 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreeding Programs Optimization with Reinforcement Learning
Jun 06, 2024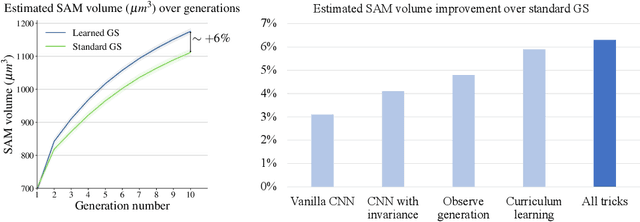
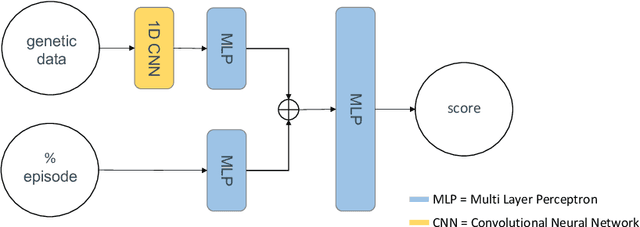
Crop breeding is crucial in improving agricultural productivity while potentially decreasing land usage, greenhouse gas emissions, and water consumption. However, breeding programs are challenging due to long turnover times, high-dimensional decision spaces, long-term objectives, and the need to adapt to rapid climate change. This paper introduces the use of Reinforcement Learning (RL) to optimize simulated crop breeding programs. RL agents are trained to make optimal crop selection and cross-breeding decisions based on genetic information. To benchmark RL-based breeding algorithms, we introduce a suite of Gym environments. The study demonstrates the superiority of RL techniques over standard practices in terms of genetic gain when simulated in silico using real-world genomic maize data.
Safe Guaranteed Exploration for Non-linear Systems
Feb 09, 2024


Safely exploring environments with a-priori unknown constraints is a fundamental challenge that restricts the autonomy of robots. While safety is paramount, guarantees on sufficient exploration are also crucial for ensuring autonomous task completion. To address these challenges, we propose a novel safe guaranteed exploration framework using optimal control, which achieves first-of-its-kind results: guaranteed exploration for non-linear systems with finite time sample complexity bounds, while being provably safe with arbitrarily high probability. The framework is general and applicable to many real-world scenarios with complex non-linear dynamics and unknown domains. Based on this framework we propose an efficient algorithm, SageMPC, SAfe Guaranteed Exploration using Model Predictive Control. SageMPC improves efficiency by incorporating three techniques: i) exploiting a Lipschitz bound, ii) goal-directed exploration, and iii) receding horizon style re-planning, all while maintaining the desired sample complexity, safety and exploration guarantees of the framework. Lastly, we demonstrate safe efficient exploration in challenging unknown environments using SageMPC with a car model.
Near-Optimal Multi-Agent Learning for Safe Coverage Control
Oct 12, 2022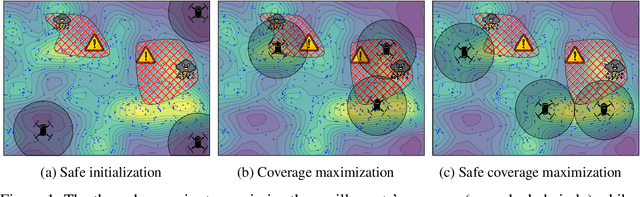
