 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany Experiments, Few Repetitions, Unpaired Data, and Sparse Effects: Is Causal Inference Possible?
Jan 21, 2026We study the problem of estimating causal effects under hidden confounding in the following unpaired data setting: we observe some covariates $X$ and an outcome $Y$ under different experimental conditions (environments) but do not observe them jointly; we either observe $X$ or $Y$. Under appropriate regularity conditions, the problem can be cast as an instrumental variable (IV) regression with the environment acting as a (possibly high-dimensional) instrument. When there are many environments but only a few observations per environment, standard two-sample IV estimators fail to be consistent. We propose a GMM-type estimator based on cross-fold sample splitting of the instrument-covariate sample and prove that it is consistent as the number of environments grows but the sample size per environment remains constant. We further extend the method to sparse causal effects via $\ell_1$-regularized estimation and post-selection refitting.
Maximum Risk Minimization with Random Forests
Dec 11, 2025We consider a regression setting where observations are collected in different environments modeled by different data distributions. The field of out-of-distribution (OOD) generalization aims to design methods that generalize better to test environments whose distributions differ from those observed during training. One line of such works has proposed to minimize the maximum risk across environments, a principle that we refer to as MaxRM (Maximum Risk Minimization). In this work, we introduce variants of random forests based on the principle of MaxRM. We provide computationally efficient algorithms and prove statistical consistency for our primary method. Our proposed method can be used with each of the following three risks: the mean squared error, the negative reward (which relates to the explained variance), and the regret (which quantifies the excess risk relative to the best predictor). For MaxRM with regret as the risk, we prove a novel out-of-sample guarantee over unseen test distributions. Finally, we evaluate the proposed methods on both simulated and real-world data.
Transferring Causal Effects using Proxies
Oct 29, 2025We consider the problem of estimating a causal effect in a multi-domain setting. The causal effect of interest is confounded by an unobserved confounder and can change between the different domains. We assume that we have access to a proxy of the hidden confounder and that all variables are discrete or categorical. We propose methodology to estimate the causal effect in the target domain, where we assume to observe only the proxy variable. Under these conditions, we prove identifiability (even when treatment and response variables are continuous). We introduce two estimation techniques, prove consistency, and derive confidence intervals. The theoretical results are supported by simulation studies and a real-world example studying the causal effect of website rankings on consumer choices.
Representation Learning for Distributional Perturbation Extrapolation
Apr 25, 2025We consider the problem of modelling the effects of unseen perturbations such as gene knockdowns or drug combinations on low-level measurements such as RNA sequencing data. Specifically, given data collected under some perturbations, we aim to predict the distribution of measurements for new perturbations. To address this challenging extrapolation task, we posit that perturbations act additively in a suitable, unknown embedding space. More precisely, we formulate the generative process underlying the observed data as a latent variable model, in which perturbations amount to mean shifts in latent space and can be combined additively. Unlike previous work, we prove that, given sufficiently diverse training perturbations, the representation and perturbation effects are identifiable up to affine transformation, and use this to characterize the class of unseen perturbations for which we obtain extrapolation guarantees. To estimate the model from data, we propose a new method, the perturbation distribution autoencoder (PDAE), which is trained by maximising the distributional similarity between true and predicted perturbation distributions. The trained model can then be used to predict previously unseen perturbation distributions. Empirical evidence suggests that PDAE compares favourably to existing methods and baselines at predicting the effects of unseen perturbations.
DecoR: Deconfounding Time Series with Robust Regression
Jun 11, 2024



Causal inference on time series data is a challenging problem, especially in the presence of unobserved confounders. This work focuses on estimating the causal effect between two time series, which are confounded by a third, unobserved time series. Assuming spectral sparsity of the confounder, we show how in the frequency domain this problem can be framed as an adversarial outlier problem. We introduce Deconfounding by Robust regression (DecoR), a novel approach that estimates the causal effect using robust linear regression in the frequency domain. Considering two different robust regression techniques, we first improve existing bounds on the estimation error for such techniques. Crucially, our results do not require distributional assumptions on the covariates. We can therefore use them in time series settings. Applying these results to DecoR, we prove, under suitable assumptions, upper bounds for the estimation error of DecoR that imply consistency. We show DecoR's effectiveness through experiments on synthetic data. Our experiments furthermore suggest that our method is robust with respect to model misspecification.
