 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Causal Effects Using a Single Proxy Variable
Apr 10, 2026Unobserved confounding is a key challenge when estimating causal effects from a treatment on an outcome in scientific applications. In this work, we assume that we observe a single, potentially multi-dimensional proxy variable of the unobserved confounder and that we know the mechanism that generates the proxy from the confounder. Under a completeness assumption on this mechanism, which we call Single Proxy Identifiability of Causal Effects or simply SPICE, we prove that causal effects are identifiable. We extend the proxy-based causal identifiability results by Kuroki and Pearl (2014); Pearl (2010) to higher dimensions, more flexible functional relationships and a broader class of distributions. Further, we develop a neural network based estimation framework, SPICE-Net, to estimate causal effects, which is applicable to both discrete and continuous treatments.
Invariance-Based Dynamic Regret Minimization
Mar 04, 2026We consider stochastic non-stationary linear bandits where the linear parameter connecting contexts to the reward changes over time. Existing algorithms in this setting localize the policy by gradually discarding or down-weighting past data, effectively shrinking the time horizon over which learning can occur. However, in many settings historical data may still carry partial information about the reward model. We propose to leverage such data while adapting to changes, by assuming the reward model decomposes into stationary and non-stationary components. Based on this assumption, we introduce ISD-linUCB, an algorithm that uses past data to learn invariances in the reward model and subsequently exploits them to improve online performance. We show both theoretically and empirically that leveraging invariance reduces the problem dimensionality, yielding significant regret improvements in fast-changing environments when sufficient historical data is available.
Many Experiments, Few Repetitions, Unpaired Data, and Sparse Effects: Is Causal Inference Possible?
Jan 21, 2026We study the problem of estimating causal effects under hidden confounding in the following unpaired data setting: we observe some covariates $X$ and an outcome $Y$ under different experimental conditions (environments) but do not observe them jointly; we either observe $X$ or $Y$. Under appropriate regularity conditions, the problem can be cast as an instrumental variable (IV) regression with the environment acting as a (possibly high-dimensional) instrument. When there are many environments but only a few observations per environment, standard two-sample IV estimators fail to be consistent. We propose a GMM-type estimator based on cross-fold sample splitting of the instrument-covariate sample and prove that it is consistent as the number of environments grows but the sample size per environment remains constant. We further extend the method to sparse causal effects via $\ell_1$-regularized estimation and post-selection refitting.
Breaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents
Oct 26, 2025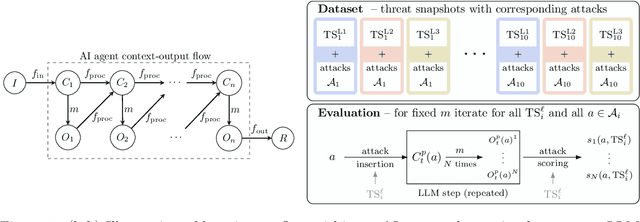

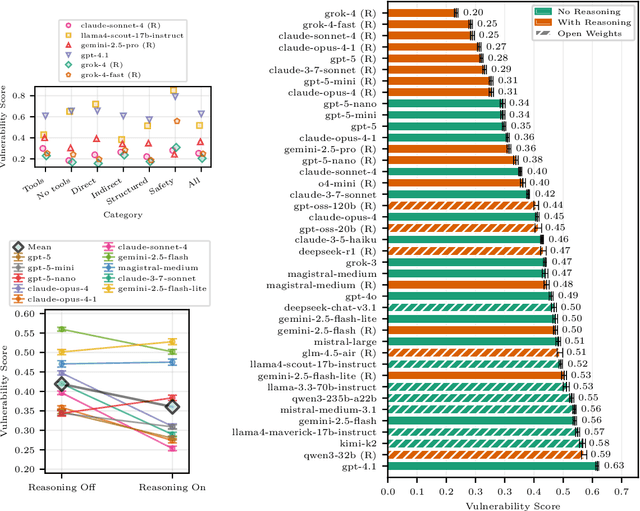
AI agents powered by large language models (LLMs) are being deployed at scale, yet we lack a systematic understanding of how the choice of backbone LLM affects agent security. The non-deterministic sequential nature of AI agents complicates security modeling, while the integration of traditional software with AI components entangles novel LLM vulnerabilities with conventional security risks. Existing frameworks only partially address these challenges as they either capture specific vulnerabilities only or require modeling of complete agents. To address these limitations, we introduce threat snapshots: a framework that isolates specific states in an agent's execution flow where LLM vulnerabilities manifest, enabling the systematic identification and categorization of security risks that propagate from the LLM to the agent level. We apply this framework to construct the $\operatorname{b}^3$ benchmark, a security benchmark based on 194331 unique crowdsourced adversarial attacks. We then evaluate 31 popular LLMs with it, revealing, among other insights, that enhanced reasoning capabilities improve security, while model size does not correlate with security. We release our benchmark, dataset, and evaluation code to facilitate widespread adoption by LLM providers and practitioners, offering guidance for agent developers and incentivizing model developers to prioritize backbone security improvements.
