 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo You Trust Your Model? Emerging Malware Threats in the Deep Learning Ecosystem
Mar 06, 2024
Training high-quality deep learning models is a challenging task due to computational and technical requirements. A growing number of individuals, institutions, and companies increasingly rely on pre-trained, third-party models made available in public repositories. These models are often used directly or integrated in product pipelines with no particular precautions, since they are effectively just data in tensor form and considered safe. In this paper, we raise awareness of a new machine learning supply chain threat targeting neural networks. We introduce MaleficNet 2.0, a novel technique to embed self-extracting, self-executing malware in neural networks. MaleficNet 2.0 uses spread-spectrum channel coding combined with error correction techniques to inject malicious payloads in the parameters of deep neural networks. MaleficNet 2.0 injection technique is stealthy, does not degrade the performance of the model, and is robust against removal techniques. We design our approach to work both in traditional and distributed learning settings such as Federated Learning, and demonstrate that it is effective even when a reduced number of bits is used for the model parameters. Finally, we implement a proof-of-concept self-extracting neural network malware using MaleficNet 2.0, demonstrating the practicality of the attack against a widely adopted machine learning framework. Our aim with this work is to raise awareness against these new, dangerous attacks both in the research community and industry, and we hope to encourage further research in mitigation techniques against such threats.
PassGPT: Password Modeling and (Guided) Generation with Large Language Models
Jun 14, 2023
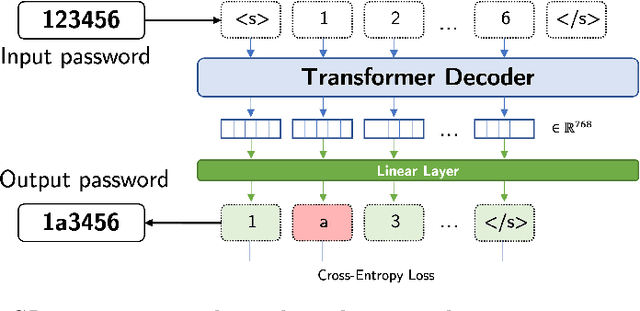
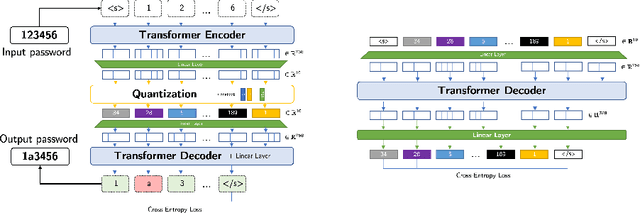

Large language models (LLMs) successfully model natural language from vast amounts of text without the need for explicit supervision. In this paper, we investigate the efficacy of LLMs in modeling passwords. We present PassGPT, a LLM trained on password leaks for password generation. PassGPT outperforms existing methods based on generative adversarial networks (GAN) by guessing twice as many previously unseen passwords. Furthermore, we introduce the concept of guided password generation, where we leverage PassGPT sampling procedure to generate passwords matching arbitrary constraints, a feat lacking in current GAN-based strategies. Lastly, we conduct an in-depth analysis of the entropy and probability distribution that PassGPT defines over passwords and discuss their use in enhancing existing password strength estimators.
Automatic Measures for Evaluating Generative Design Methods for Architects
Mar 20, 2023The recent explosion of high-quality image-to-image methods has prompted interest in applying image-to-image methods towards artistic and design tasks. Of interest for architects is to use these methods to generate design proposals from conceptual sketches, usually hand-drawn sketches that are quickly developed and can embody a design intent. More specifically, instantiating a sketch into a visual that can be used to elicit client feedback is typically a time consuming task, and being able to speed up this iteration time is important. While the body of work in generative methods has been impressive, there has been a mismatch between the quality measures used to evaluate the outputs of these systems and the actual expectations of architects. In particular, most recent image-based works place an emphasis on realism of generated images. While important, this is one of several criteria architects look for. In this work, we describe the expectations architects have for design proposals from conceptual sketches, and identify corresponding automated metrics from the literature. We then evaluate several image-to-image generative methods that may address these criteria and examine their performance across these metrics. From these results, we identify certain challenges with hand-drawn conceptual sketches and describe possible future avenues of investigation to address them.
