 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-Dags as Powerful Background Knowledge For Causal Discovery
Dec 10, 2025Finding cause-effect relationships is of key importance in science. Causal discovery aims to recover a graph from data that succinctly describes these cause-effect relationships. However, current methods face several challenges, especially when dealing with high-dimensional data and complex dependencies. Incorporating prior knowledge about the system can aid causal discovery. In this work, we leverage Cluster-DAGs as a prior knowledge framework to warm-start causal discovery. We show that Cluster-DAGs offer greater flexibility than existing approaches based on tiered background knowledge and introduce two modified constraint-based algorithms, Cluster-PC and Cluster-FCI, for causal discovery in the fully and partially observed setting, respectively. Empirical evaluation on simulated data demonstrates that Cluster-PC and Cluster-FCI outperform their respective baselines without prior knowledge.
Identifiability Challenges in Sparse Linear Ordinary Differential Equations
Jun 12, 2025Dynamical systems modeling is a core pillar of scientific inquiry across natural and life sciences. Increasingly, dynamical system models are learned from data, rendering identifiability a paramount concept. For systems that are not identifiable from data, no guarantees can be given about their behavior under new conditions and inputs, or about possible control mechanisms to steer the system. It is known in the community that "linear ordinary differential equations (ODE) are almost surely identifiable from a single trajectory." However, this only holds for dense matrices. The sparse regime remains underexplored, despite its practical relevance with sparsity arising naturally in many biological, social, and physical systems. In this work, we address this gap by characterizing the identifiability of sparse linear ODEs. Contrary to the dense case, we show that sparse systems are unidentifiable with a positive probability in practically relevant sparsity regimes and provide lower bounds for this probability. We further study empirically how this theoretical unidentifiability manifests in state-of-the-art methods to estimate linear ODEs from data. Our results corroborate that sparse systems are also practically unidentifiable. Theoretical limitations are not resolved through inductive biases or optimization dynamics. Our findings call for rethinking what can be expected from data-driven dynamical system modeling and allows for quantitative assessments of how much to trust a learned linear ODE.
An Asymmetric Independence Model for Causal Discovery on Path Spaces
Mar 12, 2025We develop the theory linking 'E-separation' in directed mixed graphs (DMGs) with conditional independence relations among coordinate processes in stochastic differential equations (SDEs), where causal relationships are determined by "which variables enter the governing equation of which other variables". We prove a global Markov property for cyclic SDEs, which naturally extends to partially observed cyclic SDEs, because our asymmetric independence model is closed under marginalization. We then characterize the class of graphs that encode the same set of independence relations, yielding a result analogous to the seminal 'same skeleton and v-structures' result for directed acyclic graphs (DAGs). In the fully observed case, we show that each such equivalence class of graphs has a greatest element as a parsimonious representation and develop algorithms to identify this greatest element from data. We conjecture that a greatest element also exists under partial observations, which we verify computationally for graphs with up to four nodes.
Your Assumed DAG is Wrong and Here's How To Deal With It
Feb 24, 2025Assuming a directed acyclic graph (DAG) that represents prior knowledge of causal relationships between variables is a common starting point for cause-effect estimation. Existing literature typically invokes hypothetical domain expert knowledge or causal discovery algorithms to justify this assumption. In practice, neither may propose a single DAG with high confidence. Domain experts are hesitant to rule out dependencies with certainty or have ongoing disputes about relationships; causal discovery often relies on untestable assumptions itself or only provides an equivalence class of DAGs and is commonly sensitive to hyperparameter and threshold choices. We propose an efficient, gradient-based optimization method that provides bounds for causal queries over a collection of causal graphs -- compatible with imperfect prior knowledge -- that may still be too large for exhaustive enumeration. Our bounds achieve good coverage and sharpness for causal queries such as average treatment effects in linear and non-linear synthetic settings as well as on real-world data. Our approach aims at providing an easy-to-use and widely applicable rebuttal to the valid critique of `What if your assumed DAG is wrong?'.
