 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Information-Theoretic Approach to Data Attribution
Apr 04, 2026Training Data Attribution (TDA) seeks to trace model predictions back to influential training examples, enhancing interpretability and safety. We formulate TDA as a Bayesian information-theoretic problem: subsets are scored by the information loss they induce - the entropy increase at a query when removed. This criterion credits examples for resolving predictive uncertainty rather than label noise. To scale to modern networks, we approximate information loss using a Gaussian Process surrogate built from tangent features. We show this aligns with classical influence scores for single-example attribution while promoting diversity for subsets. For even larger-scale retrieval, we relax to an information-gain objective and add a variance correction for scalable attribution in vector databases. Experiments show competitive performance on counterfactual sensitivity, ground-truth retrieval and coreset selection, showing that our method scales to modern architectures while bridging principled measures with practice.
Richer Bayesian Last Layers with Subsampled NTK Features
Feb 01, 2026Bayesian Last Layers (BLLs) provide a convenient and computationally efficient way to estimate uncertainty in neural networks. However, they underestimate epistemic uncertainty because they apply a Bayesian treatment only to the final layer, ignoring uncertainty induced by earlier layers. We propose a method that improves BLLs by leveraging a projection of Neural Tangent Kernel (NTK) features onto the space spanned by the last-layer features. This enables posterior inference that accounts for variability of the full network while retaining the low computational cost of inference of a standard BLL. We show that our method yields posterior variances that are provably greater or equal to those of a standard BLL, correcting its tendency to underestimate epistemic uncertainty. To further reduce computational cost, we introduce a uniform subsampling scheme for estimating the projection matrix and for posterior inference. We derive approximation bounds for both types of sub-sampling. Empirical evaluations on UCI regression, contextual bandits, image classification, and out-of-distribution detection tasks in image and tabular datasets, demonstrate improved calibration and uncertainty estimates compared to standard BLLs and competitive baselines, while reducing computational cost.
Measuring Uncertainty Calibration
Dec 15, 2025We make two contributions to the problem of estimating the $L_1$ calibration error of a binary classifier from a finite dataset. First, we provide an upper bound for any classifier where the calibration function has bounded variation. Second, we provide a method of modifying any classifier so that its calibration error can be upper bounded efficiently without significantly impacting classifier performance and without any restrictive assumptions. All our results are non-asymptotic and distribution-free. We conclude by providing advice on how to measure calibration error in practice. Our methods yield practical procedures that can be run on real-world datasets with modest overhead.
Linear Gradient Prediction with Control Variates
Nov 07, 2025We propose a new way of training neural networks, with the goal of reducing training cost. Our method uses approximate predicted gradients instead of the full gradients that require an expensive backward pass. We derive a control-variate-based technique that ensures our updates are unbiased estimates of the true gradient. Moreover, we propose a novel way to derive a predictor for the gradient inspired by the theory of the Neural Tangent Kernel. We empirically show the efficacy of the technique on a vision transformer classification task.
