 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network-Based Predictive Modeling for Robotic Plaster Printing
Mar 31, 2025
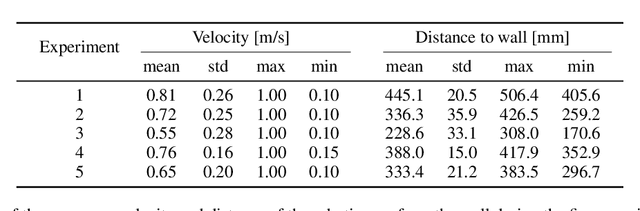

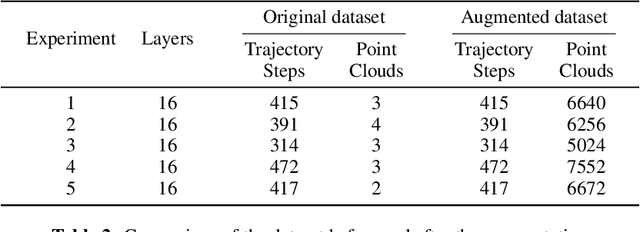
This work proposes a Graph Neural Network (GNN) modeling approach to predict the resulting surface from a particle based fabrication process. The latter consists of spray-based printing of cementitious plaster on a wall and is facilitated with the use of a robotic arm. The predictions are computed using the robotic arm trajectory features, such as position, velocity and direction, as well as the printing process parameters. The proposed approach, based on a particle representation of the wall domain and the end effector, allows for the adoption of a graph-based solution. The GNN model consists of an encoder-processor-decoder architecture and is trained using data from laboratory tests, while the hyperparameters are optimized by means of a Bayesian scheme. The aim of this model is to act as a simulator of the printing process, and ultimately used for the generation of the robotic arm trajectory and the optimization of the printing parameters, towards the materialization of an autonomous plastering process. The performance of the proposed model is assessed in terms of the prediction error against unseen ground truth data, which shows its generality in varied scenarios, as well as in comparison with the performance of an existing benchmark model. The results demonstrate a significant improvement over the benchmark model, with notably better performance and enhanced error scaling across prediction steps.
A Closer Look at Benchmarking Self-Supervised Pre-training with Image Classification
Jul 18, 2024



Self-supervised learning (SSL) is a machine learning approach where the data itself provides supervision, eliminating the need for external labels. The model is forced to learn about the data structure or context by solving a pretext task. With SSL, models can learn from abundant and cheap unlabeled data, significantly reducing the cost of training models where labels are expensive or inaccessible. In Computer Vision, SSL is widely used as pre-training followed by a downstream task, such as supervised transfer, few-shot learning on smaller labeled data sets, and/or unsupervised clustering. Unfortunately, it is infeasible to evaluate SSL methods on all possible downstream tasks and objectively measure the quality of the learned representation. Instead, SSL methods are evaluated using in-domain evaluation protocols, such as fine-tuning, linear probing, and k-nearest neighbors (kNN). However, it is not well understood how well these evaluation protocols estimate the representation quality of a pre-trained model for different downstream tasks under different conditions, such as dataset, metric, and model architecture. We study how classification-based evaluation protocols for SSL correlate and how well they predict downstream performance on different dataset types. Our study includes eleven common image datasets and 26 models that were pre-trained with different SSL methods or have different model backbones. We find that in-domain linear/kNN probing protocols are, on average, the best general predictors for out-of-domain performance. We further investigate the importance of batch normalization and evaluate how robust correlations are for different kinds of dataset domain shifts. We challenge assumptions about the relationship between discriminative and generative self-supervised methods, finding that most of their performance differences can be explained by changes to model backbones.
Counterfactual Explanations for Deep Learning-Based Traffic Forecasting
May 01, 2024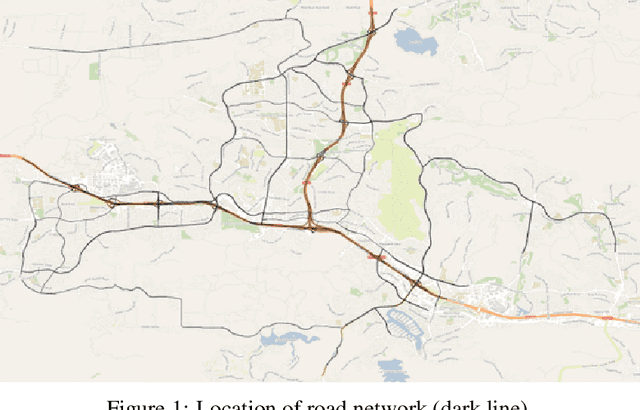
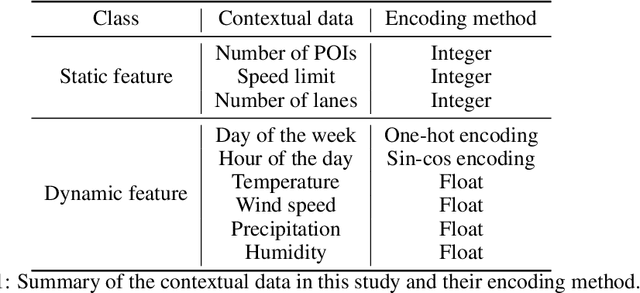
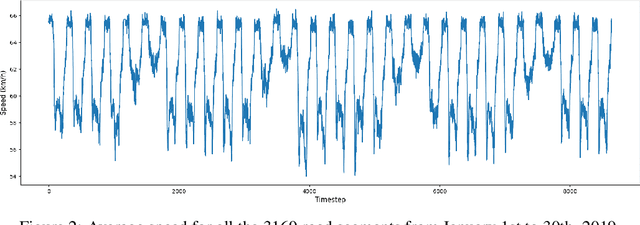

