 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Measuring in Reinforcement Learning With Delayed Negative Effects
Oct 16, 2025Measuring states in reinforcement learning (RL) can be costly in real-world settings and may negatively influence future outcomes. We introduce the Actively Observable Markov Decision Process (AOMDP), where an agent not only selects control actions but also decides whether to measure the latent state. The measurement action reveals the true latent state but may have a negative delayed effect on the environment. We show that this reduced uncertainty may provably improve sample efficiency and increase the value of the optimal policy despite these costs. We formulate an AOMDP as a periodic partially observable MDP and propose an online RL algorithm based on belief states. To approximate the belief states, we further propose a sequential Monte Carlo method to jointly approximate the posterior of unknown static environment parameters and unobserved latent states. We evaluate the proposed algorithm in a digital health application, where the agent decides when to deliver digital interventions and when to assess users' health status through surveys.
Harnessing Causality in Reinforcement Learning With Bagged Decision Times
Oct 18, 2024



We consider reinforcement learning (RL) for a class of problems with bagged decision times. A bag contains a finite sequence of consecutive decision times. The transition dynamics are non-Markovian and non-stationary within a bag. Further, all actions within a bag jointly impact a single reward, observed at the end of the bag. Our goal is to construct an online RL algorithm to maximize the discounted sum of the bag-specific rewards. To handle non-Markovian transitions within a bag, we utilize an expert-provided causal directed acyclic graph (DAG). Based on the DAG, we construct the states as a dynamical Bayesian sufficient statistic of the observed history, which results in Markovian state transitions within and across bags. We then frame this problem as a periodic Markov decision process (MDP) that allows non-stationarity within a period. An online RL algorithm based on Bellman-equations for stationary MDPs is generalized to handle periodic MDPs. To justify the proposed RL algorithm, we show that our constructed state achieves the maximal optimal value function among all state constructions for a periodic MDP. Further we prove the Bellman optimality equations for periodic MDPs. We evaluate the proposed method on testbed variants, constructed with real data from a mobile health clinical trial.
AI-Assisted Causal Pathway Diagram for Human-Centered Design
Mar 12, 2024



This paper explores the integration of causal pathway diagrams (CPD) into human-centered design (HCD), investigating how these diagrams can enhance the early stages of the design process. A dedicated CPD plugin for the online collaborative whiteboard platform Miro was developed to streamline diagram creation and offer real-time AI-driven guidance. Through a user study with designers (N=20), we found that CPD's branching and its emphasis on causal connections supported both divergent and convergent processes during design. CPD can also facilitate communication among stakeholders. Additionally, we found our plugin significantly reduces designers' cognitive workload and increases their creativity during brainstorming, highlighting the implications of AI-assisted tools in supporting creative work and evidence-based designs.
Effect-Invariant Mechanisms for Policy Generalization
Jun 27, 2023Policy learning is an important component of many real-world learning systems. A major challenge in policy learning is how to adapt efficiently to unseen environments or tasks. Recently, it has been suggested to exploit invariant conditional distributions to learn models that generalize better to unseen environments. However, assuming invariance of entire conditional distributions (which we call full invariance) may be too strong of an assumption in practice. In this paper, we introduce a relaxation of full invariance called effect-invariance (e-invariance for short) and prove that it is sufficient, under suitable assumptions, for zero-shot policy generalization. We also discuss an extension that exploits e-invariance when we have a small sample from the test environment, enabling few-shot policy generalization. Our work does not assume an underlying causal graph or that the data are generated by a structural causal model; instead, we develop testing procedures to test e-invariance directly from data. We present empirical results using simulated data and a mobile health intervention dataset to demonstrate the effectiveness of our approach.
Assessing the Impact of Context Inference Error and Partial Observability on RL Methods for Just-In-Time Adaptive Interventions
May 17, 2023Just-in-Time Adaptive Interventions (JITAIs) are a class of personalized health interventions developed within the behavioral science community. JITAIs aim to provide the right type and amount of support by iteratively selecting a sequence of intervention options from a pre-defined set of components in response to each individual's time varying state. In this work, we explore the application of reinforcement learning methods to the problem of learning intervention option selection policies. We study the effect of context inference error and partial observability on the ability to learn effective policies. Our results show that the propagation of uncertainty from context inferences is critical to improving intervention efficacy as context uncertainty increases, while policy gradient algorithms can provide remarkable robustness to partially observed behavioral state information.