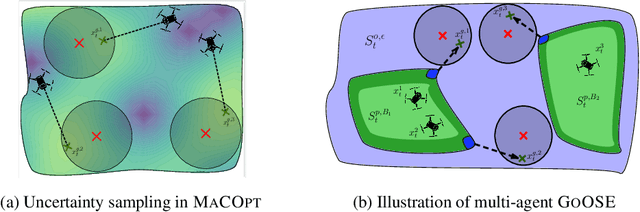
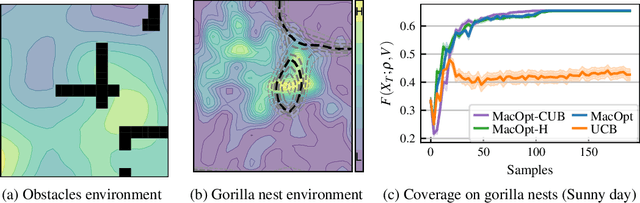
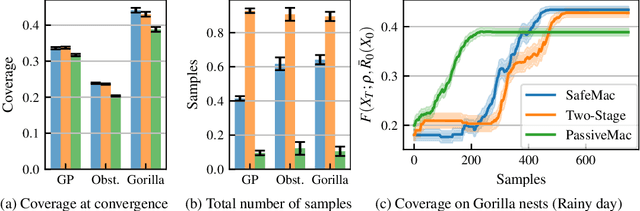
In multi-agent coverage control problems, agents navigate their environment to reach locations that maximize the coverage of some density. In practice, the density is rarely known $\textit{a priori}$, further complicating the original NP-hard problem. Moreover, in many applications, agents cannot visit arbitrary locations due to $\textit{a priori}$ unknown safety constraints. In this paper, we aim to efficiently learn the density to approximately solve the coverage problem while preserving the agents' safety. We first propose a conditionally linear submodular coverage function that facilitates theoretical analysis. Utilizing this structure, we develop MacOpt, a novel algorithm that efficiently trades off the exploration-exploitation dilemma due to partial observability, and show that it achieves sublinear regret. Next, we extend results on single-agent safe exploration to our multi-agent setting and propose SafeMac for safe coverage and exploration. We analyze SafeMac and give first of its kind results: near optimal coverage in finite time while provably guaranteeing safety. We extensively evaluate our algorithms on synthetic and real problems, including a bio-diversity monitoring task under safety constraints, where SafeMac outperforms competing methods.
Scalable Safe Exploration for Global Optimization of Dynamical Systems
Jan 25, 2022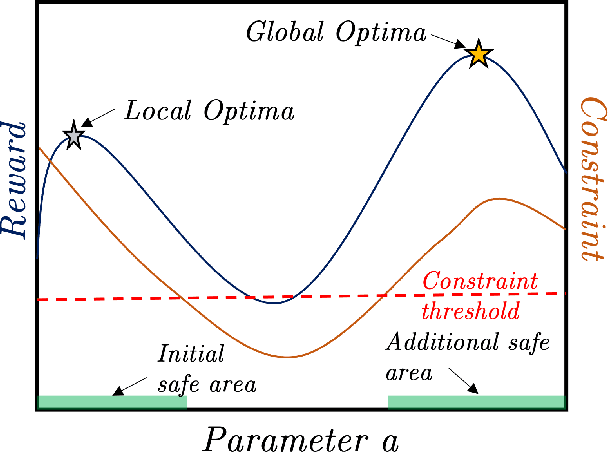


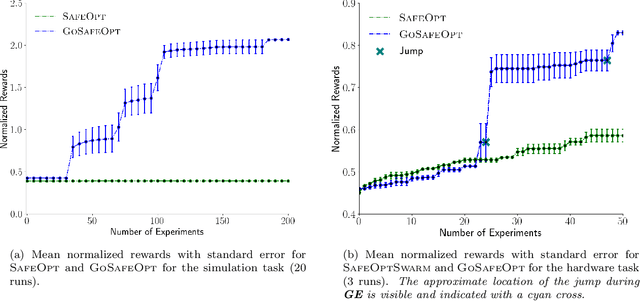
Learning optimal control policies directly on physical systems is challenging since even a single failure can lead to costly hardware damage. Most existing learning methods that guarantee safety, i.e., no failures, during exploration are limited to local optima. A notable exception is the GoSafe algorithm, which, unfortunately, cannot handle high-dimensional systems and hence cannot be applied to most real-world dynamical systems. This work proposes GoSafeOpt as the first algorithm that can safely discover globally optimal policies for complex systems while giving safety and optimality guarantees. Our experiments on a robot arm that would be prohibitive for GoSafe demonstrate that GoSafeOpt safely finds remarkably better policies than competing safe learning methods for high-dimensional domains.
