 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaEmbed: Semi-supervised Domain Adaptation in the Embedding Space
Jan 23, 2024Semi-supervised domain adaptation (SSDA) presents a critical hurdle in computer vision, especially given the frequent scarcity of labeled data in real-world settings. This scarcity often causes foundation models, trained on extensive datasets, to underperform when applied to new domains. AdaEmbed, our newly proposed methodology for SSDA, offers a promising solution to these challenges. Leveraging the potential of unlabeled data, AdaEmbed facilitates the transfer of knowledge from a labeled source domain to an unlabeled target domain by learning a shared embedding space. By generating accurate and uniform pseudo-labels based on the established embedding space, the model overcomes the limitations of conventional SSDA, thus enhancing performance significantly. Our method's effectiveness is validated through extensive experiments on benchmark datasets such as DomainNet, Office-Home, and VisDA-C, where AdaEmbed consistently outperforms all the baselines, setting a new state of the art for SSDA. With its straightforward implementation and high data efficiency, AdaEmbed stands out as a robust and pragmatic solution for real-world scenarios, where labeled data is scarce. To foster further research and application in this area, we are sharing the codebase of our unified framework for semi-supervised domain adaptation.
Open World Object Detection in the Era of Foundation Models
Dec 10, 2023Object detection is integral to a bevy of real-world applications, from robotics to medical image analysis. To be used reliably in such applications, models must be capable of handling unexpected - or novel - objects. The open world object detection (OWD) paradigm addresses this challenge by enabling models to detect unknown objects and learn discovered ones incrementally. However, OWD method development is hindered due to the stringent benchmark and task definitions. These definitions effectively prohibit foundation models. Here, we aim to relax these definitions and investigate the utilization of pre-trained foundation models in OWD. First, we show that existing benchmarks are insufficient in evaluating methods that utilize foundation models, as even naive integration methods nearly saturate these benchmarks. This result motivated us to curate a new and challenging benchmark for these models. Therefore, we introduce a new benchmark that includes five real-world application-driven datasets, including challenging domains such as aerial and surgical images, and establish baselines. We exploit the inherent connection between classes in application-driven datasets and introduce a novel method, Foundation Object detection Model for the Open world, or FOMO, which identifies unknown objects based on their shared attributes with the base known objects. FOMO has ~3x unknown object mAP compared to baselines on our benchmark. However, our results indicate a significant place for improvement - suggesting a great research opportunity in further scaling object detection methods to real-world domains. Our code and benchmark are available at https://orrzohar.github.io/projects/fomo/.
INSPECT: A Multimodal Dataset for Pulmonary Embolism Diagnosis and Prognosis
Nov 17, 2023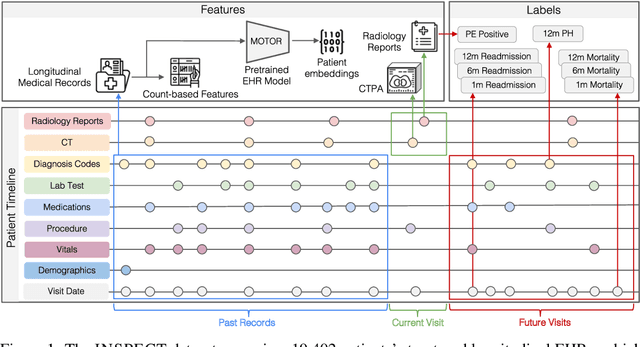
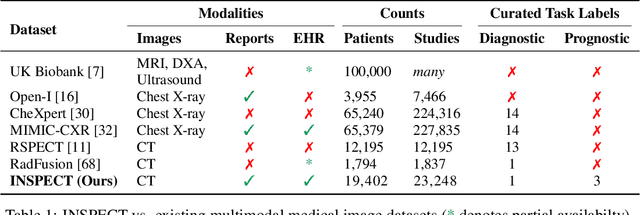
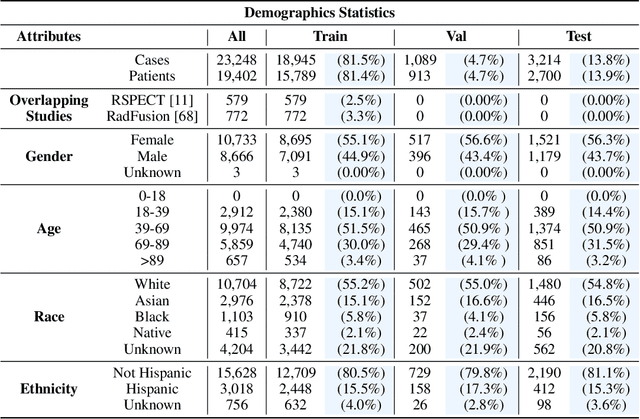
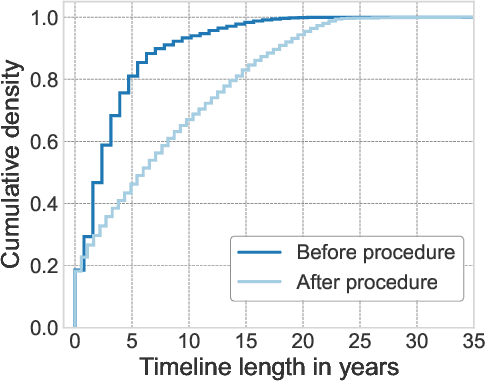
