 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVET Your Agent: Towards Host-Independent Autonomy via Verifiable Execution Traces
Dec 17, 2025Recent advances in large language models (LLMs) have enabled a new generation of autonomous agents that operate over sustained periods and manage sensitive resources on behalf of users. Trusted for their ability to act without direct oversight, such agents are increasingly considered in high-stakes domains including financial management, dispute resolution, and governance. Yet in practice, agents execute on infrastructure controlled by a host, who can tamper with models, inputs, or outputs, undermining any meaningful notion of autonomy. We address this gap by introducing VET (Verifiable Execution Traces), a formal framework that achieves host-independent authentication of agent outputs and takes a step toward host-independent autonomy. Central to VET is the Agent Identity Document (AID), which specifies an agent's configuration together with the proof systems required for verification. VET is compositional: it supports multiple proof mechanisms, including trusted hardware, succinct cryptographic proofs, and notarized TLS transcripts (Web Proofs). We implement VET for an API-based LLM agent and evaluate our instantiation on realistic workloads. We find that for today's black-box, secret-bearing API calls, Web Proofs appear to be the most practical choice, with overhead typically under 3$\times$ compared to direct API calls, while for public API calls, a lower-overhead TEE Proxy is often sufficient. As a case study, we deploy a verifiable trading agent that produces proofs for each decision and composes Web Proofs with a TEE Proxy. Our results demonstrate that practical, host-agnostic authentication is already possible with current technology, laying the foundation for future systems that achieve full host-independent autonomy.
SATversary: Adversarial Attacks on Satellite Fingerprinting
Jun 06, 2025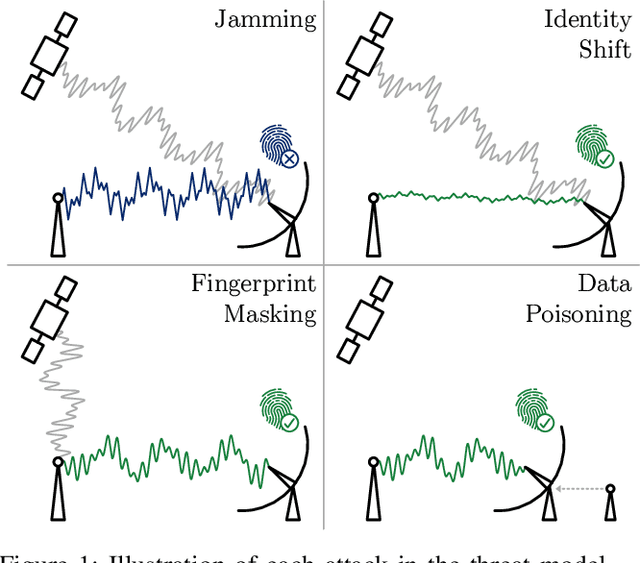

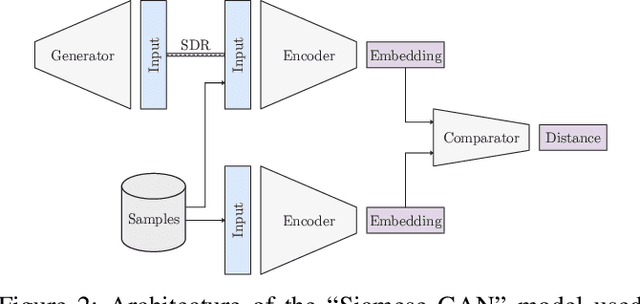
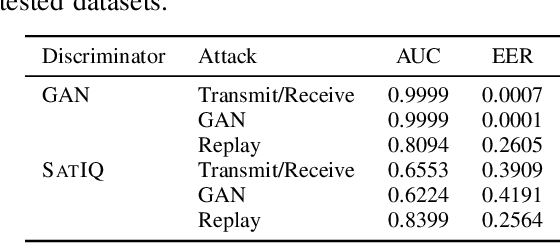
As satellite systems become increasingly vulnerable to physical layer attacks via SDRs, novel countermeasures are being developed to protect critical systems, particularly those lacking cryptographic protection, or those which cannot be upgraded to support modern cryptography. Among these is transmitter fingerprinting, which provides mechanisms by which communication can be authenticated by looking at characteristics of the transmitter, expressed as impairments on the signal. Previous works show that fingerprinting can be used to classify satellite transmitters, or authenticate them against SDR-equipped attackers under simple replay scenarios. In this paper we build upon this by looking at attacks directly targeting the fingerprinting system, with an attacker optimizing for maximum impact in jamming, spoofing, and dataset poisoning attacks, and demonstrate these attacks on the SatIQ system designed to authenticate Iridium transmitters. We show that an optimized jamming signal can cause a 50% error rate with attacker-to-victim ratios as low as -30dB (far less power than traditional jamming) and demonstrate successful identity forgery during spoofing attacks, with an attacker successfully removing their own transmitter's fingerprint from messages. We also present a data poisoning attack, enabling persistent message spoofing by altering the data used to authenticate incoming messages to include the fingerprint of the attacker's transmitter. Finally, we show that our model trained to optimize spoofing attacks can also be used to detect spoofing and replay attacks, even when it has never seen the attacker's transmitter before. Furthermore, this technique works even when the training dataset includes only a single transmitter, enabling fingerprinting to be used to protect small constellations and even individual satellites, providing additional protection where it is needed the most.
