distributed realizations can be generated, and construct uncertainty tubes via the scenario approach that hold with high probability and rely solely on the sampled realizations. We integrate these uncertainty tubes into a safe Bayesian optimization algorithm, which we then use to safely tune control parameters on a real Furuta pendulum.
Computationally lightweight classifiers with frequentist bounds on predictions
Mar 23, 2026While both classical and neural network classifiers can achieve high accuracy, they fall short on offering uncertainty bounds on their predictions, making them unfit for safety-critical applications. Existing kernel-based classifiers that provide such bounds scale with $\mathcal O (n^{\sim3})$ in time, making them computationally intractable for large datasets. To address this, we propose a novel, computationally efficient classification algorithm based on the Nadaraya-Watson estimator, for whose estimates we derive frequentist uncertainty intervals. We evaluate our classifier on synthetically generated data and on electrocardiographic heartbeat signals from the MIT-BIH Arrhythmia database. We show that the method achieves competitive accuracy $>$\SI{96}{\percent} at $\mathcal O(n)$ and $\mathcal O(\log n)$ operations, while providing actionable uncertainty bounds. These bounds can, e.g., aid in flagging low-confidence predictions, making them suitable for real-time settings with resource constraints, such as diagnostic monitoring or implantable devices.
Ergodicity in reinforcement learning
Mar 11, 2026In reinforcement learning, we typically aim to optimize the expected value of the sum of rewards an agent collects over a trajectory. However, if the process generating these rewards is non-ergodic, the expected value, i.e., the average over infinitely many trajectories with a given policy, is uninformative for the average over a single, but infinitely long trajectory. Thus, if we care about how the individual agent performs during deployment, the expected value is not a good optimization objective. In this paper, we discuss the impact of non-ergodic reward processes on reinforcement learning agents through an instructive example, relate the notion of ergodic reward processes to more widely used notions of ergodic Markov chains, and present existing solutions that optimize long-term performance of individual trajectories under non-ergodic reward dynamics.
Integrating Lagrangian Neural Networks into the Dyna Framework for Reinforcement Learning
Mar 09, 2026Model-based reinforcement learning (MBRL) is sample-efficient but depends on the accuracy of the learned dynamics, which are often modeled using black-box methods that do not adhere to physical laws. Those methods tend to produce inaccurate predictions when presented with data that differ from the original training set. In this work, we employ Lagrangian neural networks (LNNs), which enforce an underlying Lagrangian structure to train the model within a Dyna-based MBRL framework. Furthermore, we train the LNN using stochastic gradient-based and state-estimation-based optimizers to learn the network's weights. The state-estimation-based method converges faster than the stochastic gradient-based method during neural network training. Simulation results are provided to illustrate the effectiveness of the proposed LNN-based Dyna framework for MBRL.
Safe Bayesian optimization across noise models via scenario programming
Dec 12, 2025Safe Bayesian optimization (BO) with Gaussian processes is an effective tool for tuning control policies in safety-critical real-world systems, specifically due to its sample efficiency and safety guarantees. However, most safe BO algorithms assume homoscedastic sub-Gaussian measurement noise, an assumption that does not hold in many relevant applications. In this article, we propose a straightforward yet rigorous approach for safe BO across noise models, including homoscedastic sub-Gaussian and heteroscedastic heavy-tailed distributions. We provide a high-probability bound on the measurement noise via the scenario approach, integrate these bounds into high probability confidence intervals, and prove safety and optimality for our proposed safe BO algorithm. We deploy our algorithm in synthetic examples and in tuning a controller for the Franka Emika manipulator in simulation.
