 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Perception Benchmark
Aug 15, 2024Humans continuously perceive and process visual signals. However, current video models typically either sample key frames sparsely or divide videos into chunks and densely sample within each chunk. This approach stems from the fact that most existing video benchmarks can be addressed by analyzing key frames or aggregating information from separate chunks. We anticipate that the next generation of vision models will emulate human perception by processing visual input continuously and holistically. To facilitate the development of such models, we propose the Continuous Perception Benchmark, a video question answering task that cannot be solved by focusing solely on a few frames or by captioning small chunks and then summarizing using language models. Extensive experiments demonstrate that existing models, whether commercial or open-source, struggle with these tasks, indicating the need for new technical advancements in this direction.
MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?
Jul 05, 2024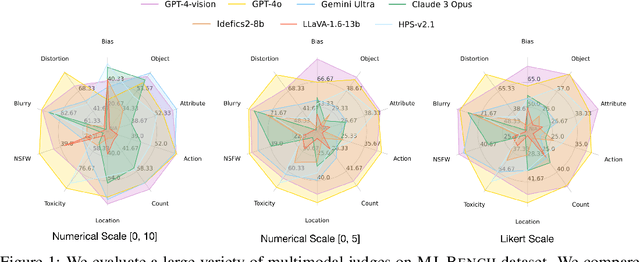
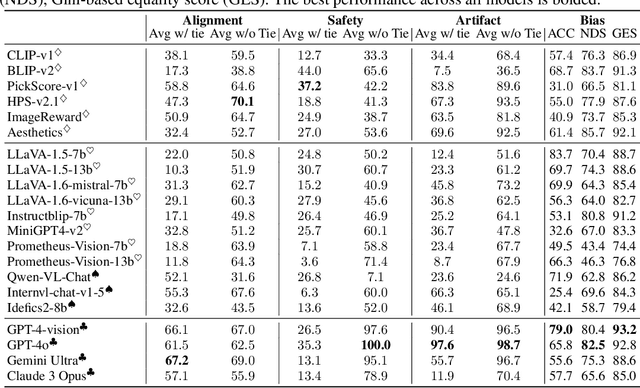

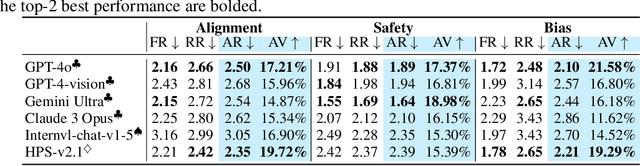
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes. To address this issue, we introduce MJ-Bench, a novel benchmark which incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias. Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset. Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges in average. Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities. Further studies in feedback scale reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales. Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-Bench. All data, code, models are available at https://huggingface.co/MJ-Bench.
Multi-Human Mesh Recovery with Transformers
Feb 26, 2024Conventional approaches to human mesh recovery predominantly employ a region-based strategy. This involves initially cropping out a human-centered region as a preprocessing step, with subsequent modeling focused on this zoomed-in image. While effective for single figures, this pipeline poses challenges when dealing with images featuring multiple individuals, as different people are processed separately, often leading to inaccuracies in relative positioning. Despite the advantages of adopting a whole-image-based approach to address this limitation, early efforts in this direction have fallen short in performance compared to recent region-based methods. In this work, we advocate for this under-explored area of modeling all people at once, emphasizing its potential for improved accuracy in multi-person scenarios through considering all individuals simultaneously and leveraging the overall context and interactions. We introduce a new model with a streamlined transformer-based design, featuring three critical design choices: multi-scale feature incorporation, focused attention mechanisms, and relative joint supervision. Our proposed model demonstrates a significant performance improvement, surpassing state-of-the-art region-based and whole-image-based methods on various benchmarks involving multiple individuals.
Single-View 3D Human Digitalization with Large Reconstruction Models
Jan 22, 2024



In this paper, we introduce Human-LRM, a single-stage feed-forward Large Reconstruction Model designed to predict human Neural Radiance Fields (NeRF) from a single image. Our approach demonstrates remarkable adaptability in training using extensive datasets containing 3D scans and multi-view capture. Furthermore, to enhance the model's applicability for in-the-wild scenarios especially with occlusions, we propose a novel strategy that distills multi-view reconstruction into single-view via a conditional triplane diffusion model. This generative extension addresses the inherent variations in human body shapes when observed from a single view, and makes it possible to reconstruct the full body human from an occluded image. Through extensive experiments, we show that Human-LRM surpasses previous methods by a significant margin on several benchmarks.