Hallucination Detection on a Budget: Efficient Bayesian Estimation of Semantic Entropy
Apr 04, 2025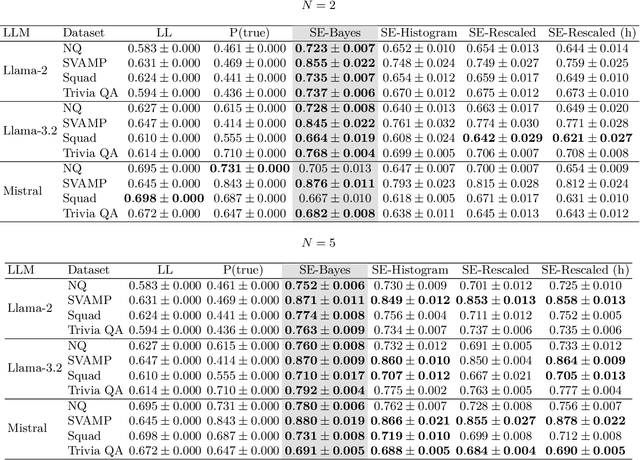
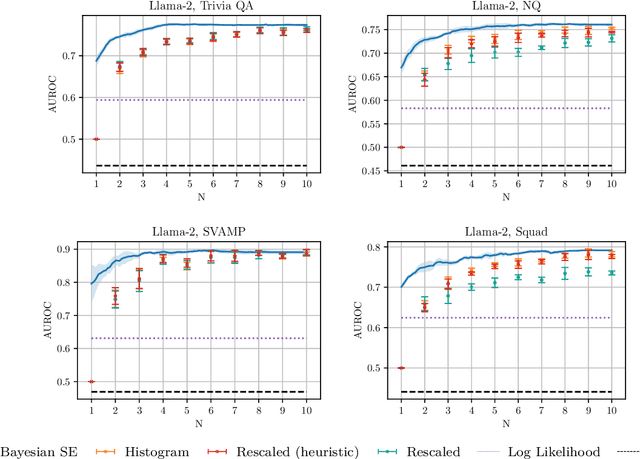
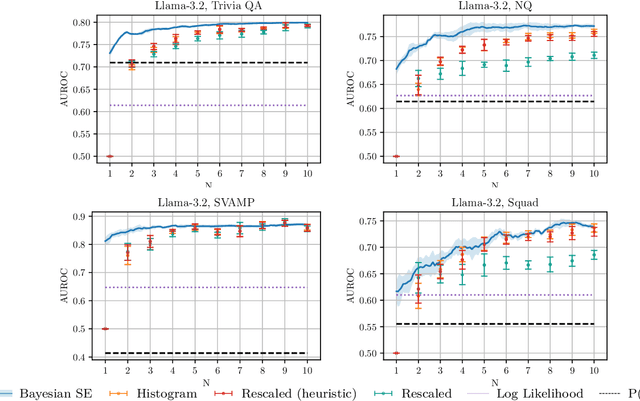
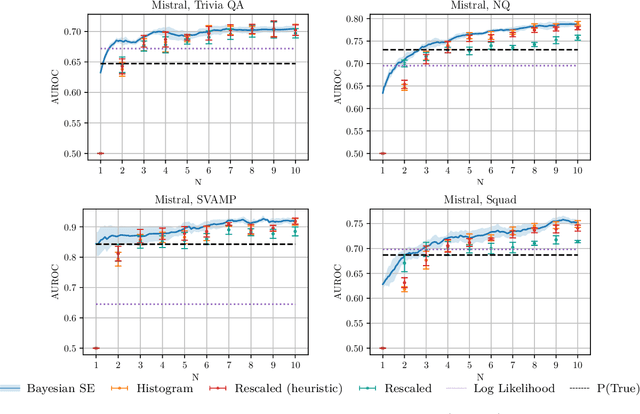
Detecting whether an LLM hallucinates is an important research challenge. One promising way of doing so is to estimate the semantic entropy (Farquhar et al., 2024) of the distribution of generated sequences. We propose a new algorithm for doing that, with two main advantages. First, due to us taking the Bayesian approach, we achieve a much better quality of semantic entropy estimates for a given budget of samples from the LLM. Second, we are able to tune the number of samples adaptively so that `harder' contexts receive more samples. We demonstrate empirically that our approach systematically beats the baselines, requiring only 59% of samples used by Farquhar et al. (2024) to achieve the same quality of hallucination detection as measured by AUROC. Moreover, quite counterintuitively, our estimator is useful even with just one sample from the LLM.
Observation Noise and Initialization in Wide Neural Networks
Feb 03, 2025Performing gradient descent in a wide neural network is equivalent to computing the posterior mean of a Gaussian Process with the Neural Tangent Kernel (NTK-GP), for a specific choice of prior mean and with zero observation noise. However, existing formulations of this result have two limitations: i) the resultant NTK-GP assumes no noise in the observed target variables, which can result in suboptimal predictions with noisy data; ii) it is unclear how to extend the equivalence to an arbitrary prior mean, a crucial aspect of formulating a well-specified model. To address the first limitation, we introduce a regularizer into the neural network's training objective, formally showing its correspondence to incorporating observation noise into the NTK-GP model. To address the second, we introduce a \textit{shifted network} that enables arbitrary prior mean functions. This approach allows us to perform gradient descent on a single neural network, without expensive ensembling or kernel matrix inversion. Our theoretical insights are validated empirically, with experiments exploring different values of observation noise and network architectures.