Online Bayesian Experimental Design for Partially Observed Dynamical Systems
Nov 06, 2025
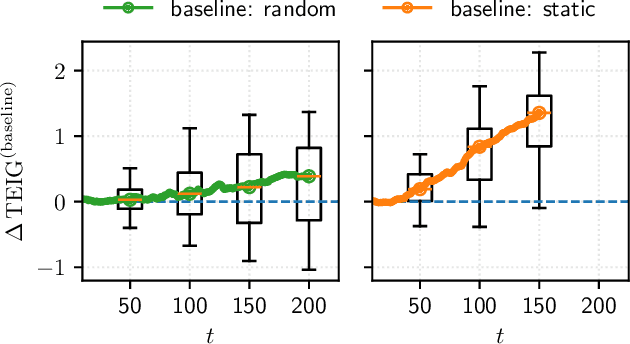
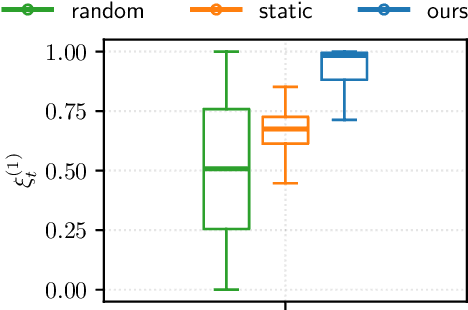
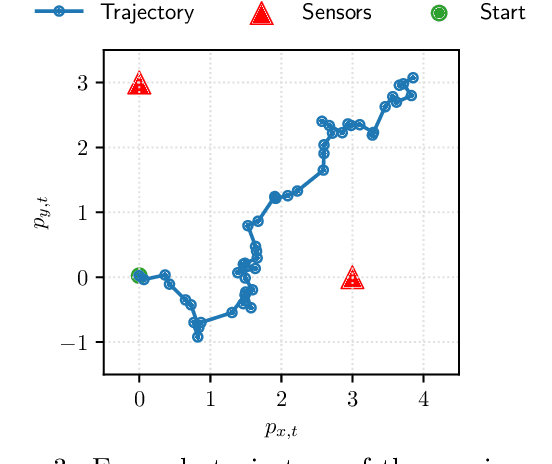
Bayesian experimental design (BED) provides a principled framework for optimizing data collection, but existing approaches do not apply to crucial real-world settings such as dynamical systems with partial observability, where only noisy and incomplete observations are available. These systems are naturally modeled as state-space models (SSMs), where latent states mediate the link between parameters and data, making the likelihood -- and thus information-theoretic objectives like the expected information gain (EIG) -- intractable. In addition, the dynamical nature of the system requires online algorithms that update posterior distributions and select designs sequentially in a computationally efficient manner. We address these challenges by deriving new estimators of the EIG and its gradient that explicitly marginalize latent states, enabling scalable stochastic optimization in nonlinear SSMs. Our approach leverages nested particle filters (NPFs) for efficient online inference with convergence guarantees. Applications to realistic models, such as the susceptible-infected-recovered (SIR) and a moving source location task, show that our framework successfully handles both partial observability and online computation.
Efficient Human-Aware Task Allocation for Multi-Robot Systems in Shared Environments
Aug 27, 2025Multi-robot systems are increasingly deployed in applications, such as intralogistics or autonomous delivery, where multiple robots collaborate to complete tasks efficiently. One of the key factors enabling their efficient cooperation is Multi-Robot Task Allocation (MRTA). Algorithms solving this problem optimize task distribution among robots to minimize the overall execution time. In shared environments, apart from the relative distance between the robots and the tasks, the execution time is also significantly impacted by the delay caused by navigating around moving people. However, most existing MRTA approaches are dynamics-agnostic, relying on static maps and neglecting human motion patterns, leading to inefficiencies and delays. In this paper, we introduce \acrfull{method name}. This method leverages Maps of Dynamics (MoDs), spatio-temporal queryable models designed to capture historical human movement patterns, to estimate the impact of humans on the task execution time during deployment. \acrshort{method name} utilizes a stochastic cost function that includes MoDs. Experimental results show that integrating MoDs enhances task allocation performance, resulting in reduced mission completion times by up to $26\%$ compared to the dynamics-agnostic method and up to $19\%$ compared to the baseline. This work underscores the importance of considering human dynamics in MRTA within shared environments and presents an efficient framework for deploying multi-robot systems in environments populated by humans.
A Lightweight Crowd Model for Robot Social Navigation
Aug 27, 2025Robots operating in human-populated environments must navigate safely and efficiently while minimizing social disruption. Achieving this requires estimating crowd movement to avoid congested areas in real-time. Traditional microscopic models struggle to scale in dense crowds due to high computational cost, while existing macroscopic crowd prediction models tend to be either overly simplistic or computationally intensive. In this work, we propose a lightweight, real-time macroscopic crowd prediction model tailored for human motion, which balances prediction accuracy and computational efficiency. Our approach simplifies both spatial and temporal processing based on the inherent characteristics of pedestrian flow, enabling robust generalization without the overhead of complex architectures. We demonstrate a 3.6 times reduction in inference time, while improving prediction accuracy by 3.1 %. Integrated into a socially aware planning framework, the model enables efficient and socially compliant robot navigation in dynamic environments. This work highlights that efficient human crowd modeling enables robots to navigate dense environments without costly computations.
Safety and optimality in learning-based control at low computational cost
May 12, 2025Applying machine learning methods to physical systems that are supposed to act in the real world requires providing safety guarantees. However, methods that include such guarantees often come at a high computational cost, making them inapplicable to large datasets and embedded devices with low computational power. In this paper, we propose CoLSafe, a computationally lightweight safe learning algorithm whose computational complexity grows sublinearly with the number of data points. We derive both safety and optimality guarantees and showcase the effectiveness of our algorithm on a seven-degrees-of-freedom robot arm.