 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapidly Personalizing Mobile Health Treatment Policies with Limited Data
Paper and Code
Feb 23, 2020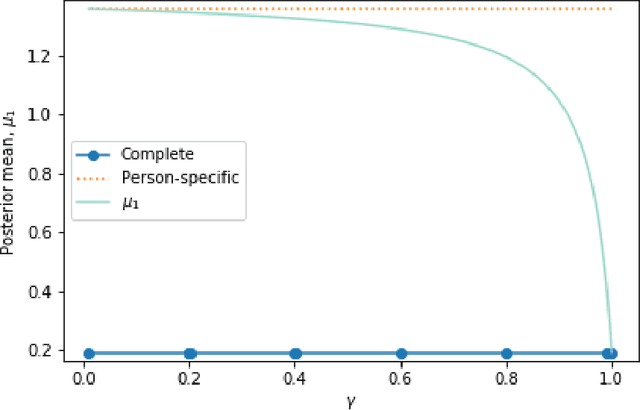
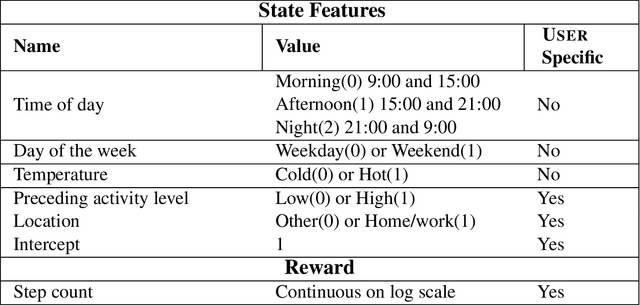
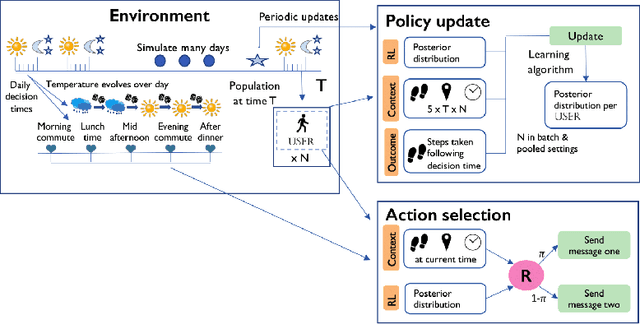

In mobile health (mHealth), reinforcement learning algorithms that adapt to one's context without learning personalized policies might fail to distinguish between the needs of individuals. Yet the high amount of noise due to the in situ delivery of mHealth interventions can cripple the ability of an algorithm to learn when given access to only a single user's data, making personalization challenging. We present IntelligentPooling, which learns personalized policies via an adaptive, principled use of other users' data. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art across all generative models. Additionally, we inspect the behavior of this approach in a live clinical trial, demonstrating its ability to learn from even a small group of users.