Revisiting Variable Ordering for Real Quantifier Elimination using Machine Learning
Feb 27, 2023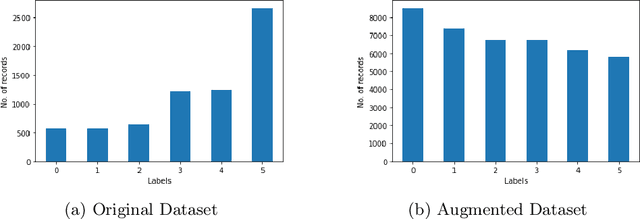
Cylindrical Algebraic Decomposition (CAD) is a key proof technique for formal verification of cyber-physical systems. CAD is computationally expensive, with worst-case doubly-exponential complexity. Selecting an optimal variable ordering is paramount to efficient use of CAD. Prior work has demonstrated that machine learning can be useful in determining efficient variable orderings. Much of this work has been driven by CAD problems extracted from applications of the MetiTarski theorem prover. In this paper, we revisit this prior work and consider issues of bias in existing training and test data. We observe that the classical MetiTarski benchmarks are heavily biased towards particular variable orderings. To address this, we apply symmetries to create a new dataset containing more than 41K MetiTarski challenges designed to remove bias. Furthermore, we evaluate issues of information leakage, and test the generalizability of our models on the new dataset.
Trust in Motion: Capturing Trust Ascendancy in Open-Source Projects using Hybrid AI
Oct 10, 2022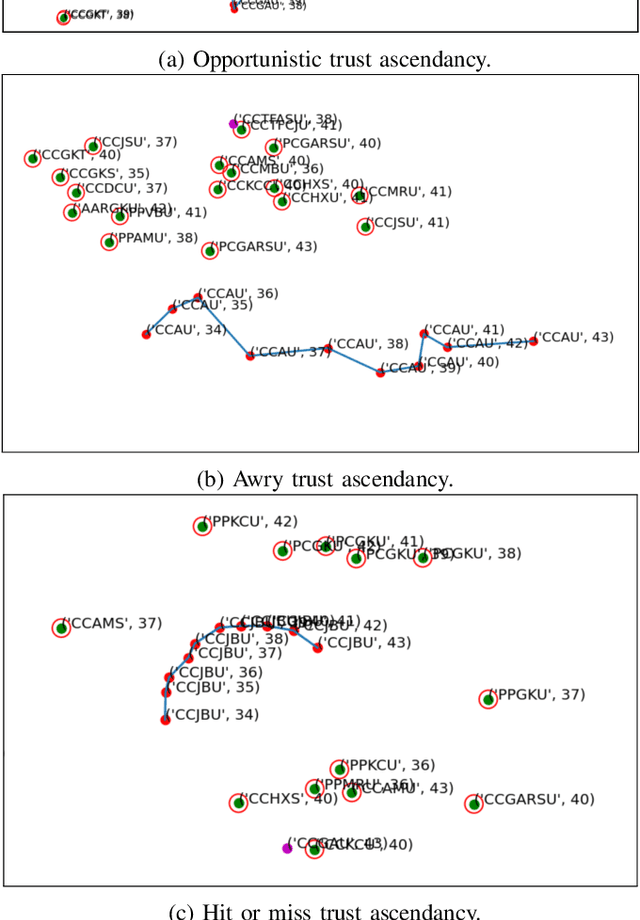
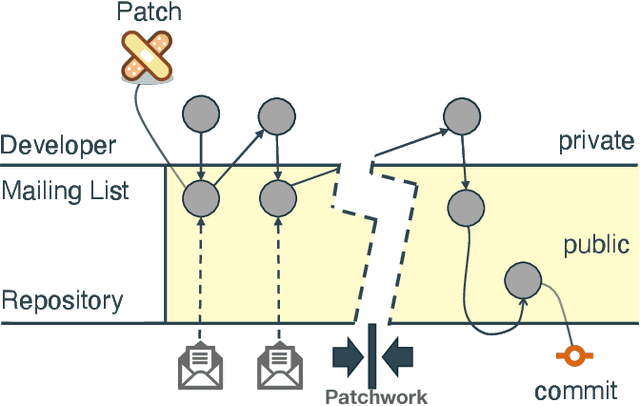
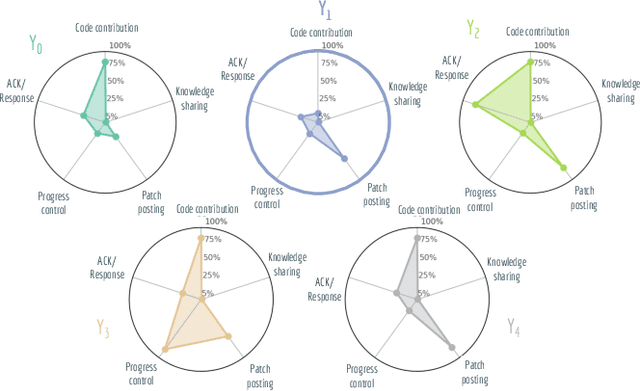

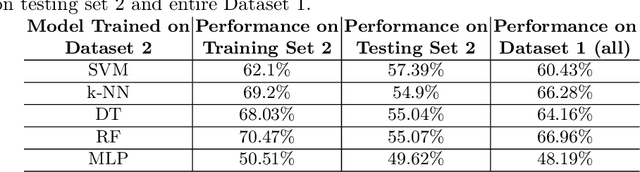
Open-source is frequently described as a driver for unprecedented communication and collaboration, and the process works best when projects support teamwork. Yet, open-source cooperation processes in no way protect project contributors from considerations of trust, power, and influence. Indeed, achieving the level of trust necessary to contribute to a project and thus influence its direction is a constant process of change, and developers take many different routes over many communication channels to achieve it. We refer to this process of influence-seeking and trust-building as trust ascendancy. This paper describes a methodology for understanding the notion of trust ascendancy and introduces the capabilities that are needed to localize trust