UserBoost: Generating User-specific Synthetic Data for Faster Enrolment into Behavioural Biometric Systems
Jul 12, 2024
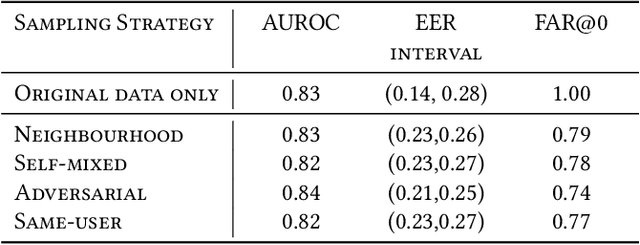
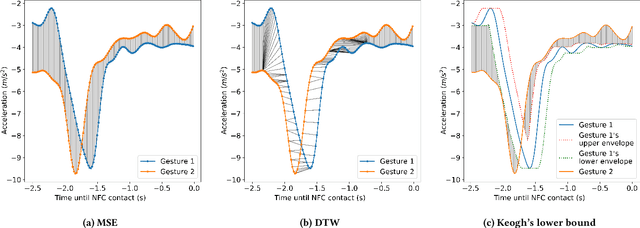
Behavioural biometric authentication systems entail an enrolment period that is burdensome for the user. In this work, we explore generating synthetic gestures from a few real user gestures with generative deep learning, with the application of training a simple (i.e. non-deep-learned) authentication model. Specifically, we show that utilising synthetic data alongside real data can reduce the number of real datapoints a user must provide to enrol into a biometric system. To validate our methods, we use the publicly available dataset of WatchAuth, a system proposed in 2022 for authenticating smartwatch payments using the physical gesture of reaching towards a payment terminal. We develop a regularised autoencoder model for generating synthetic user-specific wrist motion data representing these physical gestures, and demonstrate the diversity and fidelity of our synthetic gestures. We show that using synthetic gestures in training can improve classification ability for a real-world system. Through this technique we can reduce the number of gestures required to enrol a user into a WatchAuth-like system by more than 40% without negatively impacting its error rates.
Watch This Space: Securing Satellite Communication through Resilient Transmitter Fingerprinting
May 11, 2023Due to an increase in the availability of cheap off-the-shelf radio hardware, spoofing and replay attacks on satellite ground systems have become more accessible than ever. This is particularly a problem for legacy systems, many of which do not offer cryptographic security and cannot be patched to support novel security measures. In this paper we explore radio transmitter fingerprinting in satellite systems. We introduce the SatIQ system, proposing novel techniques for authenticating transmissions using characteristics of transmitter hardware expressed as impairments on the downlinked signal. We look in particular at high sample rate fingerprinting, making fingerprints difficult to forge without similarly high sample rate transmitting hardware, thus raising the budget for attacks. We also examine the difficulty of this approach with high levels of atmospheric noise and multipath scattering, and analyze potential solutions to this problem. We focus on the Iridium satellite constellation, for which we collected 1010464 messages at a sample rate of 25 MS/s. We use this data to train a fingerprinting model consisting of an autoencoder combined with a Siamese neural network, enabling the model to learn an efficient encoding of message headers that preserves identifying information. We demonstrate the system's robustness under attack by replaying messages using a Software-Defined Radio, achieving an Equal Error Rate of 0.120, and ROC AUC of 0.946. Finally, we analyze its stability over time by introducing a time gap between training and testing data, and its extensibility by introducing new transmitters which have not been seen before. We conclude that our techniques are useful for building systems that are stable over time, can be used immediately with new transmitters without retraining, and provide robustness against spoofing and replay by raising the required budget for attacks.
