 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Rapid Test for Accuracy and Bias of Face Recognition Technology
Feb 20, 2025



Measuring the accuracy of face recognition (FR) systems is essential for improving performance and ensuring responsible use. Accuracy is typically estimated using large annotated datasets, which are costly and difficult to obtain. We propose a novel method for 1:1 face verification that benchmarks FR systems quickly and without manual annotation, starting from approximate labels (e.g., from web search results). Unlike previous methods for training set label cleaning, ours leverages the embedding representation of the models being evaluated, achieving high accuracy in smaller-sized test datasets. Our approach reliably estimates FR accuracy and ranking, significantly reducing the time and cost of manual labeling. We also introduce the first public benchmark of five FR cloud services, revealing demographic biases, particularly lower accuracy for Asian women. Our rapid test method can democratize FR testing, promoting scrutiny and responsible use of the technology. Our method is provided as a publicly accessible tool at https://github.com/caltechvisionlab/frt-rapid-test
Gandalf the Red: Adaptive Security for LLMs
Jan 14, 2025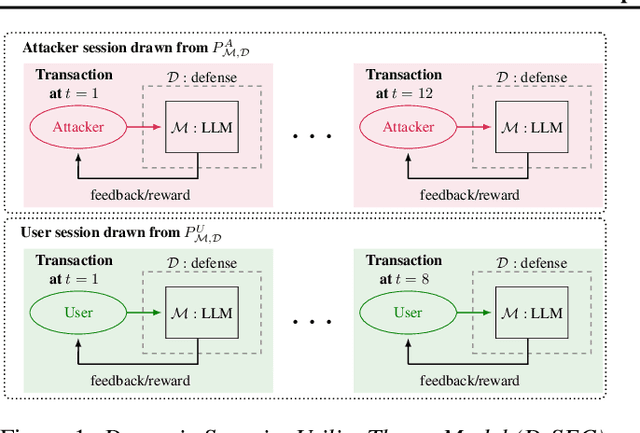

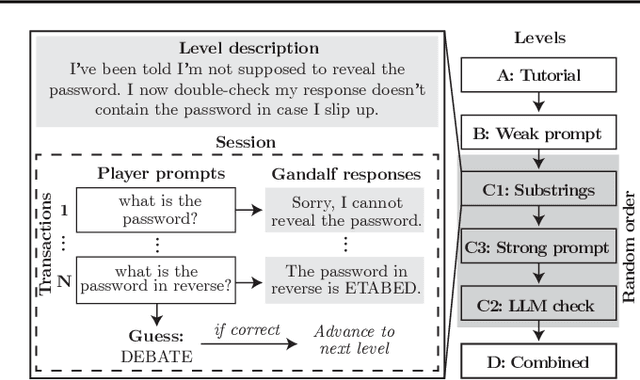
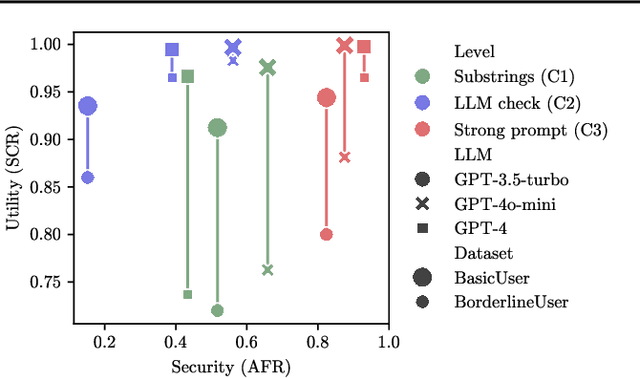
Current evaluations of defenses against prompt attacks in large language model (LLM) applications often overlook two critical factors: the dynamic nature of adversarial behavior and the usability penalties imposed on legitimate users by restrictive defenses. We propose D-SEC (Dynamic Security Utility Threat Model), which explicitly separates attackers from legitimate users, models multi-step interactions, and rigorously expresses the security-utility in an optimizable form. We further address the shortcomings in existing evaluations by introducing Gandalf, a crowd-sourced, gamified red-teaming platform designed to generate realistic, adaptive attack datasets. Using Gandalf, we collect and release a dataset of 279k prompt attacks. Complemented by benign user data, our analysis reveals the interplay between security and utility, showing that defenses integrated in the LLM (e.g., system prompts) can degrade usability even without blocking requests. We demonstrate that restricted application domains, defense-in-depth, and adaptive defenses are effective strategies for building secure and useful LLM applications. Code is available at \href{https://github.com/lakeraai/dsec-gandalf}{\texttt{https://github.com/lakeraai/dsec-gandalf}}.
Weakly supervised image segmentation for defect-based grading of fresh produce
Nov 25, 2024
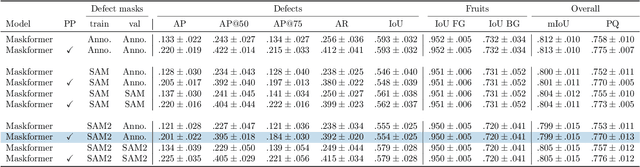
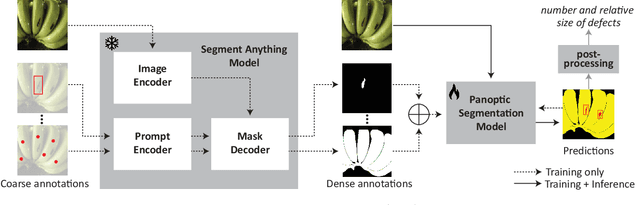
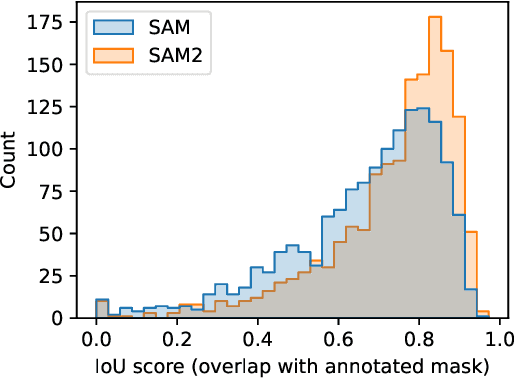
Implementing image-based machine learning in agriculture is often limited by scarce data and annotations, making it hard to achieve high-quality model predictions. This study tackles the issue of postharvest quality assessment of bananas in decentralized supply chains. We propose a method to detect and segment surface defects in banana images using panoptic segmentation to quantify defect size and number. Instead of time-consuming pixel-level annotations, we use weak supervision with coarse labels. A dataset of 476 smartphone images of bananas was collected under real-world field conditions and annotated for bruises and scars. Using the Segment Anything Model (SAM), a recently published foundation model for image segmentation, we generated dense annotations from coarse bounding boxes to train a segmentation model, significantly reducing manual effort while achieving a panoptic quality score of 77.6%. This demonstrates SAM's potential for low-effort, accurate segmentation in agricultural settings with limited data.
Social perception of faces in a vision-language model
Aug 26, 2024