3D Human Keypoints Estimation From Point Clouds in the Wild Without Human Labels
Jun 07, 2023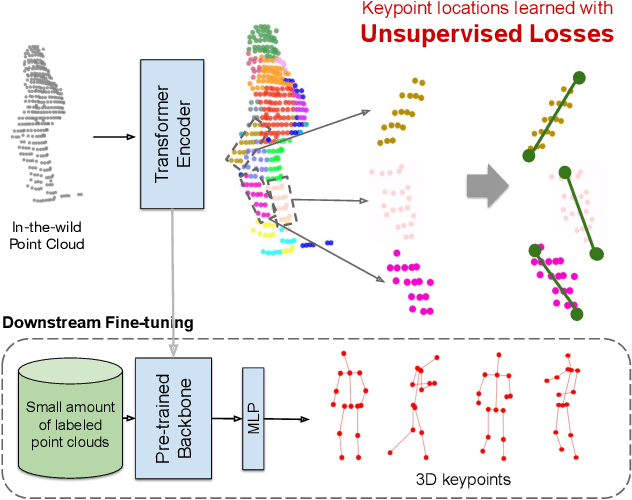
Training a 3D human keypoint detector from point clouds in a supervised manner requires large volumes of high quality labels. While it is relatively easy to capture large amounts of human point clouds, annotating 3D keypoints is expensive, subjective, error prone and especially difficult for long-tail cases (pedestrians with rare poses, scooterists, etc.). In this work, we propose GC-KPL - Geometry Consistency inspired Key Point Leaning, an approach for learning 3D human joint locations from point clouds without human labels. We achieve this by our novel unsupervised loss formulations that account for the structure and movement of the human body. We show that by training on a large training set from Waymo Open Dataset without any human annotated keypoints, we are able to achieve reasonable performance as compared to the fully supervised approach. Further, the backbone benefits from the unsupervised training and is useful in downstream fewshot learning of keypoints, where fine-tuning on only 10 percent of the labeled training data gives comparable performance to fine-tuning on the entire set. We demonstrated that GC-KPL outperforms by a large margin over SoTA when trained on entire dataset and efficiently leverages large volumes of unlabeled data.
ZeroAvatar: Zero-shot 3D Avatar Generation from a Single Image
May 25, 2023Recent advancements in text-to-image generation have enabled significant progress in zero-shot 3D shape generation. This is achieved by score distillation, a methodology that uses pre-trained text-to-image diffusion models to optimize the parameters of a 3D neural presentation, e.g. Neural Radiance Field (NeRF). While showing promising results, existing methods are often not able to preserve the geometry of complex shapes, such as human bodies. To address this challenge, we present ZeroAvatar, a method that introduces the explicit 3D human body prior to the optimization process. Specifically, we first estimate and refine the parameters of a parametric human body from a single image. Then during optimization, we use the posed parametric body as additional geometry constraint to regularize the diffusion model as well as the underlying density field. Lastly, we propose a UV-guided texture regularization term to further guide the completion of texture on invisible body parts. We show that ZeroAvatar significantly enhances the robustness and 3D consistency of optimization-based image-to-3D avatar generation, outperforming existing zero-shot image-to-3D methods.
Diffusion-HPC: Generating Synthetic Images with Realistic Humans
Mar 16, 2023Recent text-to-image generative models have exhibited remarkable abilities in generating high-fidelity and photo-realistic images. However, despite the visually impressive results, these models often struggle to preserve plausible human structure in the generations. Due to this reason, while generative models have shown promising results in aiding downstream image recognition tasks by generating large volumes of synthetic data, they remain infeasible for improving downstream human pose perception and understanding. In this work, we propose Diffusion model with Human Pose Correction (Diffusion HPC), a text-conditioned method that generates photo-realistic images with plausible posed humans by injecting prior knowledge about human body structure. We show that Diffusion HPC effectively improves the realism of human generations. Furthermore, as the generations are accompanied by 3D meshes that serve as ground truths, Diffusion HPC's generated image-mesh pairs are well-suited for downstream human mesh recovery task, where a shortage of 3D training data has long been an issue.