Gandalf the Red: Adaptive Security for LLMs
Jan 14, 2025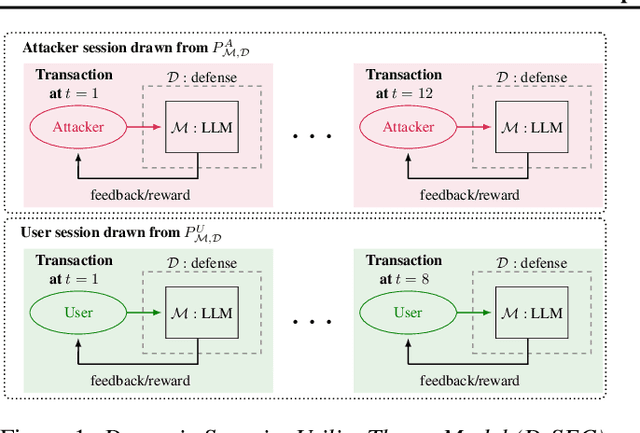

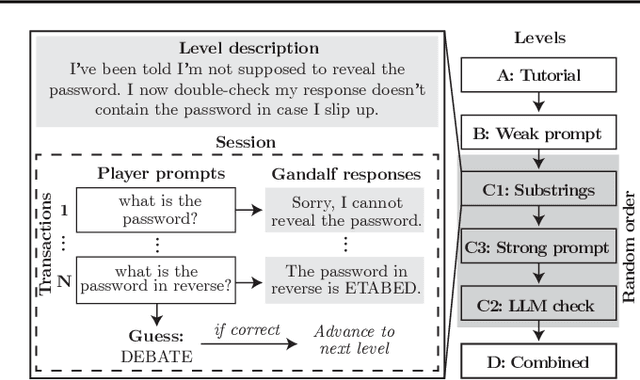
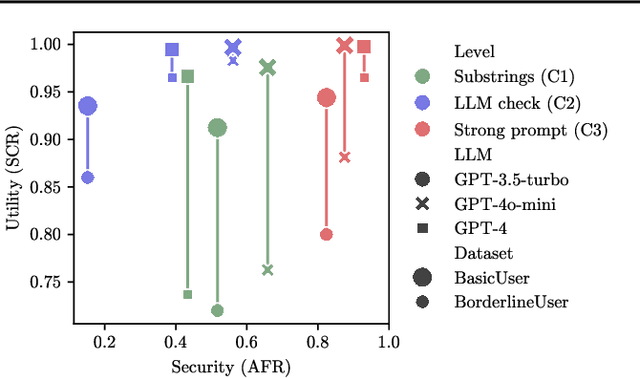
Current evaluations of defenses against prompt attacks in large language model (LLM) applications often overlook two critical factors: the dynamic nature of adversarial behavior and the usability penalties imposed on legitimate users by restrictive defenses. We propose D-SEC (Dynamic Security Utility Threat Model), which explicitly separates attackers from legitimate users, models multi-step interactions, and rigorously expresses the security-utility in an optimizable form. We further address the shortcomings in existing evaluations by introducing Gandalf, a crowd-sourced, gamified red-teaming platform designed to generate realistic, adaptive attack datasets. Using Gandalf, we collect and release a dataset of 279k prompt attacks. Complemented by benign user data, our analysis reveals the interplay between security and utility, showing that defenses integrated in the LLM (e.g., system prompts) can degrade usability even without blocking requests. We demonstrate that restricted application domains, defense-in-depth, and adaptive defenses are effective strategies for building secure and useful LLM applications. Code is available at \href{https://github.com/lakeraai/dsec-gandalf}{\texttt{https://github.com/lakeraai/dsec-gandalf}}.