ascendancy operations happening over open-source projects. Much of the prior work in understanding trust in open-source software development has focused on a static view of the problem using different forms of quantity measures. However, trust ascendancy is not static, but rather adapts to changes in the open-source ecosystem in response to new input. This paper is the first attempt to articulate and study these signals from a dynamic view of the problem. In that respect, we identify related work that may help illuminate research challenges, implementation tradeoffs, and complementary solutions. Our preliminary results show the effectiveness of our method at capturing the trust ascendancy developed by individuals involved in a well-documented 2020 social engineering attack. Our future plans highlight research challenges and encourage cross-disciplinary collaboration to create more automated, accurate, and efficient ways to model and then track trust ascendancy in open-source projects.
Adversarial Scratches: Deployable Attacks to CNN Classifiers
Apr 20, 2022


A growing body of work has shown that deep neural networks are susceptible to adversarial examples. These take the form of small perturbations applied to the model's input which lead to incorrect predictions. Unfortunately, most literature focuses on visually imperceivable perturbations to be applied to digital images that often are, by design, impossible to be deployed to physical targets. We present Adversarial Scratches: a novel L0 black-box attack, which takes the form of scratches in images, and which possesses much greater deployability than other state-of-the-art attacks. Adversarial Scratches leverage B\'ezier Curves to reduce the dimension of the search space and possibly constrain the attack to a specific location. We test Adversarial Scratches in several scenarios, including a publicly available API and images of traffic signs. Results show that, often, our attack achieves higher fooling rate than other deployable state-of-the-art methods, while requiring significantly fewer queries and modifying very few pixels.