NeMo: 3D Neural Motion Fields from Multiple Video Instances of the Same Action
Dec 28, 2022The task of reconstructing 3D human motion has wideranging applications. The gold standard Motion capture (MoCap) systems are accurate but inaccessible to the general public due to their cost, hardware and space constraints. In contrast, monocular human mesh recovery (HMR) methods are much more accessible than MoCap as they take single-view videos as inputs. Replacing the multi-view Mo- Cap systems with a monocular HMR method would break the current barriers to collecting accurate 3D motion thus making exciting applications like motion analysis and motiondriven animation accessible to the general public. However, performance of existing HMR methods degrade when the video contains challenging and dynamic motion that is not in existing MoCap datasets used for training. This reduces its appeal as dynamic motion is frequently the target in 3D motion recovery in the aforementioned applications. Our study aims to bridge the gap between monocular HMR and multi-view MoCap systems by leveraging information shared across multiple video instances of the same action. We introduce the Neural Motion (NeMo) field. It is optimized to represent the underlying 3D motions across a set of videos of the same action. Empirically, we show that NeMo can recover 3D motion in sports using videos from the Penn Action dataset, where NeMo outperforms existing HMR methods in terms of 2D keypoint detection. To further validate NeMo using 3D metrics, we collected a small MoCap dataset mimicking actions in Penn Action,and show that NeMo achieves better 3D reconstruction compared to various baselines.
Domain Adaptive 3D Pose Augmentation for In-the-wild Human Mesh Recovery
Jun 21, 2022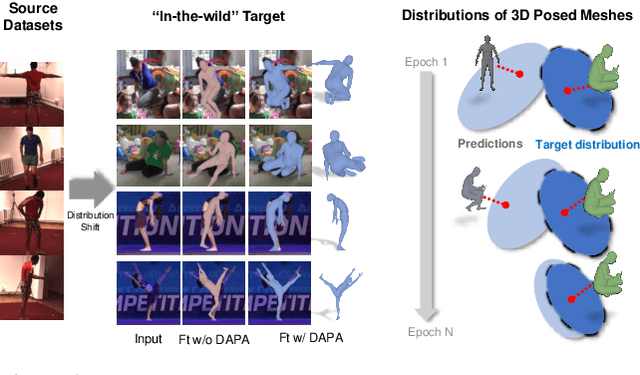
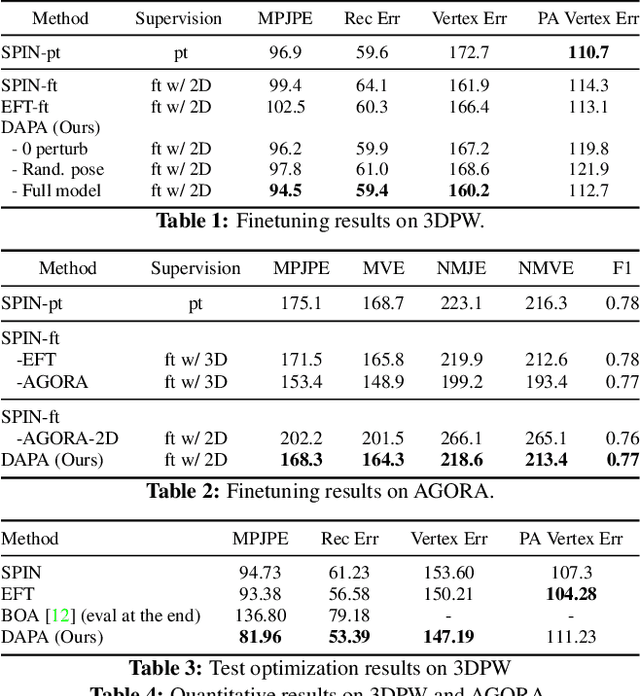
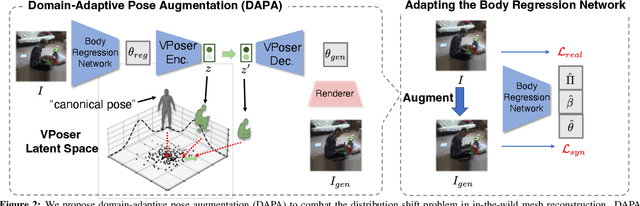

The ability to perceive 3D human bodies from a single image has a multitude of applications ranging from entertainment and robotics to neuroscience and healthcare. A fundamental challenge in human mesh recovery is in collecting the ground truth 3D mesh targets required for training, which requires burdensome motion capturing systems and is often limited to indoor laboratories. As a result, while progress is made on benchmark datasets collected in these restrictive settings, models fail to generalize to real-world ``in-the-wild'' scenarios due to distribution shifts. We propose Domain Adaptive 3D Pose Augmentation (DAPA), a data augmentation method that enhances the model's generalization ability in in-the-wild scenarios. DAPA combines the strength of methods based on synthetic datasets by getting direct supervision from the synthesized meshes, and domain adaptation methods by using ground truth 2D keypoints from the target dataset. We show quantitatively that finetuning with DAPA effectively improves results on benchmarks 3DPW and AGORA. We further demonstrate the utility of DAPA on a challenging dataset curated from videos of real-world parent-child interaction.