Widen The Backdoor To Let More Attackers In
Oct 09, 2021


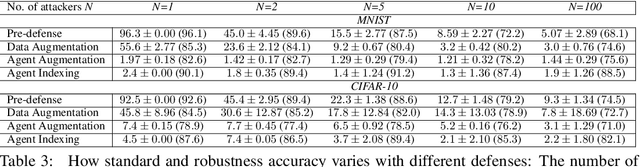
As collaborative learning and the outsourcing of data collection become more common, malicious actors (or agents) which attempt to manipulate the learning process face an additional obstacle as they compete with each other. In backdoor attacks, where an adversary attempts to poison a model by introducing malicious samples into the training data, adversaries have to consider that the presence of additional backdoor attackers may hamper the success of their own backdoor. In this paper, we investigate the scenario of a multi-agent backdoor attack, where multiple non-colluding attackers craft and insert triggered samples in a shared dataset which is used by a model (a defender) to learn a task. We discover a clear backfiring phenomenon: increasing the number of attackers shrinks each attacker's attack success rate (ASR). We then exploit this phenomenon to minimize the collective ASR of attackers and maximize defender's robustness accuracy by (i) artificially augmenting the number of attackers, and (ii) indexing to remove the attacker's sub-dataset from the model for inference, hence proposing 2 defenses.
Signal Injection Attacks against CCD Image Sensors
Aug 19, 2021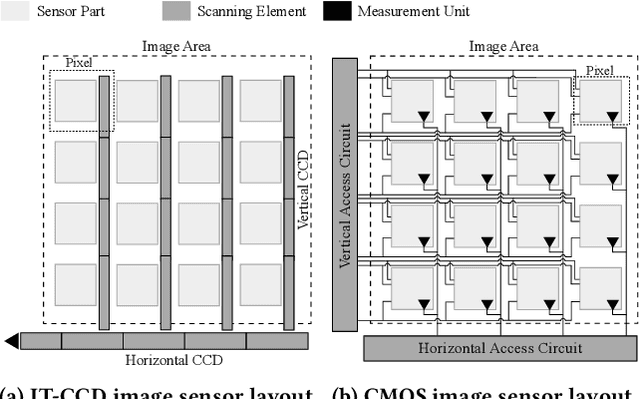


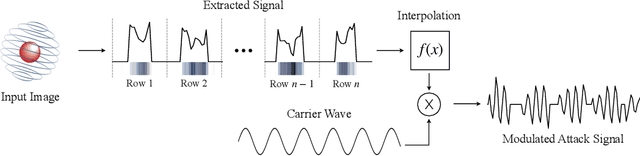
Since cameras have become a crucial part in many safety-critical systems and applications, such as autonomous vehicles and surveillance, a large body of academic and non-academic work has shown attacks against their main component - the image sensor. However, these attacks are limited to coarse-grained and often suspicious injections because light is used as an attack vector. Furthermore, due to the nature of optical attacks, they require the line-of-sight between the adversary and the target camera. In this paper, we present a novel post-transducer signal injection attack against CCD image sensors, as they are used in professional, scientific, and even military settings. We show how electromagnetic emanation can be used to manipulate the image information captured by a CCD image sensor with the granularity down to the brightness of individual pixels. We study the feasibility of our attack and then demonstrate its effects in the scenario of automatic barcode scanning. Our results indicate that the injected distortion can disrupt automated vision-based intelligent systems.