Synthesizing information from multiple data sources plays a crucial role in the practice of modern medicine. Current applications of artificial intelligence in medicine often focus on single-modality data due to a lack of publicly available, multimodal medical datasets. To address this limitation, we introduce INSPECT, which contains de-identified longitudinal records from a large cohort of patients at risk for pulmonary embolism (PE), along with ground truth labels for multiple outcomes. INSPECT contains data from 19,402 patients, including CT images, radiology report impression sections, and structured electronic health record (EHR) data (i.e. demographics, diagnoses, procedures, vitals, and medications). Using INSPECT, we develop and release a benchmark for evaluating several baseline modeling approaches on a variety of important PE related tasks. We evaluate image-only, EHR-only, and multimodal fusion models. Trained models and the de-identified dataset are made available for non-commercial use under a data use agreement. To the best of our knowledge, INSPECT is the largest multimodal dataset integrating 3D medical imaging and EHR for reproducible methods evaluation and research.
Viewpoint Textual Inversion: Unleashing Novel View Synthesis with Pretrained 2D Diffusion Models
Sep 14, 2023Text-to-image diffusion models understand spatial relationship between objects, but do they represent the true 3D structure of the world from only 2D supervision? We demonstrate that yes, 3D knowledge is encoded in 2D image diffusion models like Stable Diffusion, and we show that this structure can be exploited for 3D vision tasks. Our method, Viewpoint Neural Textual Inversion (ViewNeTI), controls the 3D viewpoint of objects in generated images from frozen diffusion models. We train a small neural mapper to take camera viewpoint parameters and predict text encoder latents; the latents then condition the diffusion generation process to produce images with the desired camera viewpoint. ViewNeTI naturally addresses Novel View Synthesis (NVS). By leveraging the frozen diffusion model as a prior, we can solve NVS with very few input views; we can even do single-view novel view synthesis. Our single-view NVS predictions have good semantic details and photorealism compared to prior methods. Our approach is well suited for modeling the uncertainty inherent in sparse 3D vision problems because it can efficiently generate diverse samples. Our view-control mechanism is general, and can even change the camera view in images generated by user-defined prompts.
Generalizable Neural Fields as Partially Observed Neural Processes
Sep 13, 2023Neural fields, which represent signals as a function parameterized by a neural network, are a promising alternative to traditional discrete vector or grid-based representations. Compared to discrete representations, neural representations both scale well with increasing resolution, are continuous, and can be many-times differentiable. However, given a dataset of signals that we would like to represent, having to optimize a separate neural field for each signal is inefficient, and cannot capitalize on shared information or structures among signals. Existing generalization methods view this as a meta-learning problem and employ gradient-based meta-learning to learn an initialization which is then fine-tuned with test-time optimization, or learn hypernetworks to produce the weights of a neural field. We instead propose a new paradigm that views the large-scale training of neural representations as a part of a partially-observed neural process framework, and leverage neural process algorithms to solve this task. We demonstrate that this approach outperforms both state-of-the-art gradient-based meta-learning approaches and hypernetwork approaches.
