 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAYA: Addressing Inconsistencies in Generative Password Guessing through a Unified Benchmark
Apr 23, 2025



The rapid evolution of generative models has led to their integration across various fields, including password guessing, aiming to generate passwords that resemble human-created ones in complexity, structure, and patterns. Despite generative model's promise, inconsistencies in prior research and a lack of rigorous evaluation have hindered a comprehensive understanding of their true potential. In this paper, we introduce MAYA, a unified, customizable, plug-and-play password benchmarking framework. MAYA provides a standardized approach for evaluating generative password-guessing models through a rigorous set of advanced testing scenarios and a collection of eight real-life password datasets. Using MAYA, we comprehensively evaluate six state-of-the-art approaches, which have been re-implemented and adapted to ensure standardization, for a total of over 15,000 hours of computation. Our findings indicate that these models effectively capture different aspects of human password distribution and exhibit strong generalization capabilities. However, their effectiveness varies significantly with long and complex passwords. Through our evaluation, sequential models consistently outperform other generative architectures and traditional password-guessing tools, demonstrating unique capabilities in generating accurate and complex guesses. Moreover, models learn and generate different password distributions, enabling a multi-model attack that outperforms the best individual model. By releasing MAYA, we aim to foster further research, providing the community with a new tool to consistently and reliably benchmark password-generation techniques. Our framework is publicly available at https://github.com/williamcorrias/MAYA-Password-Benchmarking
Have You Poisoned My Data? Defending Neural Networks against Data Poisoning
Mar 20, 2024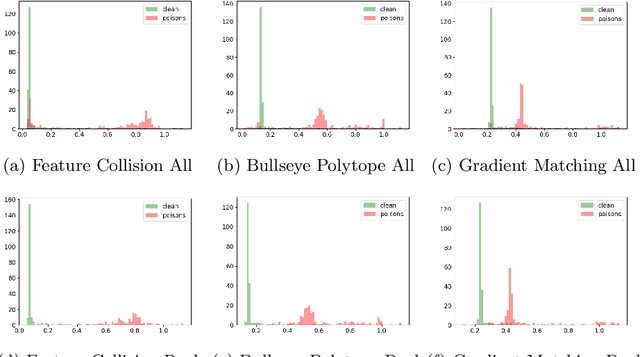



The unprecedented availability of training data fueled the rapid development of powerful neural networks in recent years. However, the need for such large amounts of data leads to potential threats such as poisoning attacks: adversarial manipulations of the training data aimed at compromising the learned model to achieve a given adversarial goal. This paper investigates defenses against clean-label poisoning attacks and proposes a novel approach to detect and filter poisoned datapoints in the transfer learning setting. We define a new characteristic vector representation of datapoints and show that it effectively captures the intrinsic properties of the data distribution. Through experimental analysis, we demonstrate that effective poisons can be successfully differentiated from clean points in the characteristic vector space. We thoroughly evaluate our proposed approach and compare it to existing state-of-the-art defenses using multiple architectures, datasets, and poison budgets. Our evaluation shows that our proposal outperforms existing approaches in defense rate and final trained model performance across all experimental settings.