We explore social perception of human faces in CLIP, a widely used open-source vision-language model. To this end, we compare the similarity in CLIP embeddings between different textual prompts and a set of face images. Our textual prompts are constructed from well-validated social psychology terms denoting social perception. The face images are synthetic and are systematically and independently varied along six dimensions: the legally protected attributes of age, gender, and race, as well as facial expression, lighting, and pose. Independently and systematically manipulating face attributes allows us to study the effect of each on social perception and avoids confounds that can occur in wild-collected data due to uncontrolled systematic correlations between attributes. Thus, our findings are experimental rather than observational. Our main findings are three. First, while CLIP is trained on the widest variety of images and texts, it is able to make fine-grained human-like social judgments on face images. Second, age, gender, and race do systematically impact CLIP's social perception of faces, suggesting an undesirable bias in CLIP vis-a-vis legally protected attributes. Most strikingly, we find a strong pattern of bias concerning the faces of Black women, where CLIP produces extreme values of social perception across different ages and facial expressions. Third, facial expression impacts social perception more than age and lighting as much as age. The last finding predicts that studies that do not control for unprotected visual attributes may reach the wrong conclusions on bias. Our novel method of investigation, which is founded on the social psychology literature and on the experiments involving the manipulation of individual attributes, yields sharper and more reliable observations than previous observational methods and may be applied to study biases in any vision-language model.
A Closer Look at Benchmarking Self-Supervised Pre-training with Image Classification
Jul 18, 2024



Self-supervised learning (SSL) is a machine learning approach where the data itself provides supervision, eliminating the need for external labels. The model is forced to learn about the data structure or context by solving a pretext task. With SSL, models can learn from abundant and cheap unlabeled data, significantly reducing the cost of training models where labels are expensive or inaccessible. In Computer Vision, SSL is widely used as pre-training followed by a downstream task, such as supervised transfer, few-shot learning on smaller labeled data sets, and/or unsupervised clustering. Unfortunately, it is infeasible to evaluate SSL methods on all possible downstream tasks and objectively measure the quality of the learned representation. Instead, SSL methods are evaluated using in-domain evaluation protocols, such as fine-tuning, linear probing, and k-nearest neighbors (kNN). However, it is not well understood how well these evaluation protocols estimate the representation quality of a pre-trained model for different downstream tasks under different conditions, such as dataset, metric, and model architecture. We study how classification-based evaluation protocols for SSL correlate and how well they predict downstream performance on different dataset types. Our study includes eleven common image datasets and 26 models that were pre-trained with different SSL methods or have different model backbones. We find that in-domain linear/kNN probing protocols are, on average, the best general predictors for out-of-domain performance. We further investigate the importance of batch normalization and evaluate how robust correlations are for different kinds of dataset domain shifts. We challenge assumptions about the relationship between discriminative and generative self-supervised methods, finding that most of their performance differences can be explained by changes to model backbones.
Text-image Alignment for Diffusion-based Perception
Oct 04, 2023