LOVM: Language-Only Vision Model Selection
Jun 15, 2023Pre-trained multi-modal vision-language models (VLMs) are becoming increasingly popular due to their exceptional performance on downstream vision applications, particularly in the few- and zero-shot settings. However, selecting the best-performing VLM for some downstream applications is non-trivial, as it is dataset and task-dependent. Meanwhile, the exhaustive evaluation of all available VLMs on a novel application is not only time and computationally demanding but also necessitates the collection of a labeled dataset for evaluation. As the number of open-source VLM variants increases, there is a need for an efficient model selection strategy that does not require access to a curated evaluation dataset. This paper proposes a novel task and benchmark for efficiently evaluating VLMs' zero-shot performance on downstream applications without access to the downstream task dataset. Specifically, we introduce a new task LOVM: Language-Only Vision Model Selection, where methods are expected to perform both model selection and performance prediction based solely on a text description of the desired downstream application. We then introduced an extensive LOVM benchmark consisting of ground-truth evaluations of 35 pre-trained VLMs and 23 datasets, where methods are expected to rank the pre-trained VLMs and predict their zero-shot performance.
Beyond Positive Scaling: How Negation Impacts Scaling Trends of Language Models
May 27, 2023



Language models have been shown to exhibit positive scaling, where performance improves as models are scaled up in terms of size, compute, or data. In this work, we introduce NeQA, a dataset consisting of questions with negation in which language models do not exhibit straightforward positive scaling. We show that this task can exhibit inverse scaling, U-shaped scaling, or positive scaling, and the three scaling trends shift in this order as we use more powerful prompting methods or model families. We hypothesize that solving NeQA depends on two subtasks: question answering (task 1) and negation understanding (task 2). We find that task 1 has linear scaling, while task 2 has sigmoid-shaped scaling with an emergent transition point, and composing these two scaling trends yields the final scaling trend of NeQA. Our work reveals and provides a way to analyze the complex scaling trends of language models.
ZeroAvatar: Zero-shot 3D Avatar Generation from a Single Image
May 25, 2023Recent advancements in text-to-image generation have enabled significant progress in zero-shot 3D shape generation. This is achieved by score distillation, a methodology that uses pre-trained text-to-image diffusion models to optimize the parameters of a 3D neural presentation, e.g. Neural Radiance Field (NeRF). While showing promising results, existing methods are often not able to preserve the geometry of complex shapes, such as human bodies. To address this challenge, we present ZeroAvatar, a method that introduces the explicit 3D human body prior to the optimization process. Specifically, we first estimate and refine the parameters of a parametric human body from a single image. Then during optimization, we use the posed parametric body as additional geometry constraint to regularize the diffusion model as well as the underlying density field. Lastly, we propose a UV-guided texture regularization term to further guide the completion of texture on invisible body parts. We show that ZeroAvatar significantly enhances the robustness and 3D consistency of optimization-based image-to-3D avatar generation, outperforming existing zero-shot image-to-3D methods.