Do You Trust Your Model? Emerging Malware Threats in the Deep Learning Ecosystem
Mar 06, 2024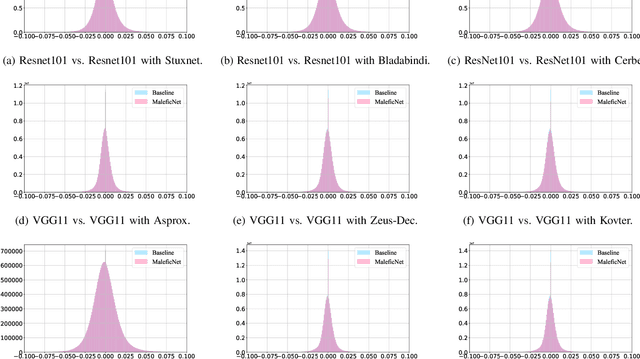
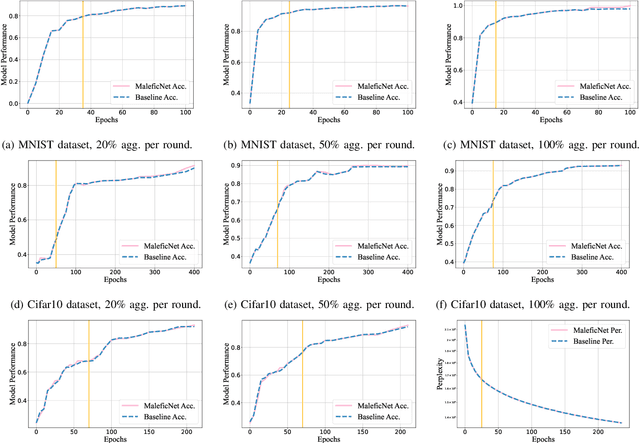
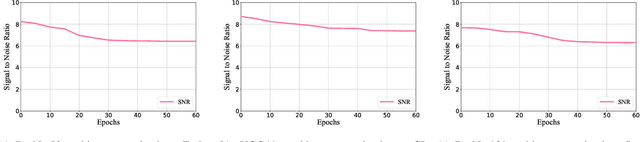
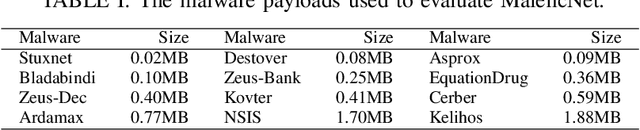
Training high-quality deep learning models is a challenging task due to computational and technical requirements. A growing number of individuals, institutions, and companies increasingly rely on pre-trained, third-party models made available in public repositories. These models are often used directly or integrated in product pipelines with no particular precautions, since they are effectively just data in tensor form and considered safe. In this paper, we raise awareness of a new machine learning supply chain threat targeting neural networks. We introduce MaleficNet 2.0, a novel technique to embed self-extracting, self-executing malware in neural networks. MaleficNet 2.0 uses spread-spectrum channel coding combined with error correction techniques to inject malicious payloads in the parameters of deep neural networks. MaleficNet 2.0 injection technique is stealthy, does not degrade the performance of the model, and is robust against removal techniques. We design our approach to work both in traditional and distributed learning settings such as Federated Learning, and demonstrate that it is effective even when a reduced number of bits is used for the model parameters. Finally, we implement a proof-of-concept self-extracting neural network malware using MaleficNet 2.0, demonstrating the practicality of the attack against a widely adopted machine learning framework. Our aim with this work is to raise awareness against these new, dangerous attacks both in the research community and industry, and we hope to encourage further research in mitigation techniques against such threats.
OliVaR: Improving Olive Variety Recognition using Deep Neural Networks
Mar 01, 2023

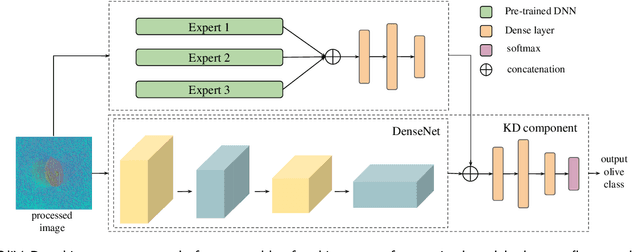

The easy and accurate identification of varieties is fundamental in agriculture, especially in the olive sector, where more than 1200 olive varieties are currently known worldwide. Varietal misidentification leads to many potential problems for all the actors in the sector: farmers and nursery workers may establish the wrong variety, leading to its maladaptation in the field; olive oil and table olive producers may label and sell a non-authentic product; consumers may be misled; and breeders may commit errors during targeted crossings between different varieties. To date, the standard for varietal identification and certification consists of two methods: morphological classification and genetic analysis. The morphological classification consists of the visual pairwise comparison of different organs of the olive tree, where the most important organ is considered to be the endocarp. In contrast, different methods for genetic classification exist (RAPDs, SSR, and SNP). Both classification methods present advantages and disadvantages. Visual morphological classification requires highly specialized personnel and is prone to human error. Genetic identification methods are more accurate but incur a high cost and are difficult to implement. This paper introduces OliVaR, a novel approach to olive varietal identification. OliVaR uses a teacher-student deep learning architecture to learn the defining characteristics of the endocarp of each specific olive variety and perform classification. We construct what is, to the best of our knowledge, the largest olive variety dataset to date, comprising image data for 131 varieties from the Mediterranean basin. We thoroughly test OliVaR on this dataset and show that it correctly predicts olive varieties with over 86% accuracy.