GoSafe: Globally Optimal Safe Robot Learning
May 27, 2021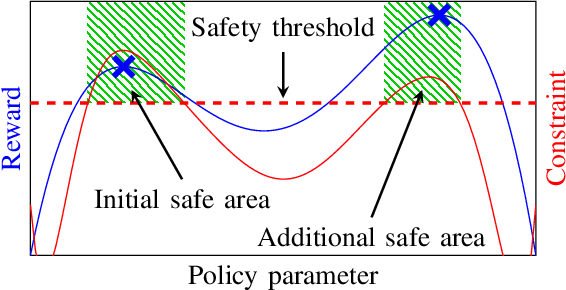
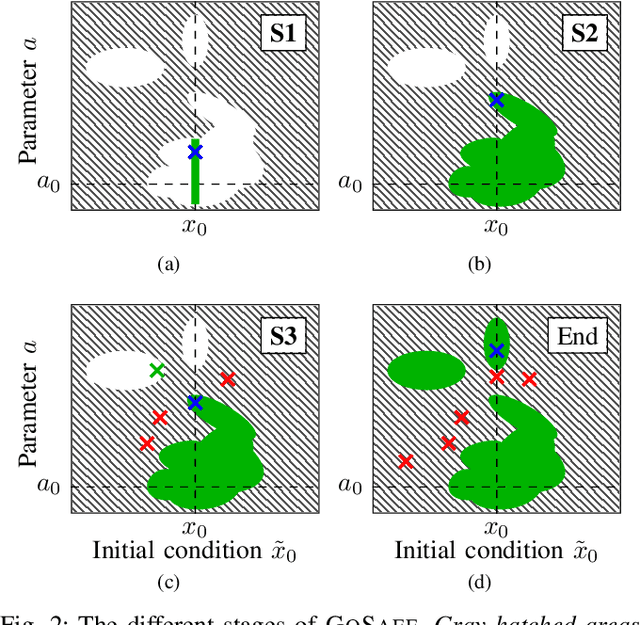
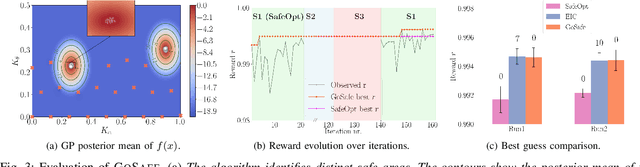

When learning policies for robotic systems from data, safety is a major concern, as violation of safety constraints may cause hardware damage. SafeOpt is an efficient Bayesian optimization (BO) algorithm that can learn policies while guaranteeing safety with high probability. However, its search space is limited to an initially given safe region. We extend this method by exploring outside the initial safe area while still guaranteeing safety with high probability. This is achieved by learning a set of initial conditions from which we can recover safely using a learned backup controller in case of a potential failure. We derive conditions for guaranteed convergence to the global optimum and validate GoSafe in hardware experiments.
Information Directed Reward Learning for Reinforcement Learning
Feb 24, 2021

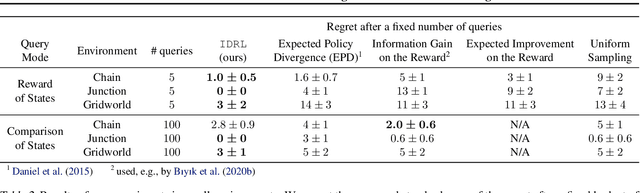
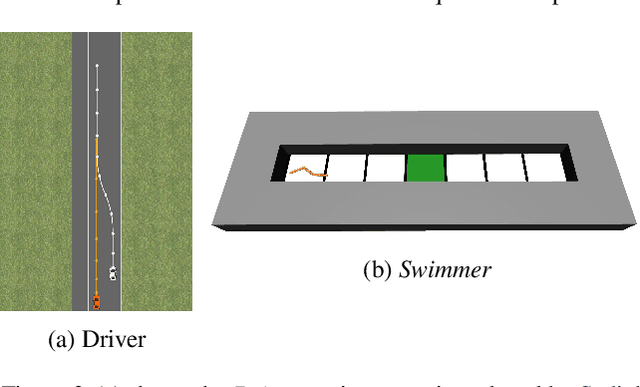
For many reinforcement learning (RL) applications, specifying a reward is difficult. In this paper, we consider an RL setting where the agent can obtain information about the reward only by querying an expert that can, for example, evaluate individual states or provide binary preferences over trajectories. From such expensive feedback, we aim to learn a model of the reward function that allows standard RL algorithms to achieve high expected return with as few expert queries as possible. For this purpose, we propose Information Directed Reward Learning (IDRL), which uses a Bayesian model of the reward function and selects queries that maximize the information gain about the difference in return between potentially optimal policies. In contrast to prior active reward learning methods designed for specific types of queries, IDRL naturally accommodates different query types. Moreover, by shifting the focus from reducing the reward approximation error to improving the policy induced by the reward model, it achieves similar or better performance with significantly fewer queries. We support our findings with extensive evaluations in multiple environments and with different types of queries.