Hyperbolic Deep Learning in Computer Vision: A Survey
May 11, 2023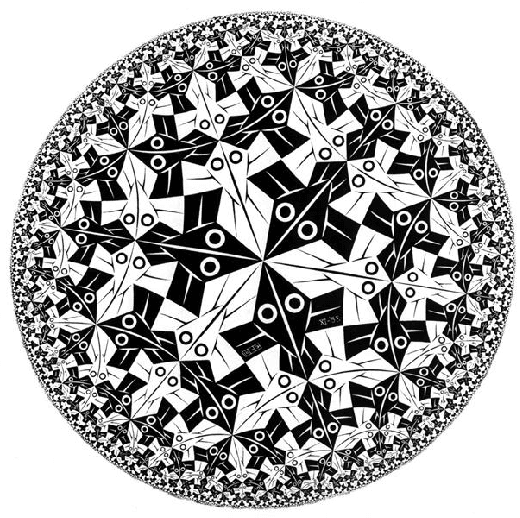
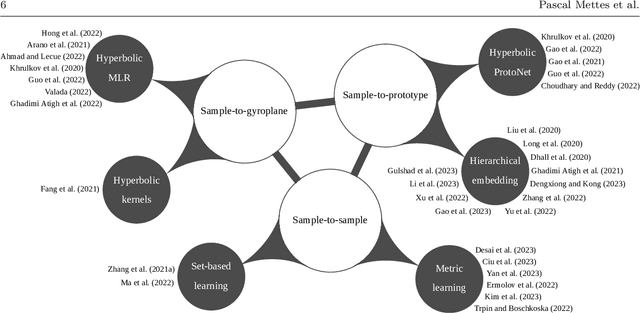
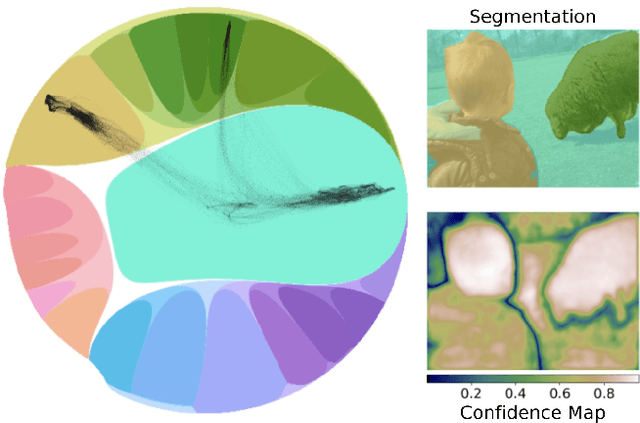
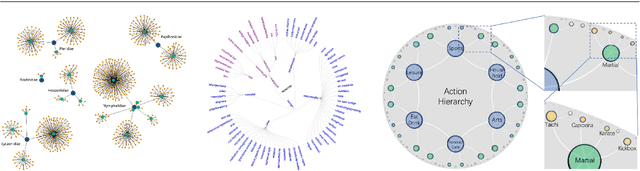
Deep representation learning is a ubiquitous part of modern computer vision. While Euclidean space has been the de facto standard manifold for learning visual representations, hyperbolic space has recently gained rapid traction for learning in computer vision. Specifically, hyperbolic learning has shown a strong potential to embed hierarchical structures, learn from limited samples, quantify uncertainty, add robustness, limit error severity, and more. In this paper, we provide a categorization and in-depth overview of current literature on hyperbolic learning for computer vision. We research both supervised and unsupervised literature and identify three main research themes in each direction. We outline how hyperbolic learning is performed in all themes and discuss the main research problems that benefit from current advances in hyperbolic learning for computer vision. Moreover, we provide a high-level intuition behind hyperbolic geometry and outline open research questions to further advance research in this direction.
Video Pretraining Advances 3D Deep Learning on Chest CT Tasks
Apr 02, 2023Pretraining on large natural image classification datasets such as ImageNet has aided model development on data-scarce 2D medical tasks. 3D medical tasks often have much less data than 2D medical tasks, prompting practitioners to rely on pretrained 2D models to featurize slices. However, these 2D models have been surpassed by 3D models on 3D computer vision benchmarks since they do not natively leverage cross-sectional or temporal information. In this study, we explore whether natural video pretraining for 3D models can enable higher performance on smaller datasets for 3D medical tasks. We demonstrate video pretraining improves the average performance of seven 3D models on two chest CT datasets, regardless of finetuning dataset size, and that video pretraining allows 3D models to outperform 2D baselines. Lastly, we observe that pretraining on the large-scale out-of-domain Kinetics dataset improves performance more than pretraining on a typically-sized in-domain CT dataset. Our results show consistent benefits of video pretraining across a wide array of architectures, tasks, and training dataset sizes, supporting a shift from small-scale in-domain pretraining to large-scale out-of-domain pretraining for 3D medical tasks. Our code is available at: https://github.com/rajpurkarlab/chest-ct-pretraining