Generative Intervention Models for Causal Perturbation Modeling
Nov 21, 2024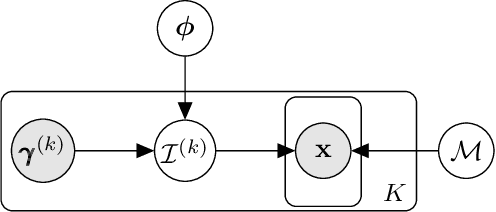
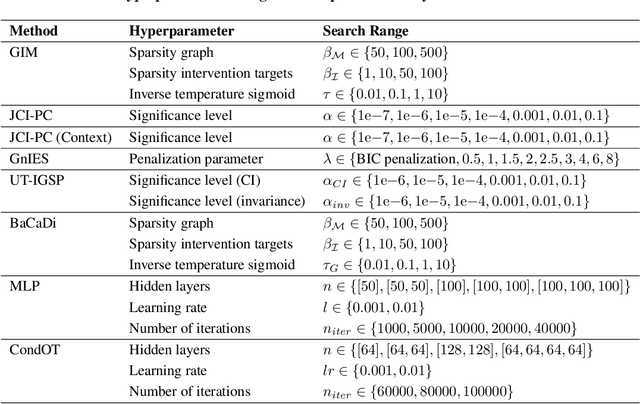
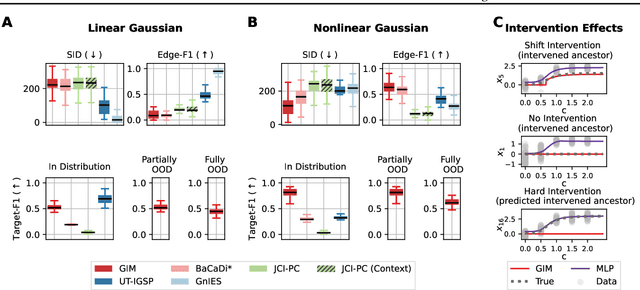

We consider the problem of predicting perturbation effects via causal models. In many applications, it is a priori unknown which mechanisms of a system are modified by an external perturbation, even though the features of the perturbation are available. For example, in genomics, some properties of a drug may be known, but not their causal effects on the regulatory pathways of cells. We propose a generative intervention model (GIM) that learns to map these perturbation features to distributions over atomic interventions in a jointly-estimated causal model. Contrary to prior approaches, this enables us to predict the distribution shifts of unseen perturbation features while gaining insights about their mechanistic effects in the underlying data-generating process. On synthetic data and scRNA-seq drug perturbation data, GIMs achieve robust out-of-distribution predictions on par with unstructured approaches, while effectively inferring the underlying perturbation mechanisms, often better than other causal inference methods.
Projected Neural Differential Equations for Learning Constrained Dynamics
Oct 31, 2024



Neural differential equations offer a powerful approach for learning dynamics from data. However, they do not impose known constraints that should be obeyed by the learned model. It is well-known that enforcing constraints in surrogate models can enhance their generalizability and numerical stability. In this paper, we introduce projected neural differential equations (PNDEs), a new method for constraining neural differential equations based on projection of the learned vector field to the tangent space of the constraint manifold. In tests on several challenging examples, including chaotic dynamical systems and state-of-the-art power grid models, PNDEs outperform existing methods while requiring fewer hyperparameters. The proposed approach demonstrates significant potential for enhancing the modeling of constrained dynamical systems, particularly in complex domains where accuracy and reliability are essential.
Causal machine learning for predicting treatment outcomes
Oct 11, 2024Causal machine learning (ML) offers flexible, data-driven methods for predicting treatment outcomes including efficacy and toxicity, thereby supporting the assessment and safety of drugs. A key benefit of causal ML is that it allows for estimating individualized treatment effects, so that clinical decision-making can be personalized to individual patient profiles. Causal ML can be used in combination with both clinical trial data and real-world data, such as clinical registries and electronic health records, but caution is needed to avoid biased or incorrect predictions. In this Perspective, we discuss the benefits of causal ML (relative to traditional statistical or ML approaches) and outline the key components and steps. Finally, we provide recommendations for the reliable use of causal ML and effective translation into the clinic.
