 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Nephrographic Image Synthesis in CT Urography with the Diffusion Model and Swin Transformer
Feb 26, 2025Purpose: This study aims to develop and validate a method for synthesizing 3D nephrographic phase images in CT urography (CTU) examinations using a diffusion model integrated with a Swin Transformer-based deep learning approach. Materials and Methods: This retrospective study was approved by the local Institutional Review Board. A dataset comprising 327 patients who underwent three-phase CTU (mean $\pm$ SD age, 63 $\pm$ 15 years; 174 males, 153 females) was curated for deep learning model development. The three phases for each patient were aligned with an affine registration algorithm. A custom deep learning model coined dsSNICT (diffusion model with a Swin transformer for synthetic nephrographic phase images in CT) was developed and implemented to synthesize the nephrographic images. Performance was assessed using Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Mean Absolute Error (MAE), and Fr\'{e}chet Video Distance (FVD). Qualitative evaluation by two fellowship-trained abdominal radiologists was performed. Results: The synthetic nephrographic images generated by our proposed approach achieved high PSNR (26.3 $\pm$ 4.4 dB), SSIM (0.84 $\pm$ 0.069), MAE (12.74 $\pm$ 5.22 HU), and FVD (1323). Two radiologists provided average scores of 3.5 for real images and 3.4 for synthetic images (P-value = 0.5) on a Likert scale of 1-5, indicating that our synthetic images closely resemble real images. Conclusion: The proposed approach effectively synthesizes high-quality 3D nephrographic phase images. This model can be used to reduce radiation dose in CTU by 33.3\% without compromising image quality, which thereby enhances the safety and diagnostic utility of CT urography.
Deep Generative Classification of Blood Cell Morphology
Aug 16, 2024



Accurate classification of haematological cells is critical for diagnosing blood disorders, but presents significant challenges for machine automation owing to the complexity of cell morphology, heterogeneities of biological, pathological, and imaging characteristics, and the imbalance of cell type frequencies. We introduce CytoDiffusion, a diffusion-based classifier that effectively models blood cell morphology, combining accurate classification with robust anomaly detection, resistance to distributional shifts, interpretability, data efficiency, and superhuman uncertainty quantification. Our approach outperforms state-of-the-art discriminative models in anomaly detection (AUC 0.976 vs. 0.919), resistance to domain shifts (85.85% vs. 74.38% balanced accuracy), and performance in low-data regimes (95.88% vs. 94.95% balanced accuracy). Notably, our model generates synthetic blood cell images that are nearly indistinguishable from real images, as demonstrated by a Turing test in which expert haematologists achieved only 52.3% accuracy (95% CI: [50.5%, 54.2%]). Furthermore, we enhance model explainability through the generation of directly interpretable counterfactual heatmaps. Our comprehensive evaluation framework, encompassing these multiple performance dimensions, establishes a new benchmark for medical image analysis in haematology, ultimately enabling improved diagnostic accuracy in clinical settings. Our code is available at https://github.com/Deltadahl/CytoDiffusion.
Building a Safer Maritime Environment Through Multi-Path Long-Term Vessel Trajectory Forecasting
Oct 29, 2023



Maritime transport is paramount to global economic growth and environmental sustainability. In this regard, the Automatic Identification System (AIS) data plays a significant role by offering real-time streaming data on vessel movement, which allows for enhanced traffic surveillance, assisting in vessel safety by avoiding vessel-to-vessel collisions and proactively preventing vessel-to-whale ones. This paper tackles an intrinsic problem to trajectory forecasting: the effective multi-path long-term vessel trajectory forecasting on engineered sequences of AIS data. We utilize an encoder-decoder model with Bidirectional Long Short-Term Memory Networks (Bi-LSTM) to predict the next 12 hours of vessel trajectories using 1 to 3 hours of AIS data. We feed the model with probabilistic features engineered from the AIS data that refer to the potential route and destination of each trajectory so that the model, leveraging convolutional layers for spatial feature learning and a position-aware attention mechanism that increases the importance of recent timesteps of a sequence during temporal feature learning, forecasts the vessel trajectory taking the potential route and destination into account. The F1 Score of these features is approximately 85% and 75%, indicating their efficiency in supplementing the neural network. We trialed our model in the Gulf of St. Lawrence, one of the North Atlantic Right Whales (NARW) habitats, achieving an R2 score exceeding 98% with varying techniques and features. Despite the high R2 score being attributed to well-defined shipping lanes, our model demonstrates superior complex decision-making during path selection. In addition, our model shows enhanced accuracy, with average and median forecasting errors of 11km and 6km, respectively. Our study confirms the potential of geographical data engineering and trajectory forecasting models for preserving marine life species.