Minerva: A File-Based Ransomware Detector
Jan 26, 2023Ransomware is a rapidly evolving type of malware designed to encrypt user files on a device, making them inaccessible in order to exact a ransom. Ransomware attacks resulted in billions of dollars in damages in recent years and are expected to cause hundreds of billions more in the next decade. With current state-of-the-art process-based detectors being heavily susceptible to evasion attacks, no comprehensive solution to this problem is available today. This paper presents Minerva, a new approach to ransomware detection. Unlike current methods focused on identifying ransomware based on process-level behavioral modeling, Minerva detects ransomware by building behavioral profiles of files based on all the operations they receive in a time window. Minerva addresses some of the critical challenges associated with process-based approaches, specifically their vulnerability to complex evasion attacks. Our evaluation of Minerva demonstrates its effectiveness in detecting ransomware attacks, including those that are able to bypass existing defenses. Our results show that Minerva identifies ransomware activity with an average accuracy of 99.45% and an average recall of 99.66%, with 99.97% of ransomware detected within 1 second.
MalPhase: Fine-Grained Malware Detection Using Network Flow Data
Jun 01, 2021


Economic incentives encourage malware authors to constantly develop new, increasingly complex malware to steal sensitive data or blackmail individuals and companies into paying large ransoms. In 2017, the worldwide economic impact of cyberattacks is estimated to be between 445 and 600 billion USD, or 0.8% of global GDP. Traditionally, one of the approaches used to defend against malware is network traffic analysis, which relies on network data to detect the presence of potentially malicious software. However, to keep up with increasing network speeds and amount of traffic, network analysis is generally limited to work on aggregated network data, which is traditionally challenging and yields mixed results. In this paper we present MalPhase, a system that was designed to cope with the limitations of aggregated flows. MalPhase features a multi-phase pipeline for malware detection, type and family classification. The use of an extended set of network flow features and a simultaneous multi-tier architecture facilitates a performance improvement for deep learning models, making them able to detect malicious flows (>98% F1) and categorize them to a respective malware type (>93% F1) and family (>91% F1). Furthermore, the use of robust features and denoising autoencoders allows MalPhase to perform well on samples with varying amounts of benign traffic mixed in. Finally, MalPhase detects unseen malware samples with performance comparable to that of known samples, even when interlaced with benign flows to reflect realistic network environments.