Deep learning models are widely used in traffic forecasting and have achieved state-of-the-art prediction accuracy. However, the black-box nature of those models makes the results difficult to interpret by users. This study aims to leverage an Explainable AI approach, counterfactual explanations, to enhance the explainability and usability of deep learning-based traffic forecasting models. Specifically, the goal is to elucidate relationships between various input contextual features and their corresponding predictions. We present a comprehensive framework that generates counterfactual explanations for traffic forecasting and provides usable insights through the proposed scenario-driven counterfactual explanations. The study first implements a deep learning model to predict traffic speed based on historical traffic data and contextual variables. Counterfactual explanations are then used to illuminate how alterations in these input variables affect predicted outcomes, thereby enhancing the transparency of the deep learning model. We investigated the impact of contextual features on traffic speed prediction under varying spatial and temporal conditions. The scenario-driven counterfactual explanations integrate two types of user-defined constraints, directional and weighting constraints, to tailor the search for counterfactual explanations to specific use cases. These tailored explanations benefit machine learning practitioners who aim to understand the model's learning mechanisms and domain experts who seek insights for real-world applications. The results showcase the effectiveness of counterfactual explanations in revealing traffic patterns learned by deep learning models, showing its potential for interpreting black-box deep learning models used for spatiotemporal predictions in general.
Do You Trust Your Model? Emerging Malware Threats in the Deep Learning Ecosystem
Mar 06, 2024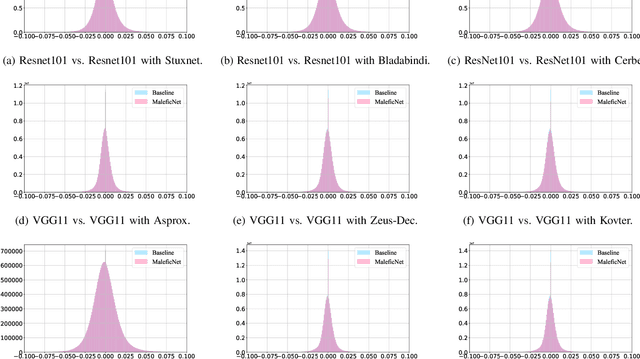
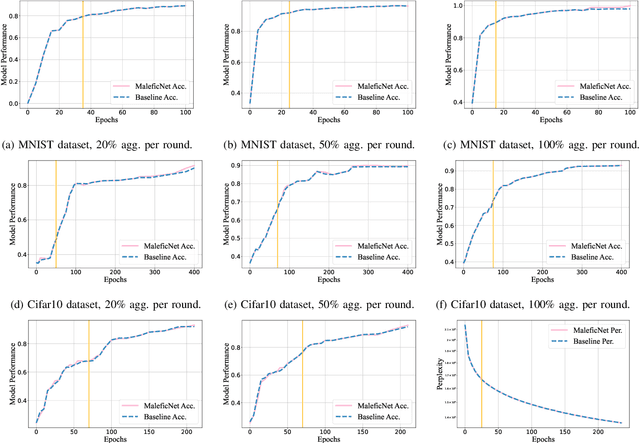
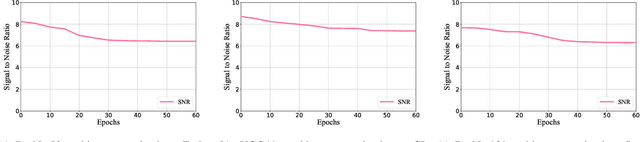
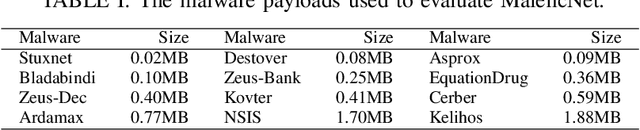
Training high-quality deep learning models is a challenging task due to computational and technical requirements. A growing number of individuals, institutions, and companies increasingly rely on pre-trained, third-party models made available in public repositories. These models are often used directly or integrated in product pipelines with no particular precautions, since they are effectively just data in tensor form and considered safe. In this paper, we