Unsupervised Discovery of the Long-Tail in Instance Segmentation Using Hierarchical Self-Supervision
Apr 02, 2021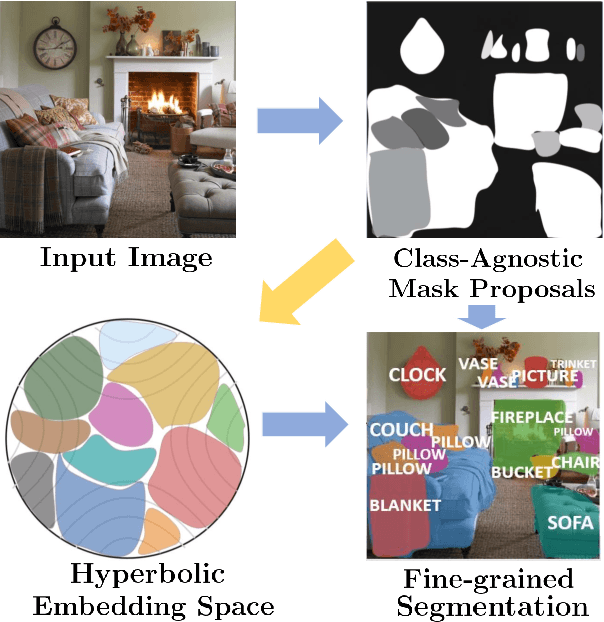
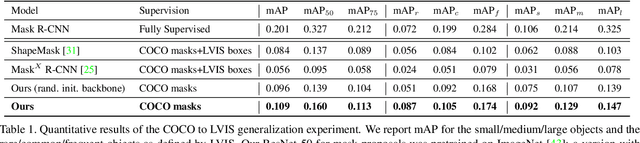
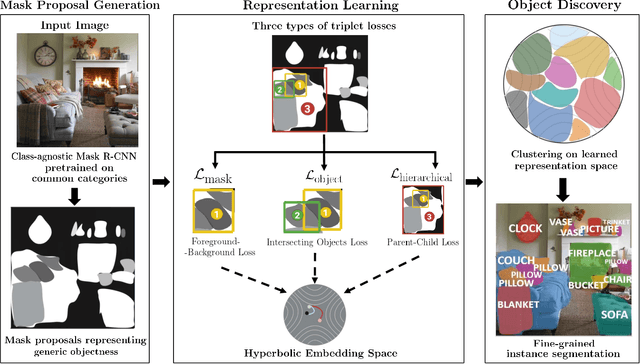
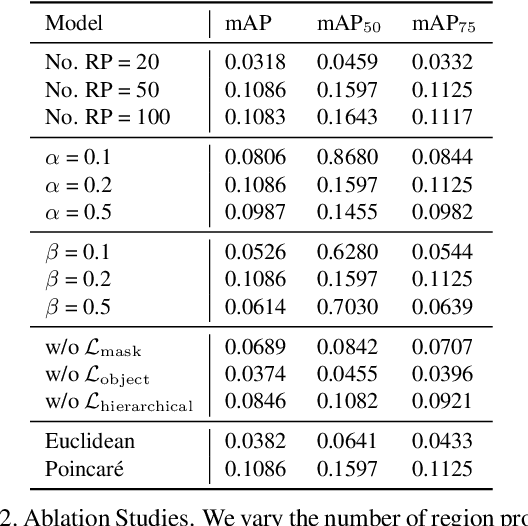
Instance segmentation is an active topic in computer vision that is usually solved by using supervised learning approaches over very large datasets composed of object level masks. Obtaining such a dataset for any new domain can be very expensive and time-consuming. In addition, models trained on certain annotated categories do not generalize well to unseen objects. The goal of this paper is to propose a method that can perform unsupervised discovery of long-tail categories in instance segmentation, through learning instance embeddings of masked regions. Leveraging rich relationship and hierarchical structure between objects in the images, we propose self-supervised losses for learning mask embeddings. Trained on COCO dataset without additional annotations of the long-tail objects, our model is able to discover novel and more fine-grained objects than the common categories in COCO. We show that the model achieves competitive quantitative results on LVIS as compared to the supervised and partially supervised methods.