PassFlow: Guessing Passwords with Generative Flows
May 13, 2021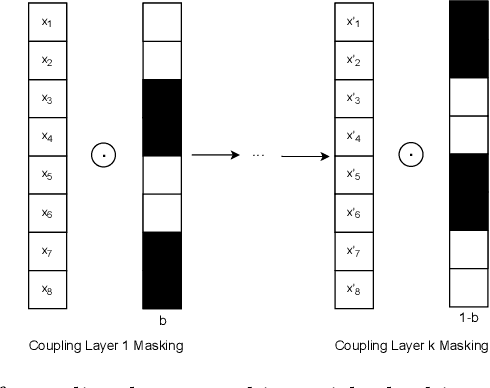

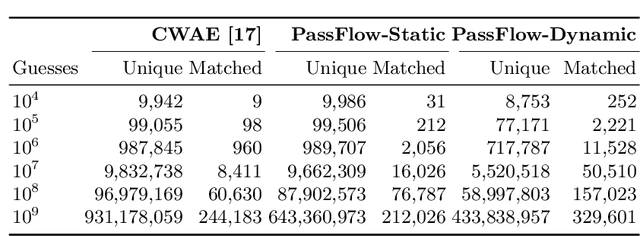

Recent advances in generative machine learning models rekindled research interest in the area of password guessing. Data-driven password guessing approaches based on GANs, language models and deep latent variable models show impressive generalization performance and offer compelling properties for the task of password guessing. In this paper, we propose a flow-based generative model approach to password guessing. Flow-based models allow for precise log-likelihood computation and optimization, which enables exact latent variable inference. Additionally, flow-based models provide meaningful latent space representation, which enables operations such as exploration of specific subspaces of the latent space and interpolation. We demonstrate the applicability of generative flows to the context of password guessing, departing from previous applications of flow networks which are mainly limited to the continuous space of image generation. We show that the above-mentioned properties allow flow-based models to outperform deep latent variable model approaches and remain competitive with state-of-the-art GANs in the password guessing task, while using a training set that is orders of magnitudes smaller than that of previous art. Furthermore, a qualitative analysis of the generated samples shows that flow-based networks are able to accurately model the original passwords distribution, with even non-matched samples closely resembling human-like passwords.
Reliable Detection of Compressed and Encrypted Data
Mar 31, 2021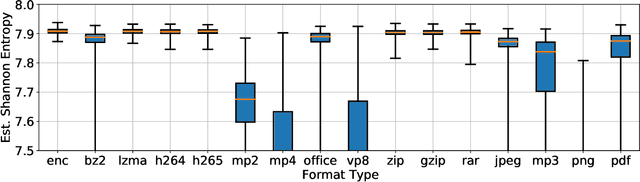
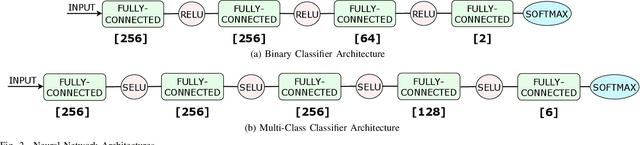
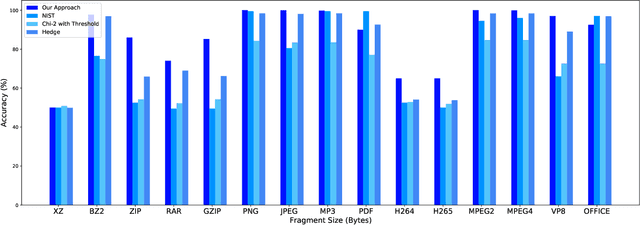
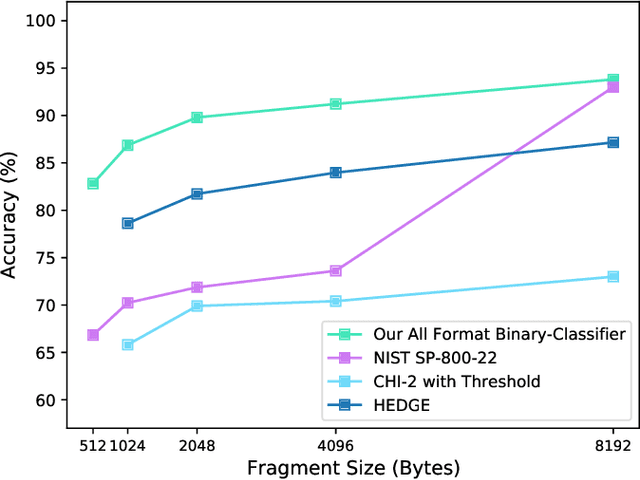
Several cybersecurity domains, such as ransomware detection, forensics and data analysis, require methods to reliably identify encrypted data fragments. Typically, current approaches employ statistics derived from byte-level distribution, such as entropy estimation, to identify encrypted fragments. However, modern content types use compression techniques which alter data distribution pushing it closer to the uniform distribution. The result is that current approaches exhibit unreliable encryption detection performance when compressed data appears in the dataset. Furthermore, proposed approaches are typically evaluated over few data types and fragment sizes, making it hard to assess their practical applicability. This paper compares existing statistical tests on a large, standardized dataset and shows that current approaches consistently fail to distinguish encrypted and compressed data on both small and large fragment sizes. We address these shortcomings and design EnCoD, a learning-based classifier which can reliably distinguish compressed and encrypted data. We evaluate EnCoD on a dataset of 16 different file types and fragment sizes ranging from 512B to 8KB. Our results highlight that EnCoD outperforms current approaches by a wide margin, with accuracy ranging from ~82 for 512B fragments up to ~92 for 8KB data fragments. Moreover, EnCoD can pinpoint the exact format of a given data fragment, rather than performing only binary classification like previous approaches.