TATTOOED: A Robust Deep Neural Network Watermarking Scheme based on Spread-Spectrum Channel Coding
Feb 22, 2022


The proliferation of deep learning applications in several areas has led to the rapid adoption of such solutions from an ever-growing number of institutions and companies. These entities' deep neural network (DNN) models are often trained on proprietary data. They require powerful computational resources, with the resulting DNN models being incorporated in the company's work pipeline or provided as a service. Being trained on proprietary information, these models provide a competitive edge for the owner company. At the same time, these models can be attractive to competitors (or malicious entities), which can employ state-of-the-art security attacks to obtain and use these models for their benefit. As these attacks are hard to prevent, it becomes imperative to have mechanisms that enable an affected entity to verify the ownership of its DNN with high confidence. This paper presents TATTOOED, a robust and efficient DNN watermarking technique based on spread-spectrum channel coding. TATTOOED has a negligible effect on the performance of the DNN model and is robust against several state-of-the-art mechanisms used to remove watermarks from DNNs. Our results show that TATTOOED is robust to such removal techniques even in extreme scenarios. For example, if the removal techniques such as fine-tuning and parameter pruning change as much as 99% of the model parameters, the TATTOOED watermark is still present in full in the DNN model and ensures ownership verification.
FedComm: Federated Learning as a Medium for Covert Communication
Jan 21, 2022
Proposed as a solution to mitigate the privacy implications related to the adoption of deep learning solutions, Federated Learning (FL) enables large numbers of participants to successfully train deep neural networks without having to reveal the actual private training data. To date, a substantial amount of research has investigated the security and privacy properties of FL, resulting in a plethora of innovative attack and defense strategies. This paper thoroughly investigates the communication capabilities of an FL scheme. In particular, we show that a party involved in the FL learning process can use FL as a covert communication medium to send an arbitrary message. We introduce FedComm, a novel covert-communication technique that enables robust sharing and transfer of targeted payloads within the FL framework. Our extensive theoretical and empirical evaluations show that FedComm provides a stealthy communication channel, with minimal disruptions to the training process. Our experiments show that FedComm, allowed us to successfully deliver 100% of a payload in the order of kilobits before the FL procedure converges. Our evaluation also shows that FedComm is independent of the application domain and the neural network architecture used by the underlying FL scheme.
Capture the Bot: Using Adversarial Examples to Improve CAPTCHA Robustness to Bot Attacks
Nov 04, 2020



To this date, CAPTCHAs have served as the first line of defense preventing unauthorized access by (malicious) bots to web-based services, while at the same time maintaining a trouble-free experience for human visitors. However, recent work in the literature has provided evidence of sophisticated bots that make use of advancements in machine learning (ML) to easily bypass existing CAPTCHA-based defenses. In this work, we take the first step to address this problem. We introduce CAPTURE, a novel CAPTCHA scheme based on adversarial examples. While typically adversarial examples are used to lead an ML model astray, with CAPTURE, we attempt to make a "good use" of such mechanisms. Our empirical evaluations show that CAPTURE can produce CAPTCHAs that are easy to solve by humans while at the same time, effectively thwarting ML-based bot solvers.
Scratch that! An Evolution-based Adversarial Attack against Neural Networks
Dec 05, 2019
Recent research has shown that Deep Neural Networks (DNNs) for image classification are vulnerable to adversarial attacks. However, most works on adversarial samples utilize sub-perceptual noise that, while invisible or slightly visible to humans, often covers the entire image. Additionally, most of these attacks often require knowledge of the neural network architecture and its parameters, and the ability to calculate the gradients of the parameters with respect to the inputs. In this work, we show that it is possible to attack neural networks in a highly restricted threat setting, where attackers have no knowledge of the neural network (i.e., in a black-box setting) and can only modify highly localized adversarial noise in the form of randomly chosen straight lines or scratches. Our Adversarial Scratches attack method covers only 1-2% of the image pixels and are generated using the Covariance Matrix Adaptation Evolutionary Strategy, a purely black-box method that does not require knowledge of the neural network architecture and its gradients. Against ImageNet models, Adversarial Scratches requires 3 times fewer queries than GenAttack (without any optimizations) and 73 times fewer queries than ZOO, both prior state-of-the-art black-box attacks. We successfully deceive state-of-the-art Inception-v3, ResNet-50 and VGG-19 models trained on ImageNet with deceiving rates of 75.8%, 62.7%, and 45% respectively, with fewer queries than several state-of-the-art black-box attacks, while modifying less than 2% of the image pixels. Additionally, we provide a new threat scenario for neural networks, demonstrate a new attack surface that can be used to perform adversarial attacks, and discuss its potential implications.