MalPhase: Fine-Grained Malware Detection Using Network Flow Data
Jun 01, 2021


Economic incentives encourage malware authors to constantly develop new, increasingly complex malware to steal sensitive data or blackmail individuals and companies into paying large ransoms. In 2017, the worldwide economic impact of cyberattacks is estimated to be between 445 and 600 billion USD, or 0.8% of global GDP. Traditionally, one of the approaches used to defend against malware is network traffic analysis, which relies on network data to detect the presence of potentially malicious software. However, to keep up with increasing network speeds and amount of traffic, network analysis is generally limited to work on aggregated network data, which is traditionally challenging and yields mixed results. In this paper we present MalPhase, a system that was designed to cope with the limitations of aggregated flows. MalPhase features a multi-phase pipeline for malware detection, type and family classification. The use of an extended set of network flow features and a simultaneous multi-tier architecture facilitates a performance improvement for deep learning models, making them able to detect malicious flows (>98% F1) and categorize them to a respective malware type (>93% F1) and family (>91% F1). Furthermore, the use of robust features and denoising autoencoders allows MalPhase to perform well on samples with varying amounts of benign traffic mixed in. Finally, MalPhase detects unseen malware samples with performance comparable to that of known samples, even when interlaced with benign flows to reflect realistic network environments.
They See Me Rollin': Inherent Vulnerability of the Rolling Shutter in CMOS Image Sensors
Jan 25, 2021



Cameras have become a fundamental component of vision-based intelligent systems. As a balance between production costs and image quality, most modern cameras use Complementary Metal-Oxide Semiconductor image sensors that implement an electronic rolling shutter mechanism, where image rows are captured consecutively rather than all-at-once. In this paper, we describe how the electronic rolling shutter can be exploited using a bright, modulated light source (e.g., an inexpensive, off-the-shelf laser), to inject fine-grained image disruptions. These disruptions substantially affect camera-based computer vision systems, where high-frequency data is crucial in extracting informative features from objects. We study the fundamental factors affecting a rolling shutter attack, such as environmental conditions, angle of the incident light, laser to camera distance, and aiming precision. We demonstrate how these factors affect the intensity of the injected distortion and how an adversary can take them into account by modeling the properties of the camera. We introduce a general pipeline of a practical attack, which consists of: (i) profiling several properties of the target camera and (ii) partially simulating the attack to find distortions that satisfy the adversary's goal. Then, we instantiate the attack to the scenario of object detection, where the adversary's goal is to maximally disrupt the detection of objects in the image. We show that the adversary can modulate the laser to hide up to 75% of objects perceived by state-of-the-art detectors while controlling the amount of perturbation to keep the attack inconspicuous. Our results indicate that rolling shutter attacks can substantially reduce the performance and reliability of vision-based intelligent systems.