A Strong Baseline for Batch Imitation Learning
Feb 06, 2023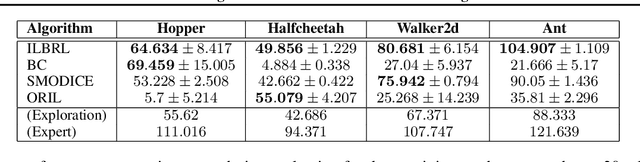
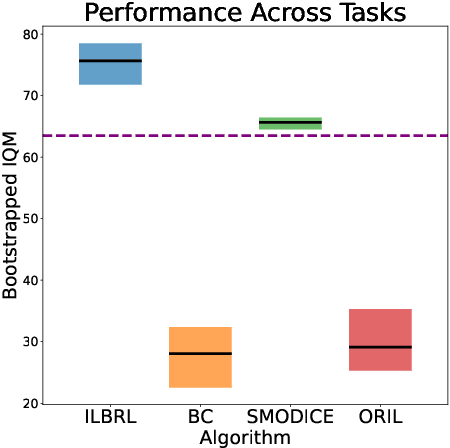
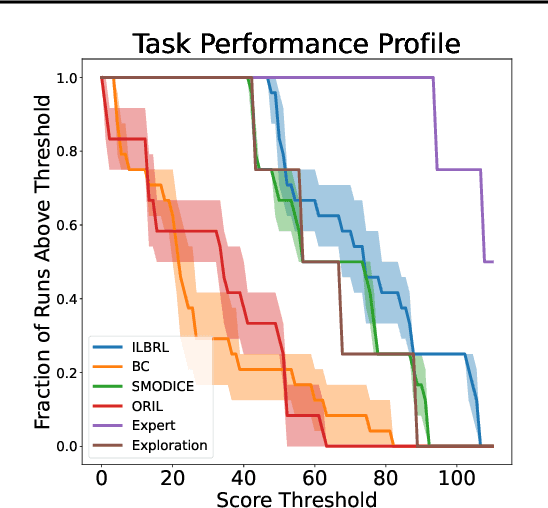

Imitation of expert behaviour is a highly desirable and safe approach to the problem of sequential decision making. We provide an easy-to-implement, novel algorithm for imitation learning under a strict data paradigm, in which the agent must learn solely from data collected a priori. This paradigm allows our algorithm to be used for environments in which safety or cost are of critical concern. Our algorithm requires no additional hyper-parameter tuning beyond any standard batch reinforcement learning (RL) algorithm, making it an ideal baseline for such data-strict regimes. Furthermore, we provide formal sample complexity guarantees for the algorithm in finite Markov Decision Problems. In doing so, we formally demonstrate an unproven claim from Kearns & Singh (1998). On the empirical side, our contribution is twofold. First, we develop a practical, robust and principled evaluation protocol for offline RL methods, making use of only the dataset provided for model selection. This stands in contrast to the vast majority of previous works in offline RL, which tune hyperparameters on the evaluation environment, limiting the practical applicability when deployed in new, cost-critical environments. As such, we establish precedent for the development and fair evaluation of offline RL algorithms. Second, we evaluate our own algorithm on challenging continuous control benchmarks, demonstrating its practical applicability and competitiveness with state-of-the-art performance, despite being a simpler algorithm.