Impatient Bandits: Optimizing for the Long-Term Without Delay
Jan 14, 2025


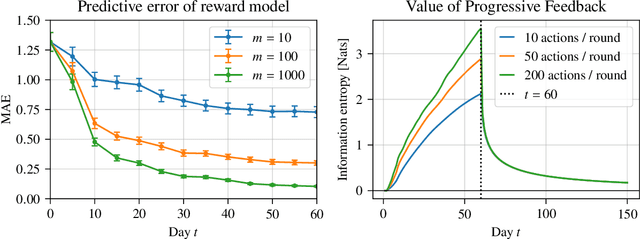
Increasingly, recommender systems are tasked with improving users' long-term satisfaction. In this context, we study a content exploration task, which we formalize as a bandit problem with delayed rewards. There is an apparent trade-off in choosing the learning signal: waiting for the full reward to become available might take several weeks, slowing the rate of learning, whereas using short-term proxy rewards reflects the actual long-term goal only imperfectly. First, we develop a predictive model of delayed rewards that incorporates all information obtained to date. Rewards as well as shorter-term surrogate outcomes are combined through a Bayesian filter to obtain a probabilistic belief. Second, we devise a bandit algorithm that quickly learns to identify content aligned with long-term success using this new predictive model. We prove a regret bound for our algorithm that depends on the \textit{Value of Progressive Feedback}, an information theoretic metric that captures the quality of short-term leading indicators that are observed prior to the long-term reward. We apply our approach to a podcast recommendation problem, where we seek to recommend shows that users engage with repeatedly over two months. We empirically validate that our approach significantly outperforms methods that optimize for short-term proxies or rely solely on delayed rewards, as demonstrated by an A/B test in a recommendation system that serves hundreds of millions of users.
Epistemic Uncertainty and Observation Noise with the Neural Tangent Kernel
Sep 10, 2024
Recent work has shown that training wide neural networks with gradient descent is formally equivalent to computing the mean of the posterior distribution in a Gaussian Process (GP) with the Neural Tangent Kernel (NTK) as the prior covariance and zero aleatoric noise \parencite{jacot2018neural}. In this paper, we extend this framework in two ways. First, we show how to deal with non-zero aleatoric noise. Second, we derive an estimator for the posterior covariance, giving us a handle on epistemic uncertainty. Our proposed approach integrates seamlessly with standard training pipelines, as it involves training a small number of additional predictors using gradient descent on a mean squared error loss. We demonstrate the proof-of-concept of our method through empirical evaluation on synthetic regression.