raise awareness of a new machine learning supply chain threat targeting neural networks. We introduce MaleficNet 2.0, a novel technique to embed self-extracting, self-executing malware in neural networks. MaleficNet 2.0 uses spread-spectrum channel coding combined with error correction techniques to inject malicious payloads in the parameters of deep neural networks. MaleficNet 2.0 injection technique is stealthy, does not degrade the performance of the model, and is robust against removal techniques. We design our approach to work both in traditional and distributed learning settings such as Federated Learning, and demonstrate that it is effective even when a reduced number of bits is used for the model parameters. Finally, we implement a proof-of-concept self-extracting neural network malware using MaleficNet 2.0, demonstrating the practicality of the attack against a widely adopted machine learning framework. Our aim with this work is to raise awareness against these new, dangerous attacks both in the research community and industry, and we hope to encourage further research in mitigation techniques against such threats.
Synthetic location trajectory generation using categorical diffusion models
Feb 19, 2024
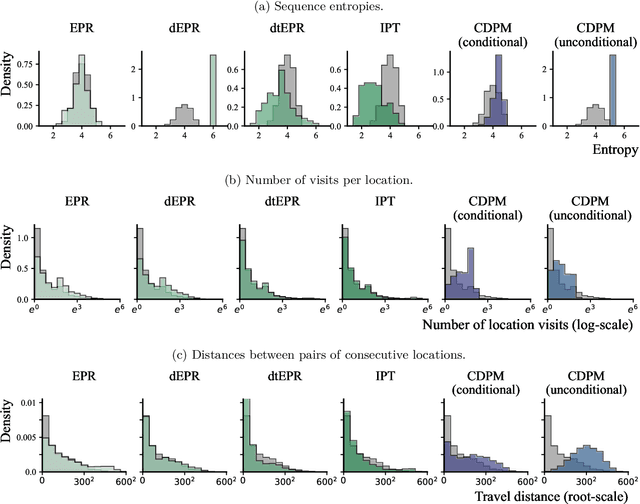
Diffusion probabilistic models (DPMs) have rapidly evolved to be one of the predominant generative models for the simulation of synthetic data, for instance, for computer vision, audio, natural language processing, or biomolecule generation. Here, we propose using DPMs for the generation of synthetic individual location trajectories (ILTs) which are sequences of variables representing physical locations visited by individuals. ILTs are of major importance in mobility research to understand the mobility behavior of populations and to ultimately inform political decision-making. We represent ILTs as multi-dimensional categorical random variables and propose to model their joint distribution using a continuous DPM by first applying the diffusion process in a continuous unconstrained space and then mapping the continuous variables into a discrete space. We demonstrate that our model can synthesize realistic ILPs by comparing conditionally and unconditionally generated sequences to real-world ILPs from a GNSS tracking data set which suggests the potential use of our model for synthetic data generation, for example, for benchmarking models used in mobility research.
Anchor Data Augmentation
Nov 27, 2023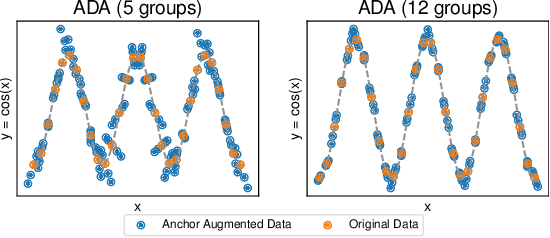