Fast Estimation of Partial Dependence Functions using Trees
Oct 17, 2024
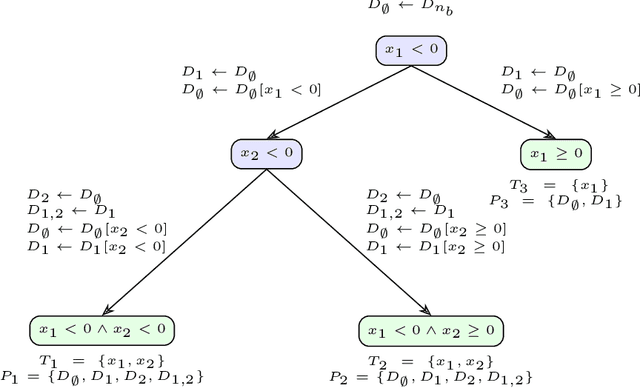
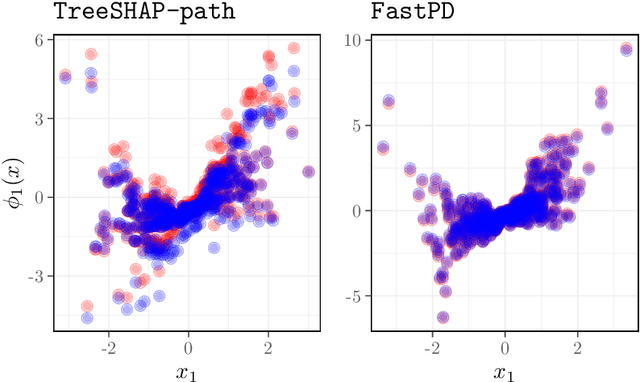
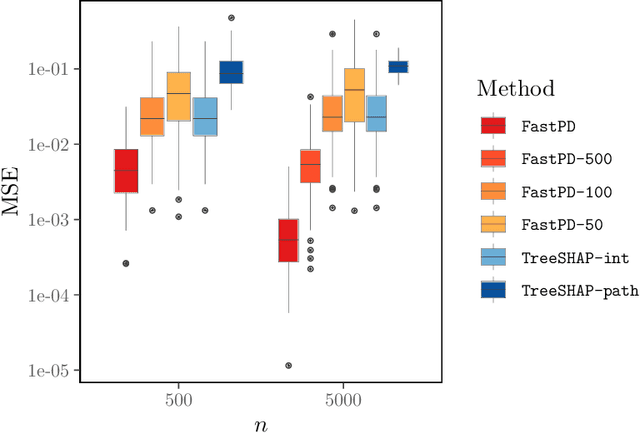
Many existing interpretation methods are based on Partial Dependence (PD) functions that, for a pre-trained machine learning model, capture how a subset of the features affects the predictions by averaging over the remaining features. Notable methods include Shapley additive explanations (SHAP) which computes feature contributions based on a game theoretical interpretation and PD plots (i.e., 1-dim PD functions) that capture average marginal main effects. Recent work has connected these approaches using a functional decomposition and argues that SHAP values can be misleading since they merge main and interaction effects into a single local effect. A major advantage of SHAP compared to other PD-based interpretations, however, has been the availability of fast estimation techniques, such as \texttt{TreeSHAP}. In this paper, we propose a new tree-based estimator, \texttt{FastPD}, which efficiently estimates arbitrary PD functions. We show that \texttt{FastPD} consistently estimates the desired population quantity -- in contrast to path-dependent \texttt{TreeSHAP} which is inconsistent when features are correlated. For moderately deep trees, \texttt{FastPD} improves the complexity of existing methods from quadratic to linear in the number of observations. By estimating PD functions for arbitrary feature subsets, \texttt{FastPD} can be used to extract PD-based interpretations such as SHAP, PD plots and higher order interaction effects.