* Accepted version; not Version of Record
Learning Representations of Instruments for Partial Identification of Treatment Effects
Oct 11, 2024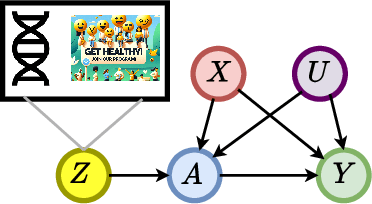
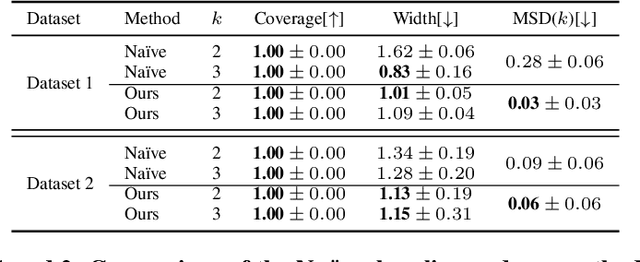
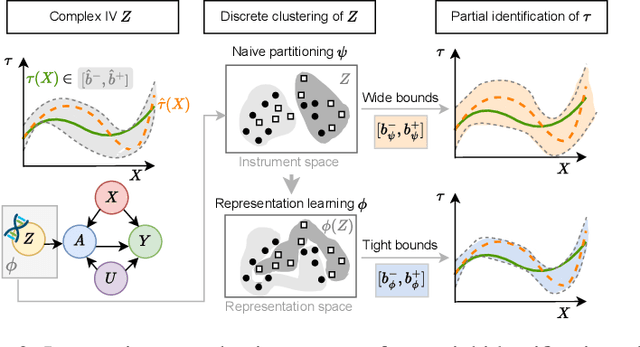
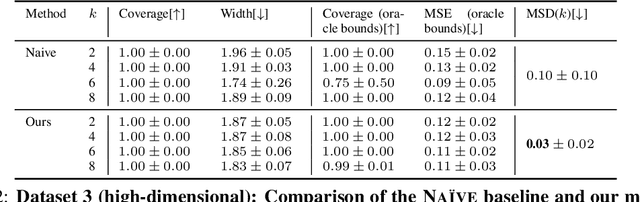
Reliable estimation of treatment effects from observational data is important in many disciplines such as medicine. However, estimation is challenging when unconfoundedness as a standard assumption in the causal inference literature is violated. In this work, we leverage arbitrary (potentially high-dimensional) instruments to estimate bounds on the conditional average treatment effect (CATE). Our contributions are three-fold: (1) We propose a novel approach for partial identification through a mapping of instruments to a discrete representation space so that we yield valid bounds on the CATE. This is crucial for reliable decision-making in real-world applications. (2) We derive a two-step procedure that learns tight bounds using a tailored neural partitioning of the latent instrument space. As a result, we avoid instability issues due to numerical approximations or adversarial training. Furthermore, our procedure aims to reduce the estimation variance in finite-sample settings to yield more reliable estimates. (3) We show theoretically that our procedure obtains valid bounds while reducing estimation variance. We further perform extensive experiments to demonstrate the effectiveness across various settings. Overall, our procedure offers a novel path for practitioners to make use of potentially high-dimensional instruments (e.g., as in Mendelian randomization).
Uncertainty-Aware Optimal Treatment Selection for Clinical Time Series
Oct 11, 2024In personalized medicine, the ability to predict and optimize treatment outcomes across various time frames is essential. Additionally, the ability to select cost-effective treatments within specific budget constraints is critical. Despite recent advancements in estimating counterfactual trajectories, a direct link to optimal treatment selection based on these estimates is missing. This paper introduces a novel method integrating counterfactual estimation techniques and uncertainty quantification to recommend personalized treatment plans adhering to predefined cost constraints. Our approach is distinctive in its handling of continuous treatment variables and its incorporation of uncertainty quantification to improve prediction reliability. We validate our method using two simulated datasets, one focused on the cardiovascular system and the other on COVID-19. Our findings indicate that our method has robust performance across different counterfactual estimation baselines, showing that introducing uncertainty quantification in these settings helps the current baselines in finding more reliable and accurate treatment selection. The robustness of our method across various settings highlights its potential for broad applicability in personalized healthcare solutions.
Towards Physically Consistent Deep Learning For Climate Model Parameterizations
Jun 06, 2024Climate models play a critical role in understanding and projecting climate change. Due to their complexity, their horizontal resolution of ~40-100 km remains too coarse to resolve processes such as clouds and convection, which need to be approximated via parameterizations. These parameterizations are a major source of systematic errors and large uncertainties in climate projections. Deep learning (DL)-based parameterizations, trained on computationally expensive, short high-resolution simulations, have shown great promise for improving climate models in that regard. However, their lack of interpretability and tendency to learn spurious non-physical correlations result in reduced trust in the climate simulation. We propose an efficient supervised learning framework for DL-based parameterizations that leads to physically consistent models with improved interpretability and negligible computational overhead compared to standard supervised training. First, key features determining the target physical processes are uncovered. Subsequently, the neural network is fine-tuned using only those relevant features. We show empirically that our method robustly identifies a small subset of the inputs as actual physical drivers, therefore, removing spurious non-physical relationships. This results in by design physically consistent and interpretable neural networks while maintaining the predictive performance of standard black-box DL-based parameterizations. Our framework represents a crucial step in addressing a major challenge in data-driven climate model parameterizations by respecting the underlying physical processes, and may also benefit physically consistent deep learning in other research fields.