EnCoD: Distinguishing Compressed and Encrypted File Fragments
Oct 15, 2020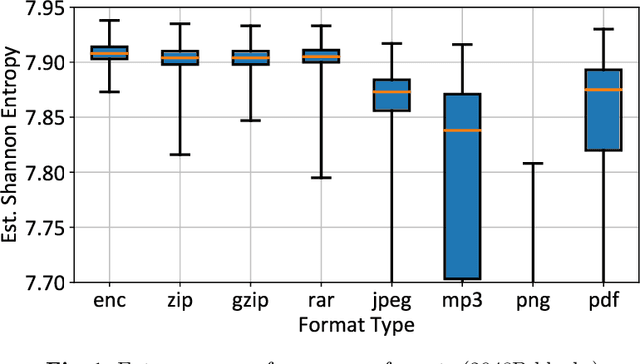
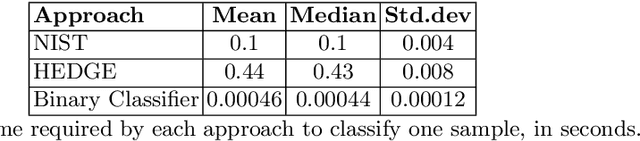
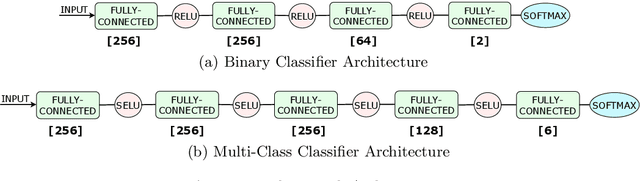
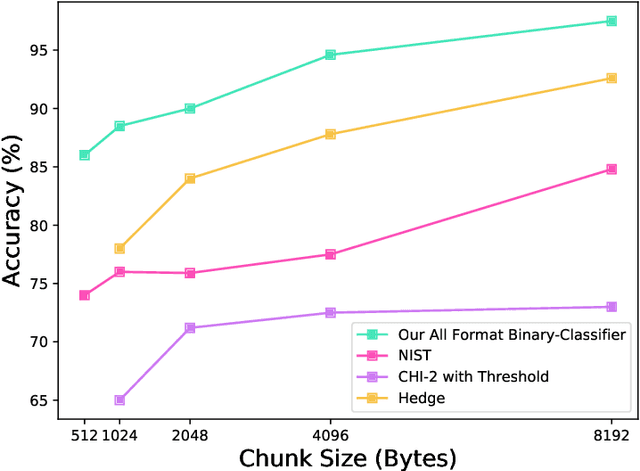
Reliable identification of encrypted file fragments is a requirement for several security applications, including ransomware detection, digital forensics, and traffic analysis. A popular approach consists of estimating high entropy as a proxy for randomness. However, many modern content types (e.g. office documents, media files, etc.) are highly compressed for storage and transmission efficiency. Compression algorithms also output high-entropy data, thus reducing the accuracy of entropy-based encryption detectors. Over the years, a variety of approaches have been proposed to distinguish encrypted file fragments from high-entropy compressed fragments. However, these approaches are typically only evaluated over a few, select data types and fragment sizes, which makes a fair assessment of their practical applicability impossible. This paper aims to close this gap by comparing existing statistical tests on a large, standardized dataset. Our results show that current approaches cannot reliably tell apart encryption and compression, even for large fragment sizes. To address this issue, we design EnCoD, a learning-based classifier which can reliably distinguish compressed and encrypted data, starting with fragments as small as 512 bytes. We evaluate EnCoD against current approaches over a large dataset of different data types, showing that it outperforms current state-of-the-art for most considered fragment sizes and data types.