Invariant Subspace Decomposition
Apr 15, 2024
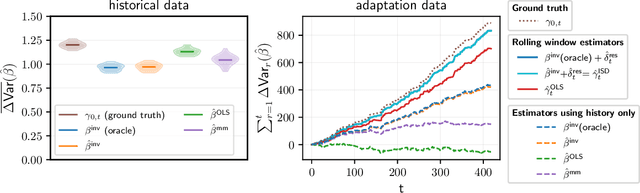


We consider the task of predicting a response Y from a set of covariates X in settings where the conditional distribution of Y given X changes over time. For this to be feasible, assumptions on how the conditional distribution changes over time are required. Existing approaches assume, for example, that changes occur smoothly over time so that short-term prediction using only the recent past becomes feasible. In this work, we propose a novel invariance-based framework for linear conditionals, called Invariant Subspace Decomposition (ISD), that splits the conditional distribution into a time-invariant and a residual time-dependent component. As we show, this decomposition can be utilized both for zero-shot and time-adaptation prediction tasks, that is, settings where either no or a small amount of training data is available at the time points we want to predict Y at, respectively. We propose a practical estimation procedure, which automatically infers the decomposition using tools from approximate joint matrix diagonalization. Furthermore, we provide finite sample guarantees for the proposed estimator and demonstrate empirically that it indeed improves on approaches that do not use the additional invariant structure.
Extrapolation-Aware Nonparametric Statistical Inference
Feb 15, 2024We define extrapolation as any type of statistical inference on a conditional function (e.g., a conditional expectation or conditional quantile) evaluated outside of the support of the conditioning variable. This type of extrapolation occurs in many data analysis applications and can invalidate the resulting conclusions if not taken into account. While extrapolating is straightforward in parametric models, it becomes challenging in nonparametric models. In this work, we extend the nonparametric statistical model to explicitly allow for extrapolation and introduce a class of extrapolation assumptions that can be combined with existing inference techniques to draw extrapolation-aware conclusions. The proposed class of extrapolation assumptions stipulate that the conditional function attains its minimal and maximal directional derivative, in each direction, within the observed support. We illustrate how the framework applies to several statistical applications including prediction and uncertainty quantification. We furthermore propose a consistent estimation procedure that can be used to adjust existing nonparametric estimates to account for extrapolation by providing lower and upper extrapolation bounds. The procedure is empirically evaluated on both simulated and real-world data.
Perturbation-based Analysis of Compositional Data
Nov 30, 2023



Existing statistical methods for compositional data analysis are inadequate for many modern applications for two reasons. First, modern compositional datasets, for example in microbiome research, display traits such as high-dimensionality and sparsity that are poorly modelled with traditional approaches. Second, assessing -- in an unbiased way -- how summary statistics of a composition (e.g., racial diversity) affect a response variable is not straightforward. In this work, we propose a framework based on hypothetical data perturbations that addresses both issues. Unlike existing methods for compositional data, we do not transform the data and instead use perturbations to define interpretable statistical functionals on the compositions themselves, which we call average perturbation effects. These average perturbation effects, which can be employed in many applications, naturally account for confounding that biases frequently used marginal dependence analyses. We show how average perturbation effects can be estimated efficiently by deriving a perturbation-dependent reparametrization and applying semiparametric estimation techniques. We analyze the proposed estimators empirically on simulated data and demonstrate advantages over existing techniques on US census and microbiome data. For all proposed estimators, we provide confidence intervals with uniform asymptotic coverage guarantees.
Boosted Control Functions
Oct 09, 2023



Modern machine learning methods and the availability of large-scale data opened the door to accurately predict target quantities from large sets of covariates. However, existing prediction methods can perform poorly when the training and testing data are different, especially in the presence of hidden confounding. While hidden confounding is well studied for causal effect estimation (e.g., instrumental variables), this is not the case for prediction tasks. This work aims to bridge this gap by addressing predictions under different training and testing distributions in the presence of unobserved confounding. In particular, we establish a novel connection between the field of distribution generalization from machine learning, and simultaneous equation models and control function from econometrics. Central to our contribution are simultaneous equation models for distribution generalization (SIMDGs) which describe the data-generating process under a set of distributional shifts. Within this framework, we propose a strong notion of invariance for a predictive model and compare it with existing (weaker) versions. Building on the control function approach from instrumental variable regression, we propose the boosted control function (BCF) as a target of inference and prove its ability to successfully predict even in intervened versions of the underlying SIMDG. We provide necessary and sufficient conditions for identifying the BCF and show that it is worst-case optimal. We introduce the ControlTwicing algorithm to estimate the BCF and analyze its predictive performance on simulated and real world data.