 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Safe Exploration for Global Optimization of Dynamical Systems
Paper and Code
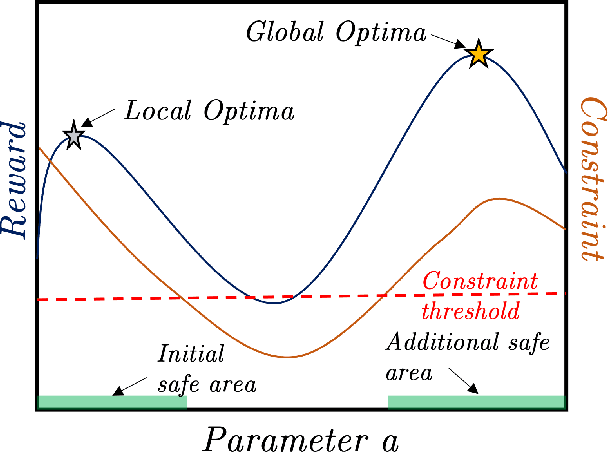


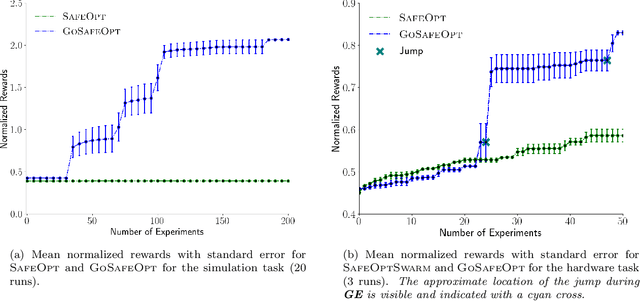
Learning optimal control policies directly on physical systems is challenging since even a single failure can lead to costly hardware damage. Most existing learning methods that guarantee safety, i.e., no failures, during exploration are limited to local optima. A notable exception is the GoSafe algorithm, which, unfortunately, cannot handle high-dimensional systems and hence cannot be applied to most real-world dynamical systems. This work proposes GoSafeOpt as the first algorithm that can safely discover globally optimal policies for complex systems while giving safety and optimality guarantees. Our experiments on a robot arm that would be prohibitive for GoSafe demonstrate that GoSafeOpt safely finds remarkably better policies than competing safe learning methods for high-dimensional domains.