 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Scratches: Deployable Attacks to CNN Classifiers
Apr 20, 2022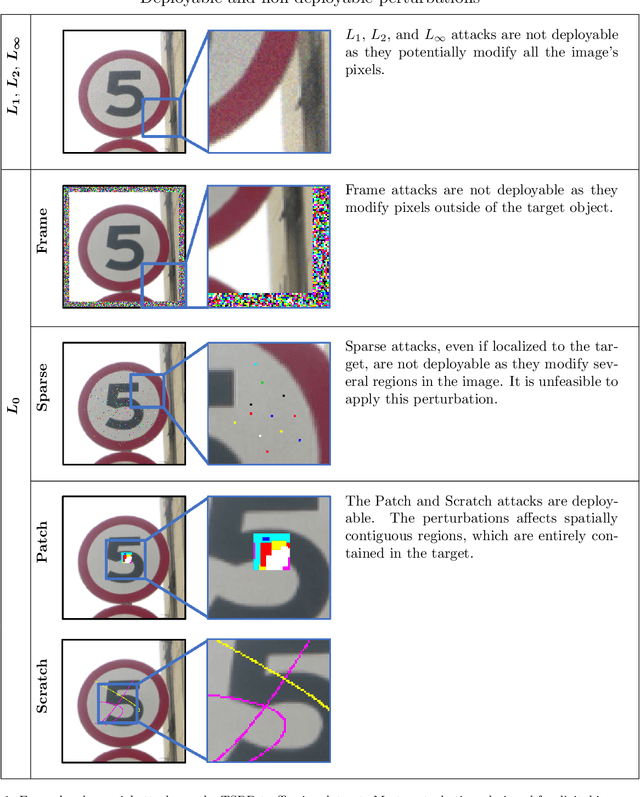
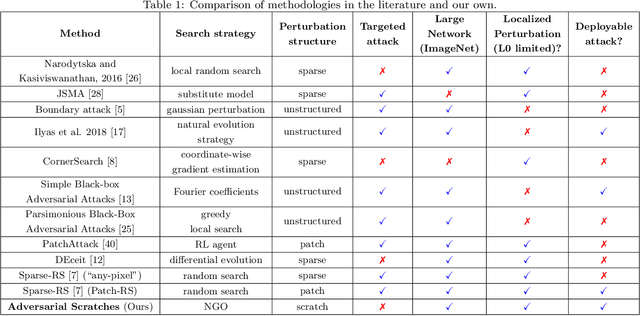


A growing body of work has shown that deep neural networks are susceptible to adversarial examples. These take the form of small perturbations applied to the model's input which lead to incorrect predictions. Unfortunately, most literature focuses on visually imperceivable perturbations to be applied to digital images that often are, by design, impossible to be deployed to physical targets. We present Adversarial Scratches: a novel L0 black-box attack, which takes the form of scratches in images, and which possesses much greater deployability than other state-of-the-art attacks. Adversarial Scratches leverage B\'ezier Curves to reduce the dimension of the search space and possibly constrain the attack to a specific location. We test Adversarial Scratches in several scenarios, including a publicly available API and images of traffic signs. Results show that, often, our attack achieves higher fooling rate than other deployable state-of-the-art methods, while requiring significantly fewer queries and modifying very few pixels.
Scratch that! An Evolution-based Adversarial Attack against Neural Networks
Dec 05, 2019
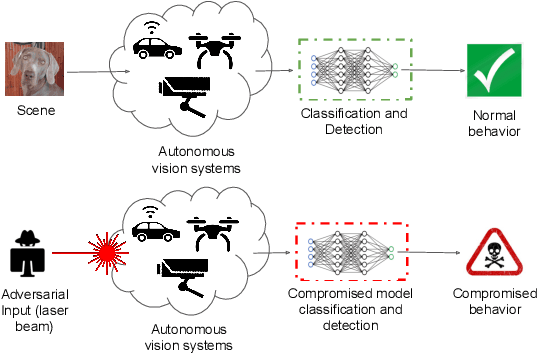
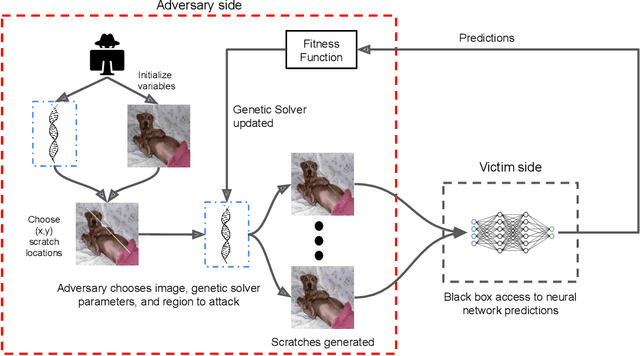
Recent research has shown that Deep Neural Networks (DNNs) for image classification are vulnerable to adversarial attacks. However, most works on adversarial samples utilize sub-perceptual noise that, while invisible or slightly visible to humans, often covers the entire image. Additionally, most of these attacks often require knowledge of the neural network architecture and its parameters, and the ability to calculate the gradients of the parameters with respect to the inputs. In this work, we show that it is possible to attack neural networks in a highly restricted threat setting, where attackers have no knowledge of the neural network (i.e., in a black-box setting) and can only modify highly localized adversarial noise in the form of randomly chosen straight lines or scratches. Our Adversarial Scratches attack method covers only 1-2% of the image pixels and are generated using the Covariance Matrix Adaptation Evolutionary Strategy, a purely black-box method that does not require knowledge of the neural network architecture and its gradients. Against ImageNet models, Adversarial Scratches requires 3 times fewer queries than GenAttack (without any optimizations) and 73 times fewer queries than ZOO, both prior state-of-the-art black-box attacks. We successfully deceive state-of-the-art Inception-v3, ResNet-50 and VGG-19 models trained on ImageNet with deceiving rates of 75.8%, 62.7%, and 45% respectively, with fewer queries than several state-of-the-art black-box attacks, while modifying less than 2% of the image pixels. Additionally, we provide a new threat scenario for neural networks, demonstrate a new attack surface that can be used to perform adversarial attacks, and discuss its potential implications.