On the Importance of Uncertainty in Decision-Making with Large Language Models
Apr 03, 2024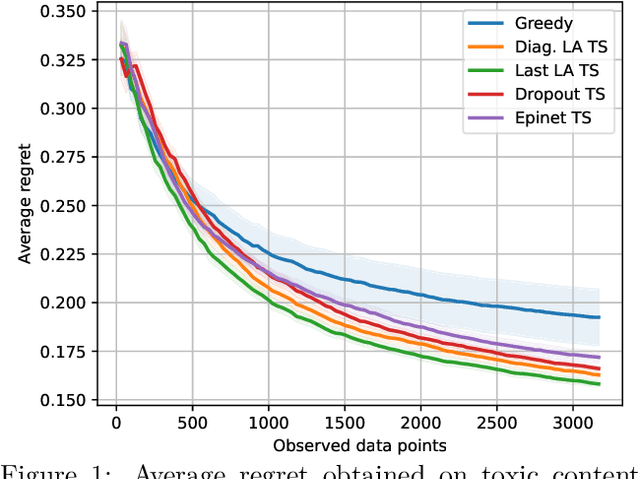
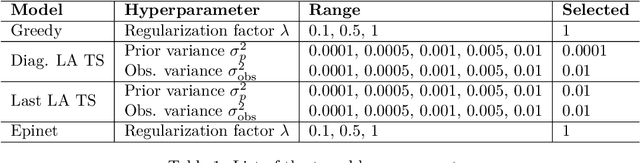
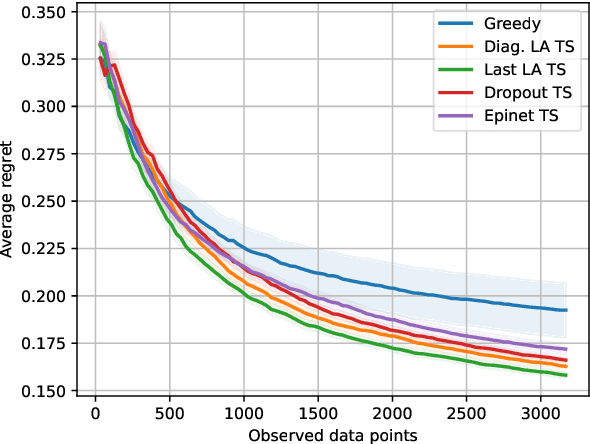
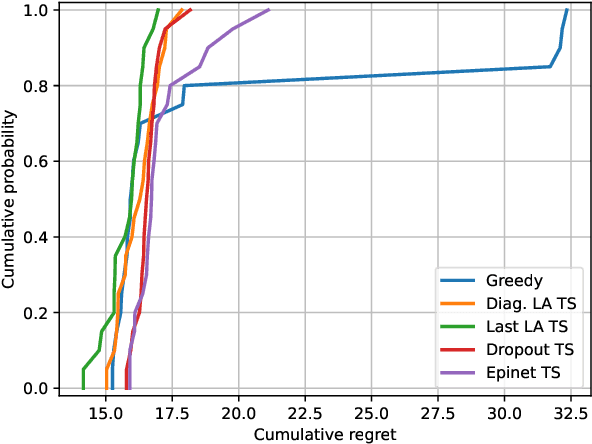
We investigate the role of uncertainty in decision-making problems with natural language as input. For such tasks, using Large Language Models as agents has become the norm. However, none of the recent approaches employ any additional phase for estimating the uncertainty the agent has about the world during the decision-making task. We focus on a fundamental decision-making framework with natural language as input, which is the one of contextual bandits, where the context information consists of text. As a representative of the approaches with no uncertainty estimation, we consider an LLM bandit with a greedy policy, which picks the action corresponding to the largest predicted reward. We compare this baseline to LLM bandits that make active use of uncertainty estimation by integrating the uncertainty in a Thompson Sampling policy. We employ different techniques for uncertainty estimation, such as Laplace Approximation, Dropout, and Epinets. We empirically show on real-world data that the greedy policy performs worse than the Thompson Sampling policies. These findings suggest that, while overlooked in the LLM literature, uncertainty plays a fundamental role in bandit tasks with LLMs.
Automatic Music Playlist Generation via Simulation-based Reinforcement Learning
Oct 13, 2023



Personalization of playlists is a common feature in music streaming services, but conventional techniques, such as collaborative filtering, rely on explicit assumptions regarding content quality to learn how to make recommendations. Such assumptions often result in misalignment between offline model objectives and online user satisfaction metrics. In this paper, we present a reinforcement learning framework that solves for such limitations by directly optimizing for user satisfaction metrics via the use of a simulated playlist-generation environment. Using this simulator we develop and train a modified Deep Q-Network, the action head DQN (AH-DQN), in a manner that addresses the challenges imposed by the large state and action space of our RL formulation. The resulting policy is capable of making recommendations from large and dynamic sets of candidate items with the expectation of maximizing consumption metrics. We analyze and evaluate agents offline via simulations that use environment models trained on both public and proprietary streaming datasets. We show how these agents lead to better user-satisfaction metrics compared to baseline methods during online A/B tests. Finally, we demonstrate that performance assessments produced from our simulator are strongly correlated with observed online metric results.