Speaker Anonymization with Distribution-Preserving X-Vector Generation for the VoicePrivacy Challenge 2020
Oct 26, 2020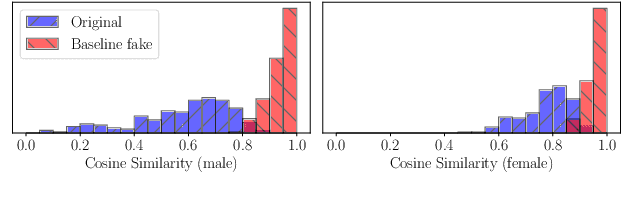
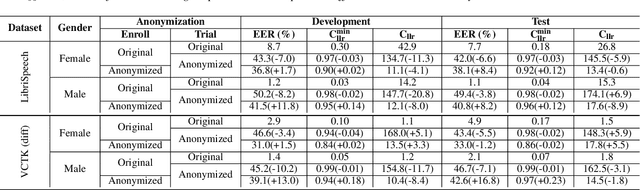
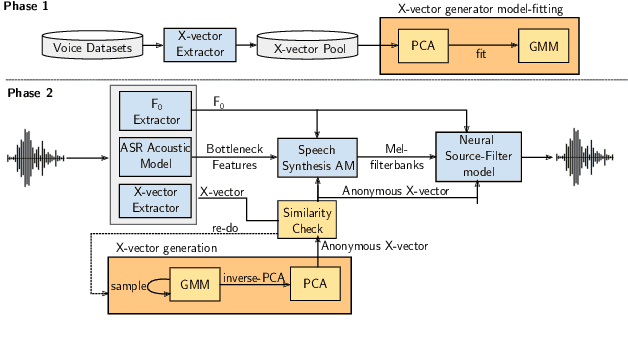
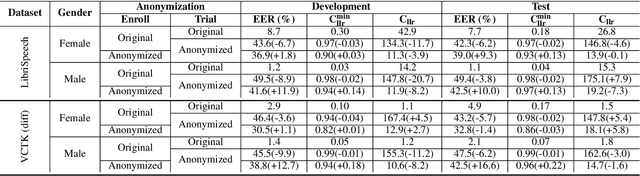
In this paper, we present a Distribution-Preserving Voice Anonymization technique, as our submission to the VoicePrivacy Challenge 2020. We notice that the challenge baseline system generates fake X-vectors which are very similar to each other, significantly more so than those extracted from organic speakers. This difference arises from averaging many X-vectors from a pool of speakers in the anonymization processs, causing a loss of information. We propose a new method to generate fake X-vectors which overcomes these limitations by preserving the distributional properties of X-vectors and their intra-similarity. We use population data to learn the properties of the X-vector space, before fitting a generative model which we use to sample fake X-vectors. We show how this approach generates X-vectors that more closely follow the expected intra-similarity distribution of organic speaker X-vectors. Our method can be easily integrated with others as the anonymization component of the system and removes the need to distribute a pool of speakers to use during the anonymization. Our approach leads to an increase in EER of up to 16.8\% in males and 8.4\% in females in scenarios where enrollment and trial utterances are anonymized versus the baseline solution, demonstrating the diversity of our generated voices.
SLAP: Improving Physical Adversarial Examples with Short-Lived Adversarial Perturbations
Jul 08, 2020
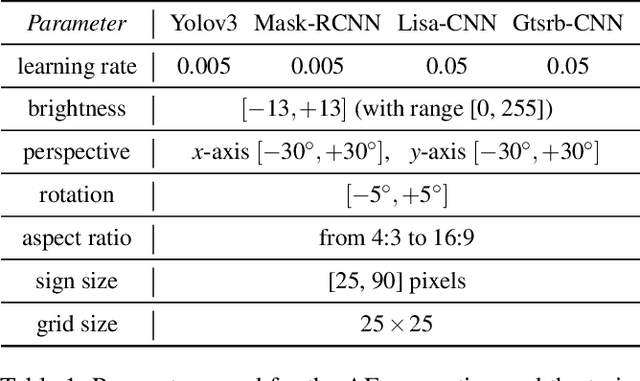

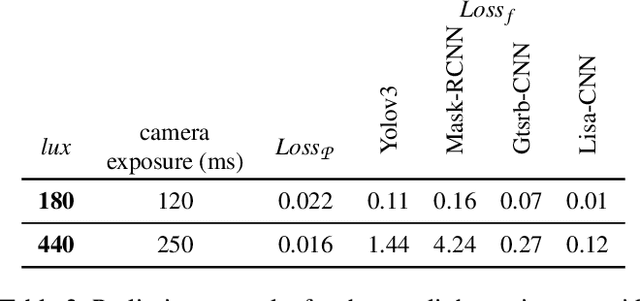
Whilst significant research effort into adversarial examples (AE) has emerged in recent years, the main vector to realize these attacks in the real-world currently relies on static adversarial patches, which are limited in their conspicuousness and can not be modified once deployed. In this paper, we propose Short-Lived Adversarial Perturbations (SLAP), a novel technique that allows adversaries to realize robust, dynamic real-world AE from a distance. As we show in this paper, such attacks can be achieved using a light projector to shine a specifically crafted adversarial image in order to perturb real-world objects and transform them into AE. This allows the adversary greater control over the attack compared to adversarial patches: (i) projections can be dynamically turned on and off or modified at will, (ii) projections do not suffer from the locality constraint imposed by patches, making them harder to detect. We study the feasibility of SLAP in the self-driving scenario, targeting both object detector and traffic sign recognition tasks. We demonstrate that the proposed method generates AE that are robust to different environmental conditions for several networks and lighting conditions: we successfully cause misclassifications of state-of-the-art networks such as Yolov3 and Mask-RCNN with up to 98% success rate for a variety of angles and distances. Additionally, we demonstrate that AE generated with SLAP can bypass SentiNet, a recent AE detection method which relies on the fact that adversarial patches generate highly salient and localized areas in the input images.