The Causal Chambers: Real Physical Systems as a Testbed for AI Methodology
Apr 17, 2024

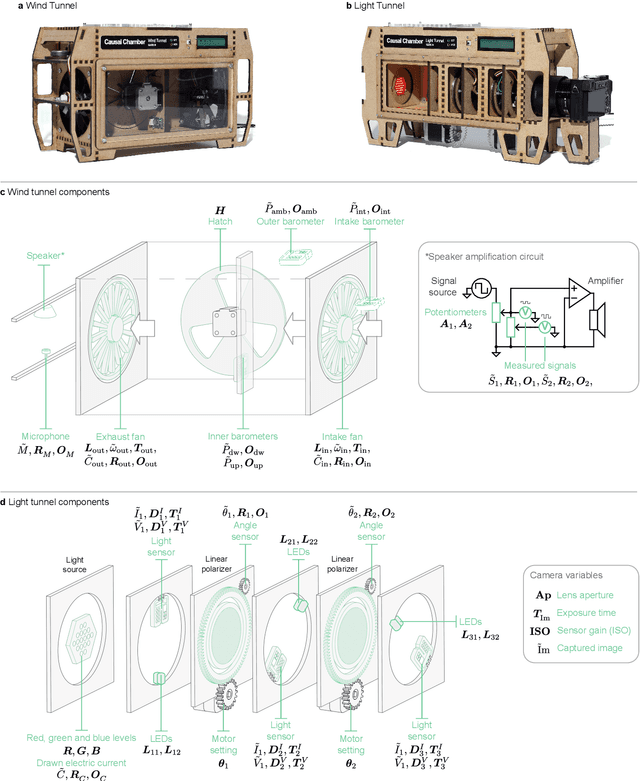
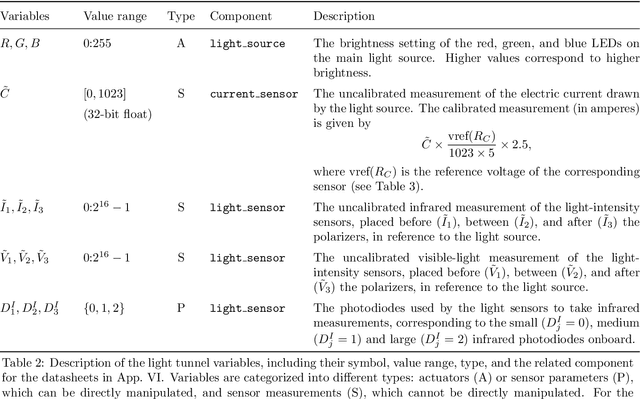
In some fields of AI, machine learning and statistics, the validation of new methods and algorithms is often hindered by the scarcity of suitable real-world datasets. Researchers must often turn to simulated data, which yields limited information about the applicability of the proposed methods to real problems. As a step forward, we have constructed two devices that allow us to quickly and inexpensively produce large datasets from non-trivial but well-understood physical systems. The devices, which we call causal chambers, are computer-controlled laboratories that allow us to manipulate and measure an array of variables from these physical systems, providing a rich testbed for algorithms from a variety of fields. We illustrate potential applications through a series of case studies in fields such as causal discovery, out-of-distribution generalization, change point detection, independent component analysis, and symbolic regression. For applications to causal inference, the chambers allow us to carefully perform interventions. We also provide and empirically validate a causal model of each chamber, which can be used as ground truth for different tasks. All hardware and software is made open source, and the datasets are publicly available at causalchamber.org or through the Python package causalchamber.
Invariant Subspace Decomposition
Apr 15, 2024We consider the task of predicting a response Y from a set of covariates X in settings where the conditional distribution of Y given X changes over time. For this to be feasible, assumptions on how the conditional distribution changes over time are required. Existing approaches assume, for example, that changes occur smoothly over time so that short-term prediction using only the recent past becomes feasible. In this work, we propose a novel invariance-based framework for linear conditionals, called Invariant Subspace Decomposition (ISD), that splits the conditional distribution into a time-invariant and a residual time-dependent component. As we show, this decomposition can be utilized both for zero-shot and time-adaptation prediction tasks, that is, settings where either no or a small amount of training data is available at the time points we want to predict Y at, respectively. We propose a practical estimation procedure, which automatically infers the decomposition using tools from approximate joint matrix diagonalization. Furthermore, we provide finite sample guarantees for the proposed estimator and demonstrate empirically that it indeed improves on approaches that do not use the additional invariant structure.