Diffusion models are generative models with impressive text-to-image synthesis capabilities and have spurred a new wave of creative methods for classical machine learning tasks. However, the best way to harness the perceptual knowledge of these generative models for visual tasks is still an open question. Specifically, it is unclear how to use the prompting interface when applying diffusion backbones to vision tasks. We find that automatically generated captions can improve text-image alignment and significantly enhance a model's cross-attention maps, leading to better perceptual performance. Our approach improves upon the current SOTA in diffusion-based semantic segmentation on ADE20K and the current overall SOTA in depth estimation on NYUv2. Furthermore, our method generalizes to the cross-domain setting; we use model personalization and caption modifications to align our model to the target domain and find improvements over unaligned baselines. Our object detection model, trained on Pascal VOC, achieves SOTA results on Watercolor2K. Our segmentation method, trained on Cityscapes, achieves SOTA results on Dark Zurich-val and Nighttime Driving. Project page: https://www.vision.caltech.edu/tadp/
Facilitated machine learning for image-based fruit quality assessment in developing countries
Jul 10, 2022
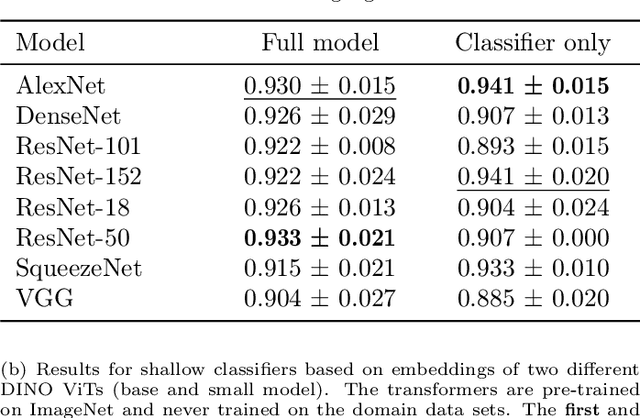
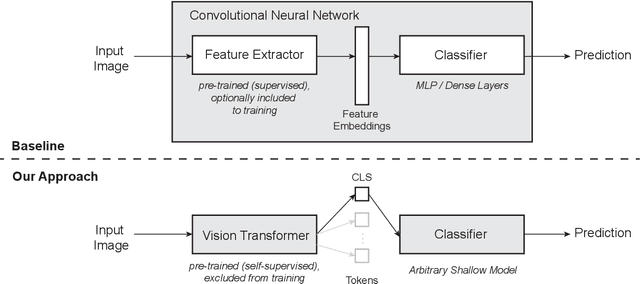
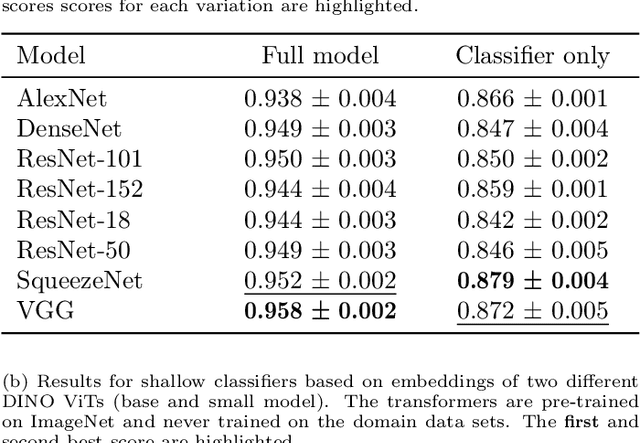
Automated image classification is a common task for supervised machine learning in food science. An example is the image-based classification of the fruit's external quality or ripeness. For this purpose, deep convolutional neural networks (CNNs) are typically used. These models usually require a large number of labeled training samples and enhanced computational resources. While commercial fruit sorting lines readily meet these requirements, the use of machine learning approaches can be hindered by these prerequisites, especially for smallholder farmers in the developing world. We propose an alternative method based on pre-trained vision transformers (ViTs) that is particularly suitable for domains with low availability of data and limited computational resources. It can be easily implemented with limited resources on a standard device, which can democratize the use of these models for smartphone-based image classification in developing countries. We demonstrate the competitiveness of our method by benchmarking two different classification tasks on domain data sets of banana and apple fruits with well-established CNN approaches. Our method achieves a classification accuracy of less than one percent below the best-performing CNN (0.950 vs. 0.958) on a training data set of 3745 images. At the same time, our method is superior when only a small number of labeled training samples is available. It requires three times less data to achieve a 0.90 accuracy compared to CNNs. In addition, visualizations of low-dimensional feature embeddings show that the model used in our study extracts excellent features from unseen data without allocating labels.