Semi-Supervised Audio Representation Learning for Modeling Beehive Strengths
May 21, 2021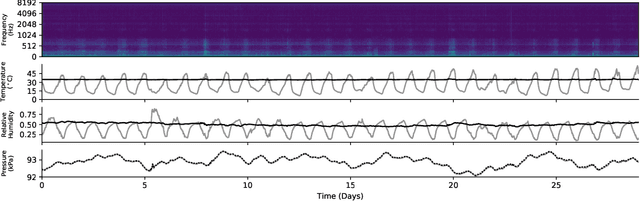

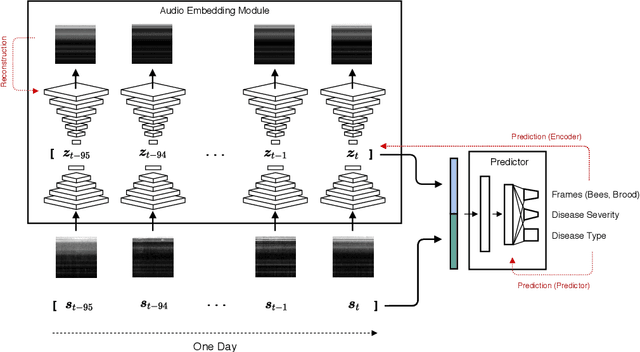

Honey bees are critical to our ecosystem and food security as a pollinator, contributing 35% of our global agriculture yield. In spite of their importance, beekeeping is exclusively dependent on human labor and experience-derived heuristics, while requiring frequent human checkups to ensure the colony is healthy, which can disrupt the colony. Increasingly, pollinator populations are declining due to threats from climate change, pests, environmental toxicity, making their management even more critical than ever before in order to ensure sustained global food security. To start addressing this pressing challenge, we developed an integrated hardware sensing system for beehive monitoring through audio and environment measurements, and a hierarchical semi-supervised deep learning model, composed of an audio modeling module and a predictor, to model the strength of beehives. The model is trained jointly on audio reconstruction and prediction losses based on human inspections, in order to model both low-level audio features and circadian temporal dynamics. We show that this model performs well despite limited labels, and can learn an audio embedding that is useful for characterizing different sound profiles of beehives. This is the first instance to our knowledge of applying audio-based deep learning to model beehives and population size in an observational setting across a large number of hives.
Classi-Fly: Inferring Aircraft Categories from Open Data
Jul 30, 2019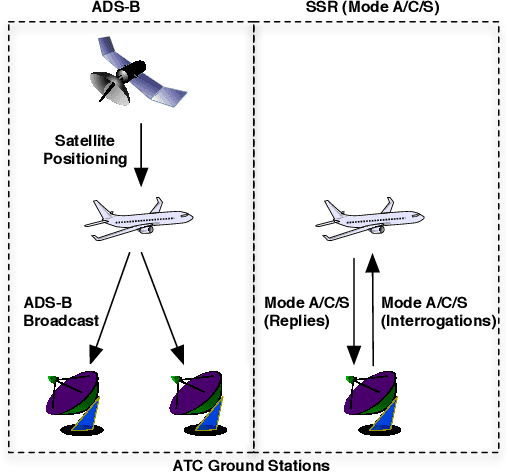
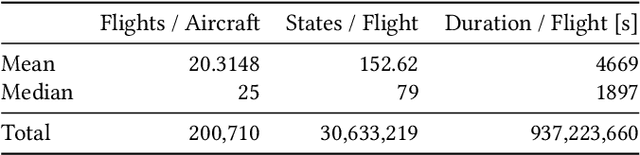
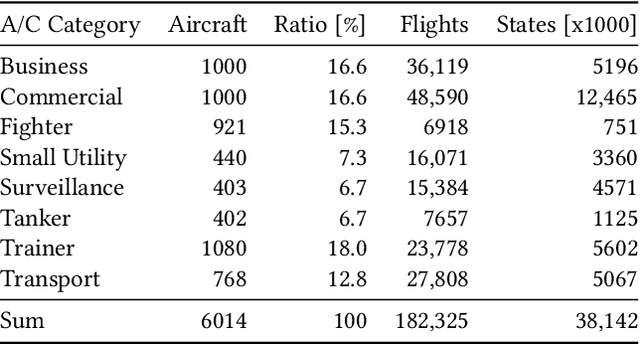
In recent years, air traffic communication data has become easy to access, enabling novel research in many fields. Exploiting this new data source, a wide range of applications have emerged, from weather forecasting to stock market prediction, or the collection of intelligence about military and government movements. Typically these applications require knowledge about the metadata of the aircraft, specifically its operator and the aircraft category. armasuisse Science + Technology, the R&D agency for the Swiss Armed Forces, has been developing Classi-Fly, a novel approach to obtain metadata about aircraft based on their movement patterns. We validate Classi-Fly using several hundred thousand flights collected through open source means, in conjunction with ground truth from publicly available aircraft registries containing more than two million aircraft. We show that we can obtain the correct aircraft category with an accuracy of over 88%. In cases, where no metadata is available, this approach can be used to create the data necessary for applications working with air traffic communication. Finally, we show that it is feasible to automatically detect sensitive aircraft such as police and surveillance aircraft using this method.