Did we personalize? Assessing personalization by an online reinforcement learning algorithm using resampling
Apr 24, 2023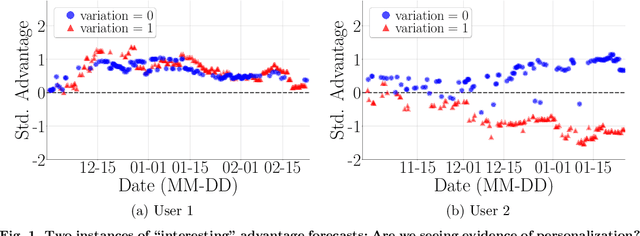
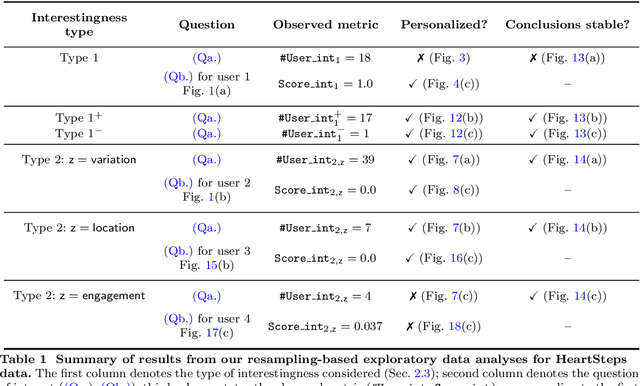
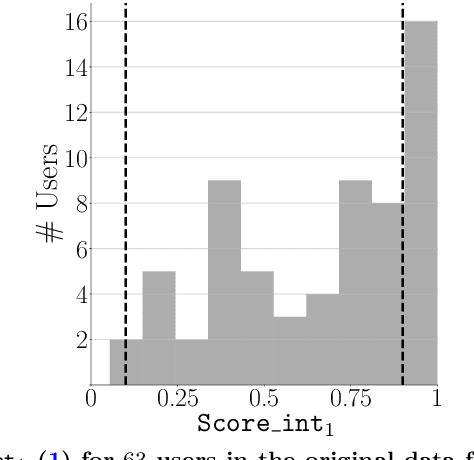
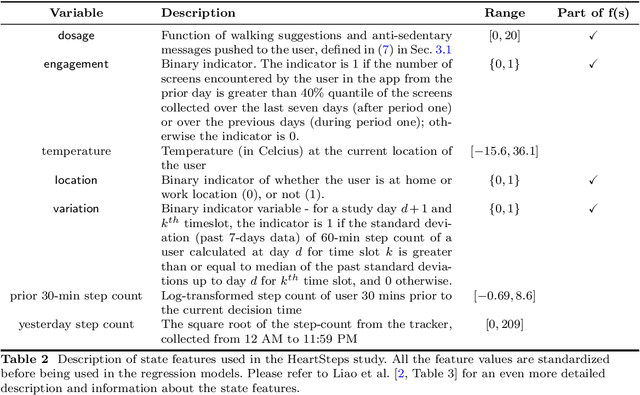
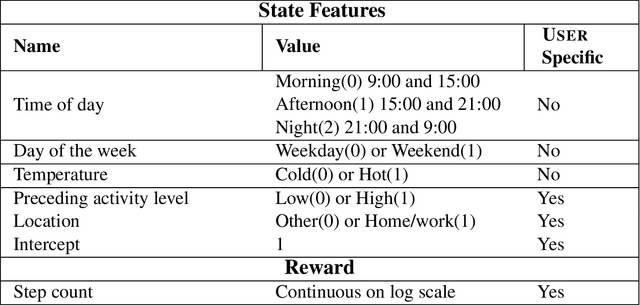
There is a growing interest in using reinforcement learning (RL) to personalize sequences of treatments in digital health to support users in adopting healthier behaviors. Such sequential decision-making problems involve decisions about when to treat and how to treat based on the user's context (e.g., prior activity level, location, etc.). Online RL is a promising data-driven approach for this problem as it learns based on each user's historical responses and uses that knowledge to personalize these decisions. However, to decide whether the RL algorithm should be included in an ``optimized'' intervention for real-world deployment, we must assess the data evidence indicating that the RL algorithm is actually personalizing the treatments to its users. Due to the stochasticity in the RL algorithm, one may get a false impression that it is learning in certain states and using this learning to provide specific treatments. We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity. We illustrate our methodology with a case study by analyzing the data from a physical activity clinical trial called HeartSteps, which included the use of an online RL algorithm. We demonstrate how our approach enhances data-driven truth-in-advertising of algorithm personalization both across all users as well as within specific users in the study.
Doubly robust nearest neighbors in factor models
Nov 28, 2022In this technical note, we introduce an improved variant of nearest neighbors for counterfactual inference in panel data settings where multiple units are assigned multiple treatments over multiple time points, each sampled with constant probabilities. We call this estimator a doubly robust nearest neighbor estimator and provide a high probability non-asymptotic error bound for the mean parameter corresponding to each unit at each time. Our guarantee shows that the doubly robust estimator provides a (near-)quadratic improvement in the error compared to nearest neighbor estimators analyzed in prior work for these settings.