Safe and Efficient Model-free Adaptive Control via Bayesian Optimization
Jan 19, 2021
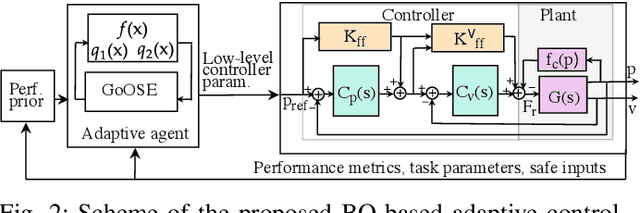

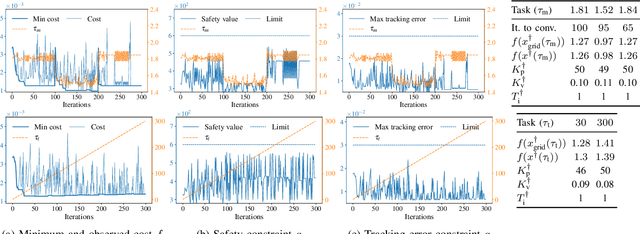
Adaptive control approaches yield high-performance controllers when a precise system model or suitable parametrizations of the controller are available. Existing data-driven approaches for adaptive control mostly augment standard model-based methods with additional information about uncertainties in the dynamics or about disturbances. In this work, we propose a purely data-driven, model-free approach for adaptive control. Tuning low-level controllers based solely on system data raises concerns on the underlying algorithm safety and computational performance. Thus, our approach builds on GoOSE, an algorithm for safe and sample-efficient Bayesian optimization. We introduce several computational and algorithmic modifications in GoOSE that enable its practical use on a rotational motion system. We numerically demonstrate for several types of disturbances that our approach is sample efficient, outperforms constrained Bayesian optimization in terms of safety, and achieves the performance optima computed by grid evaluation. We further demonstrate the proposed adaptive control approach experimentally on a rotational motion system.
Safe Reinforcement Learning via Curriculum Induction
Jun 22, 2020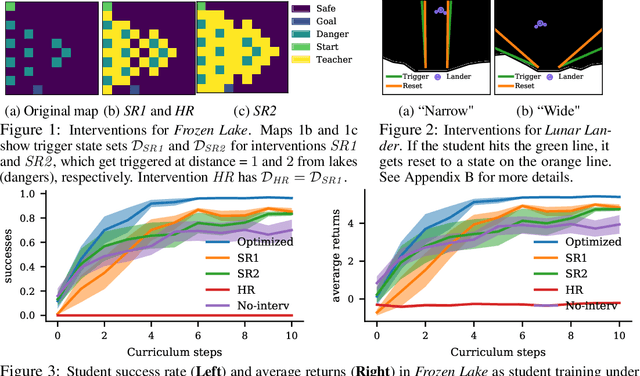


In safety-critical applications, autonomous agents may need to learn in an environment where mistakes can be very costly. In such settings, the agent needs to behave safely not only after but also while learning. To achieve this, existing safe reinforcement learning methods make an agent rely on priors that let it avoid dangerous situations during exploration with high probability, but both the probabilistic guarantees and the smoothness assumptions inherent in the priors are not viable in many scenarios of interest such as autonomous driving. This paper presents an alternative approach inspired by human teaching, where an agent learns under the supervision of an automatic instructor that saves the agent from violating constraints during learning. In this model, we introduce the monitor that neither needs to know how to do well at the task the agent is learning nor needs to know how the environment works. Instead, it has a library of reset controllers that it activates when the agent starts behaving dangerously, preventing it from doing damage. Crucially, the choices of which reset controller to apply in which situation affect the speed of agent learning. Based on observing agents' progress, the teacher itself learns a policy for choosing the reset controllers, a curriculum, to optimize the agent's final policy reward. Our experiments use this framework in two environments to induce curricula for safe and efficient learning.