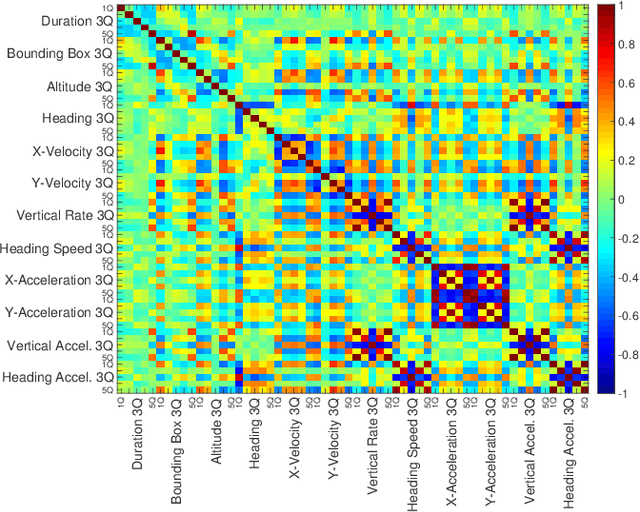
Towards Deep Learning Models for Psychological State Prediction using Smartphone Data: Challenges and Opportunities
Nov 16, 2017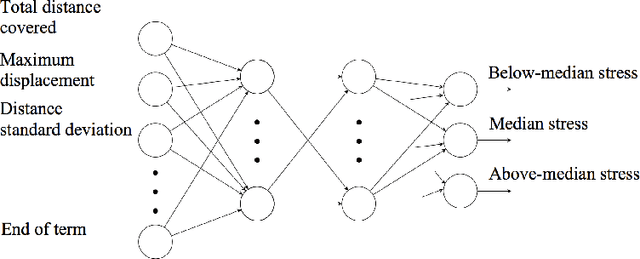

There is an increasing interest in exploiting mobile sensing technologies and machine learning techniques for mental health monitoring and intervention. Researchers have effectively used contextual information, such as mobility, communication and mobile phone usage patterns for quantifying individuals' mood and wellbeing. In this paper, we investigate the effectiveness of neural network models for predicting users' level of stress by using the location information collected by smartphones. We characterize the mobility patterns of individuals using the GPS metrics presented in the literature and employ these metrics as input to the network. We evaluate our approach on the open-source StudentLife dataset. Moreover, we discuss the challenges and trade-offs involved in building machine learning models for digital mental health and highlight potential future work in this direction.
Her2 Challenge Contest: A Detailed Assessment of Automated Her2 Scoring Algorithms in Whole Slide Images of Breast Cancer Tissues
Jul 24, 2017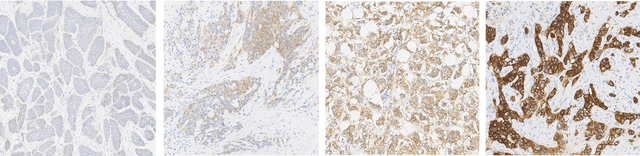

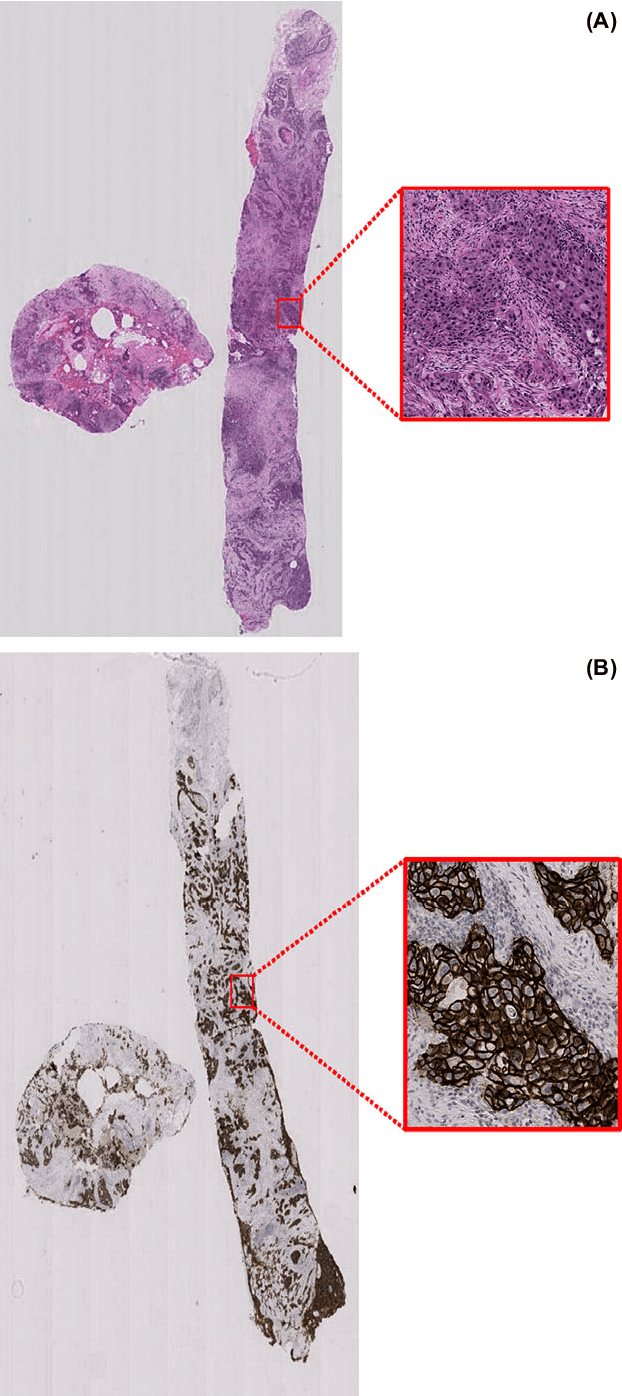
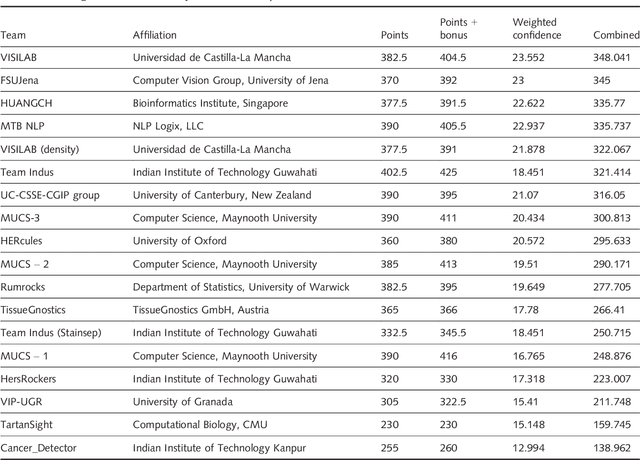