IntelligentPooling: Practical Thompson Sampling for mHealth
Jul 31, 2020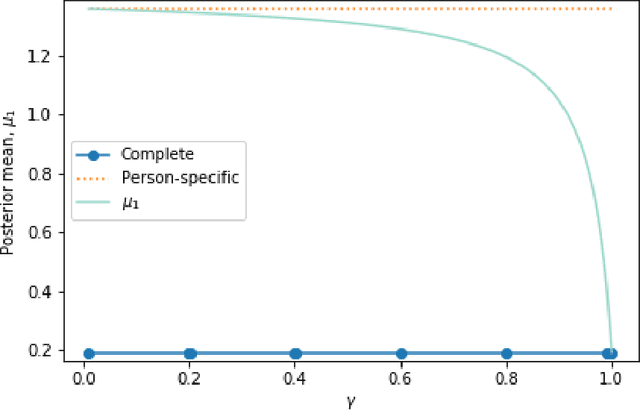

In mobile health (mHealth) smart devices deliver behavioral treatments repeatedly over time to a user with the goal of helping the user adopt and maintain healthy behaviors. Reinforcement learning appears ideal for learning how to optimally make these sequential treatment decisions. However, significant challenges must be overcome before reinforcement learning can be effectively deployed in a mobile healthcare setting. In this work we are concerned with the following challenges: 1) individuals who are in the same context can exhibit differential response to treatments 2) only a limited amount of data is available for learning on any one individual, and 3) non-stationary responses to treatment. To address these challenges we generalize Thompson-Sampling bandit algorithms to develop IntelligentPooling. IntelligentPooling learns personalized treatment policies thus addressing challenge one. To address the second challenge, IntelligentPooling updates each user's degree of personalization while making use of available data on other users to speed up learning. Lastly, IntelligentPooling allows responsivity to vary as a function of a user's time since beginning treatment, thus addressing challenge three. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art. We demonstrate the promise of this approach and its ability to learn from even a small group of users in a live clinical trial.
Rapidly Personalizing Mobile Health Treatment Policies with Limited Data
Feb 23, 2020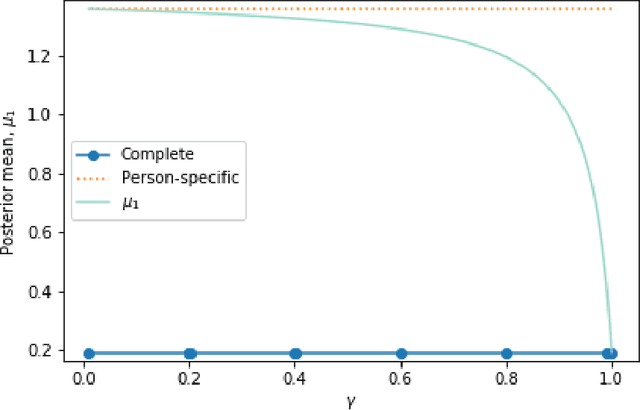
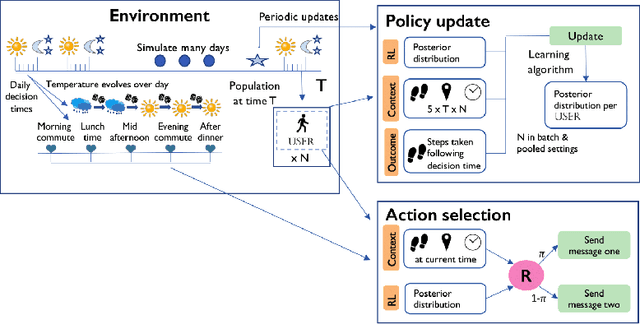

In mobile health (mHealth), reinforcement learning algorithms that adapt to one's context without learning personalized policies might fail to distinguish between the needs of individuals. Yet the high amount of noise due to the in situ delivery of mHealth interventions can cripple the ability of an algorithm to learn when given access to only a single user's data, making personalization challenging. We present IntelligentPooling, which learns personalized policies via an adaptive, principled use of other users' data. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art across all generative models. Additionally, we inspect the behavior of this approach in a live clinical trial, demonstrating its ability to learn from even a small group of users.
Off-Policy Estimation of Long-Term Average Outcomes with Applications to Mobile Health
Dec 30, 2019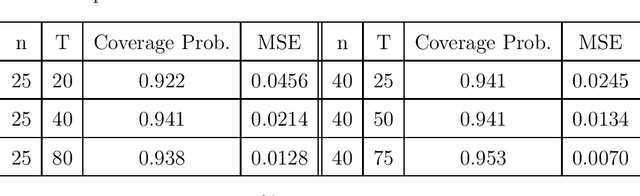
With the recent advancements in wearables and sensing technology, health scientists are increasingly developing mobile health (mHealth) interventions. In mHealth interventions, mobile devices are used to deliver treatment to individuals as they go about their daily lives, generally designed to impact a near time, proximal outcome such as stress or physical activity. The mHealth intervention policies, often called Just-In-time Adaptive Interventions, are decision rules that map a user's context to a particular treatment at each of many time points. The vast majority of current mHealth interventions deploy expert-derived policies. In this paper, we provide an approach for conducting inference about the performance of one or more such policies. In particular, we estimate the performance of a mHealth policy using historical data that are collected under a possibly different policy. Our measure of performance is the average of proximal outcomes (rewards) over a long time period should the particular mHealth policy be followed. We provide a semi-parametric efficient estimator as well as the confidence intervals. This work is motivated by HeartSteps, a mobile health physical activity intervention.