Safe Exploration for Interactive Machine Learning
Oct 30, 2019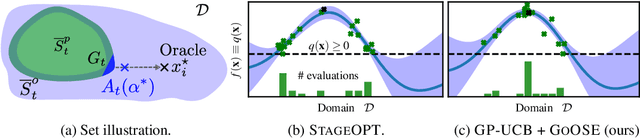
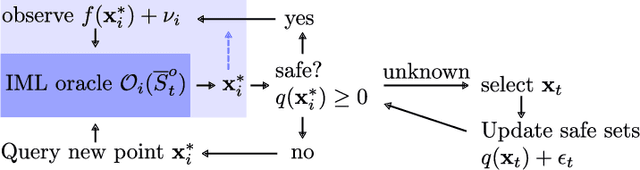
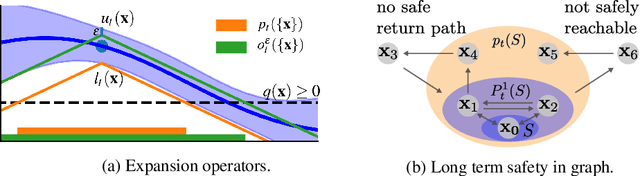
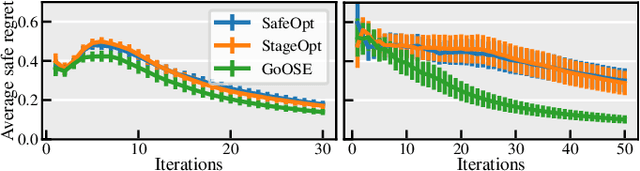
In Interactive Machine Learning (IML), we iteratively make decisions and obtain noisy observations of an unknown function. While IML methods, e.g., Bayesian optimization and active learning, have been successful in applications, on real-world systems they must provably avoid unsafe decisions. To this end, safe IML algorithms must carefully learn about a priori unknown constraints without making unsafe decisions. Existing algorithms for this problem learn about the safety of all decisions to ensure convergence. This is sample-inefficient, as it explores decisions that are not relevant for the original IML objective. In this paper, we introduce a novel framework that renders any existing unsafe IML algorithm safe. Our method works as an add-on that takes suggested decisions as input and exploits regularity assumptions in terms of a Gaussian process prior in order to efficiently learn about their safety. As a result, we only explore the safe set when necessary for the IML problem. We apply our framework to safe Bayesian optimization and to safe exploration in deterministic Markov Decision Processes (MDP), which have been analyzed separately before. Our method outperforms other algorithms empirically.
Robust Model-free Reinforcement Learning with Multi-objective Bayesian Optimization
Oct 29, 2019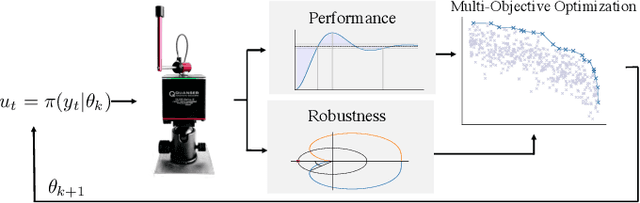
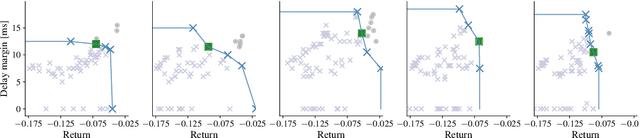
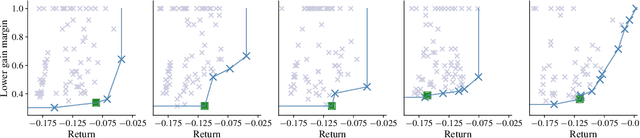

In reinforcement learning (RL), an autonomous agent learns to perform complex tasks by maximizing an exogenous reward signal while interacting with its environment. In real-world applications, test conditions may differ substantially from the training scenario and, therefore, focusing on pure reward maximization during training may lead to poor results at test time. In these cases, it is important to trade-off between performance and robustness while learning a policy. While several results exist for robust, model-based RL, the model-free case has not been widely investigated. In this paper, we cast the robust, model-free RL problem as a multi-objective optimization problem. To quantify the robustness of a policy, we use delay margin and gain margin, two robustness indicators that are common in control theory. We show how these metrics can be estimated from data in the model-free setting. We use multi-objective Bayesian optimization (MOBO) to solve efficiently this expensive-to-evaluate, multi-objective optimization problem. We show the benefits of our robust formulation both in sim-to-real and pure hardware experiments to balance a Furuta pendulum.