Evaluating expression of the Human epidermal growth factor receptor 2 (Her2) by visual examination of immunohistochemistry (IHC) on invasive breast cancer (BCa) is a key part of the diagnostic assessment of BCa due to its recognised importance as a predictive and prognostic marker in clinical practice. However, visual scoring of Her2 is subjective and consequently prone to inter-observer variability. Given the prognostic and therapeutic implications of Her2 scoring, a more objective method is required. In this paper, we report on a recent automated Her2 scoring contest, held in conjunction with the annual PathSoc meeting held in Nottingham in June 2016, aimed at systematically comparing and advancing the state-of-the-art Artificial Intelligence (AI) based automated methods for Her2 scoring. The contest dataset comprised of digitised whole slide images (WSI) of sections from 86 cases of invasive breast carcinoma stained with both Haematoxylin & Eosin (H&E) and IHC for Her2. The contesting algorithms automatically predicted scores of the IHC slides for an unseen subset of the dataset and the predicted scores were compared with the 'ground truth' (a consensus score from at least two experts). We also report on a simple Man vs Machine contest for the scoring of Her2 and show that the automated methods could beat the pathology experts on this contest dataset. This paper presents a benchmark for comparing the performance of automated algorithms for scoring of Her2. It also demonstrates the enormous potential of automated algorithms in assisting the pathologist with objective IHC scoring.