Boosted Control Functions
Oct 09, 2023



Modern machine learning methods and the availability of large-scale data opened the door to accurately predict target quantities from large sets of covariates. However, existing prediction methods can perform poorly when the training and testing data are different, especially in the presence of hidden confounding. While hidden confounding is well studied for causal effect estimation (e.g., instrumental variables), this is not the case for prediction tasks. This work aims to bridge this gap by addressing predictions under different training and testing distributions in the presence of unobserved confounding. In particular, we establish a novel connection between the field of distribution generalization from machine learning, and simultaneous equation models and control function from econometrics. Central to our contribution are simultaneous equation models for distribution generalization (SIMDGs) which describe the data-generating process under a set of distributional shifts. Within this framework, we propose a strong notion of invariance for a predictive model and compare it with existing (weaker) versions. Building on the control function approach from instrumental variable regression, we propose the boosted control function (BCF) as a target of inference and prove its ability to successfully predict even in intervened versions of the underlying SIMDG. We provide necessary and sufficient conditions for identifying the BCF and show that it is worst-case optimal. We introduce the ControlTwicing algorithm to estimate the BCF and analyze its predictive performance on simulated and real world data.
Identifying Representations for Intervention Extrapolation
Oct 06, 2023



The premise of identifiable and causal representation learning is to improve the current representation learning paradigm in terms of generalizability or robustness. Despite recent progress in questions of identifiability, more theoretical results demonstrating concrete advantages of these methods for downstream tasks are needed. In this paper, we consider the task of intervention extrapolation: predicting how interventions affect an outcome, even when those interventions are not observed at training time, and show that identifiable representations can provide an effective solution to this task even if the interventions affect the outcome non-linearly. Our setup includes an outcome Y, observed features X, which are generated as a non-linear transformation of latent features Z, and exogenous action variables A, which influence Z. The objective of intervention extrapolation is to predict how interventions on A that lie outside the training support of A affect Y. Here, extrapolation becomes possible if the effect of A on Z is linear and the residual when regressing Z on A has full support. As Z is latent, we combine the task of intervention extrapolation with identifiable representation learning, which we call Rep4Ex: we aim to map the observed features X into a subspace that allows for non-linear extrapolation in A. We show using Wiener's Tauberian theorem that the hidden representation is identifiable up to an affine transformation in Z-space, which is sufficient for intervention extrapolation. The identifiability is characterized by a novel constraint describing the linearity assumption of A on Z. Based on this insight, we propose a method that enforces the linear invariance constraint and can be combined with any type of autoencoder. We validate our theoretical findings through synthetic experiments and show that our approach succeeds in predicting the effects of unseen interventions.
Model-based causal feature selection for general response types
Sep 22, 2023Discovering causal relationships from observational data is a fundamental yet challenging task. In some applications, it may suffice to learn the causal features of a given response variable, instead of learning the entire underlying causal structure. Invariant causal prediction (ICP, Peters et al., 2016) is a method for causal feature selection which requires data from heterogeneous settings. ICP assumes that the mechanism for generating the response from its direct causes is the same in all settings and exploits this invariance to output a subset of the causal features. The framework of ICP has been extended to general additive noise models and to nonparametric settings using conditional independence testing. However, nonparametric conditional independence testing often suffers from low power (or poor type I error control) and the aforementioned parametric models are not suitable for applications in which the response is not measured on a continuous scale, but rather reflects categories or counts. To bridge this gap, we develop ICP in the context of transformation models (TRAMs), allowing for continuous, categorical, count-type, and uninformatively censored responses (we show that, in general, these model classes do not allow for identifiability when there is no exogenous heterogeneity). We propose TRAM-GCM, a test for invariance of a subset of covariates, based on the expected conditional covariance between environments and score residuals which satisfies uniform asymptotic level guarantees. For the special case of linear shift TRAMs, we propose an additional invariance test, TRAM-Wald, based on the Wald statistic. We implement both proposed methods in the open-source R package "tramicp" and show in simulations that under the correct model specification, our approach empirically yields higher power than nonparametric ICP based on conditional independence testing.