The Naked Sun: Malicious Cooperation Between Benign-Looking Processes
Nov 06, 2019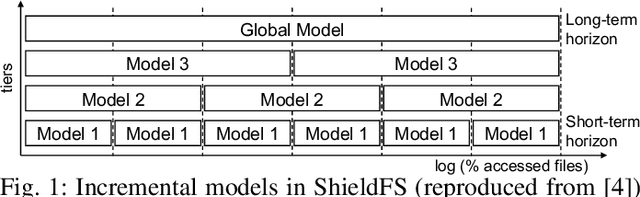
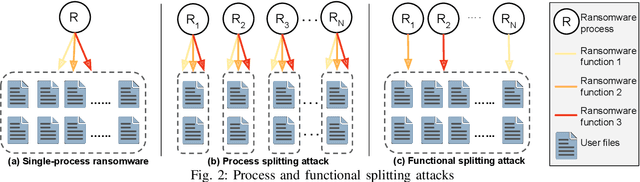
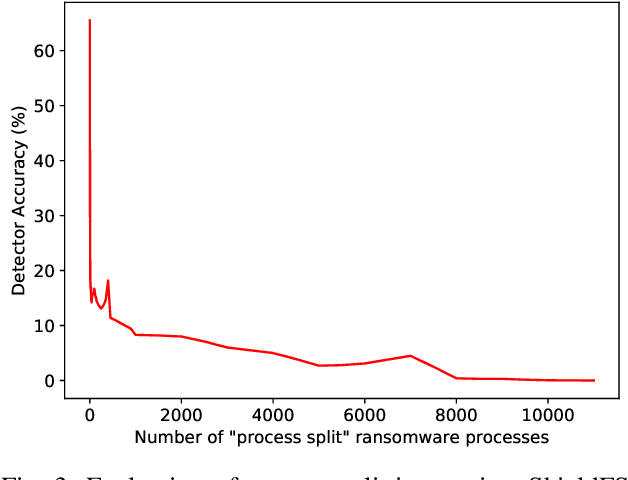
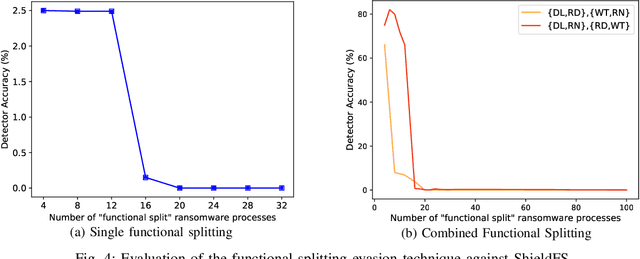
Recent progress in machine learning has generated promising results in behavioral malware detection. Behavioral modeling identifies malicious processes via features derived by their runtime behavior. Behavioral features hold great promise as they are intrinsically related to the functioning of each malware, and are therefore considered difficult to evade. Indeed, while a significant amount of results exists on evasion of static malware features, evasion of dynamic features has seen limited work. This paper thoroughly examines the robustness of behavioral malware detectors to evasion, focusing particularly on anti-ransomware evasion. We choose ransomware as its behavior tends to differ significantly from that of benign processes, making it a low-hanging fruit for behavioral detection (and a difficult candidate for evasion). Our analysis identifies a set of novel attacks that distribute the overall malware workload across a small set of cooperating processes to avoid the generation of significant behavioral features. Our most effective attack decreases the accuracy of a state-of-the-art classifier from 98.6% to 0% using only 18 cooperating processes. Furthermore, we show our attacks to be effective against commercial ransomware detectors even in a black-box setting.