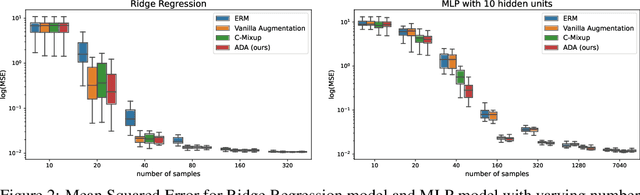

We propose a novel algorithm for data augmentation in nonlinear over-parametrized regression. Our data augmentation algorithm borrows from the literature on causality and extends the recently proposed Anchor regression (AR) method for data augmentation, which is in contrast to the current state-of-the-art domain-agnostic solutions that rely on the Mixup literature. Our Anchor Data Augmentation (ADA) uses several replicas of the modified samples in AR to provide more training examples, leading to more robust regression predictions. We apply ADA to linear and nonlinear regression problems using neural networks. ADA is competitive with state-of-the-art C-Mixup solutions.
Revealing behavioral impact on mobility prediction networks through causal interventions
Nov 20, 2023Deep neural networks are increasingly utilized in mobility prediction tasks, yet their intricate internal workings pose challenges for interpretability, especially in comprehending how various aspects of mobility behavior affect predictions. In this study, we introduce a causal intervention framework to assess the impact of mobility-related factors on neural networks designed for next location prediction -- a task focusing on predicting the immediate next location of an individual. To achieve this, we employ individual mobility models to generate synthetic location visit sequences and control behavior dynamics by intervening in their data generation process. We evaluate the interventional location sequences using mobility metrics and input them into well-trained networks to analyze performance variations. The results demonstrate the effectiveness in producing location sequences with distinct mobility behaviors, thus facilitating the simulation of diverse spatial and temporal changes. These changes result in performance fluctuations in next location prediction networks, revealing impacts of critical mobility behavior factors, including sequential patterns in location transitions, proclivity for exploring new locations, and preferences in location choices at population and individual levels. The gained insights hold significant value for the real-world application of mobility prediction networks, and the framework is expected to promote the use of causal inference for enhancing the interpretability and robustness of neural networks in mobility applications.
Diffusion models for probabilistic programming
Nov 01, 2023We propose Diffusion Model Variational Inference (DMVI), a novel method for automated approximate inference in probabilistic programming languages (PPLs). DMVI utilizes diffusion models as variational approximations to the true posterior distribution by deriving a novel bound to the marginal likelihood objective used in Bayesian modelling. DMVI is easy to implement, allows hassle-free inference in PPLs without the drawbacks of, e.g., variational inference using normalizing flows, and does not make any constraints on the underlying neural network model. We evaluate DMVI on a set of common Bayesian models and show that its posterior inferences are in general more accurate than those of contemporary methods used in PPLs while having a similar computational cost and requiring less manual tuning.
Uncertainty quantification and out-of-distribution detection using surjective normalizing flows
Nov 01, 2023



Reliable quantification of epistemic and aleatoric uncertainty is of crucial importance in applications where models are trained in one environment but applied to multiple different environments, often seen in real-world applications for example, in climate science or mobility analysis. We propose a simple approach using surjective normalizing flows to identify out-of-distribution data sets in deep neural network models that can be computed in a single forward pass. The method builds on recent developments in deep uncertainty quantification and generative modeling with normalizing flows. We apply our method to a synthetic data set that has been simulated using a mechanistic model from the mobility literature and several data sets simulated from interventional distributions induced by soft and atomic interventions on that model, and demonstrate that our method can reliably discern out-of-distribution data from in-distribution data. We compare the surjective flow model to a Dirichlet process mixture model and a bijective flow and find that the surjections are a crucial component to reliably distinguish in-distribution from out-of-distribution data.
Simulation-based inference using surjective sequential neural likelihood estimation
Aug 02, 2023



We present Surjective Sequential Neural Likelihood (SSNL) estimation, a novel method for simulation-based inference in models where the evaluation of the likelihood function is not tractable and only a simulator that can generate synthetic data is available. SSNL fits a dimensionality-reducing surjective normalizing flow model and uses it as a surrogate likelihood function which allows for conventional Bayesian inference using either Markov chain Monte Carlo methods or variational inference. By embedding the data in a low-dimensional space, SSNL solves several issues previous likelihood-based methods had when applied to high-dimensional data sets that, for instance, contain non-informative data dimensions or lie along a lower-dimensional manifold. We evaluate SSNL on a wide variety of experiments and show that it generally outperforms contemporary methods used in simulation-based inference, for instance, on a challenging real-world example from astrophysics which models the magnetic field strength of the sun using a solar dynamo model.