 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
Oct 02, 2025Humanoid motion tracking policies are central to building teleoperation pipelines and hierarchical controllers, yet they face a fundamental challenge: the embodiment gap between humans and humanoid robots. Current approaches address this gap by retargeting human motion data to humanoid embodiments and then training reinforcement learning (RL) policies to imitate these reference trajectories. However, artifacts introduced during retargeting, such as foot sliding, self-penetration, and physically infeasible motion are often left in the reference trajectories for the RL policy to correct. While prior work has demonstrated motion tracking abilities, they often require extensive reward engineering and domain randomization to succeed. In this paper, we systematically evaluate how retargeting quality affects policy performance when excessive reward tuning is suppressed. To address issues that we identify with existing retargeting methods, we propose a new retargeting method, General Motion Retargeting (GMR). We evaluate GMR alongside two open-source retargeters, PHC and ProtoMotions, as well as with a high-quality closed-source dataset from Unitree. Using BeyondMimic for policy training, we isolate retargeting effects without reward tuning. Our experiments on a diverse subset of the LAFAN1 dataset reveal that while most motions can be tracked, artifacts in retargeted data significantly reduce policy robustness, particularly for dynamic or long sequences. GMR consistently outperforms existing open-source methods in both tracking performance and faithfulness to the source motion, achieving perceptual fidelity and policy success rates close to the closed-source baseline. Website: https://jaraujo98.github.io/retargeting_matters. Code: https://github.com/YanjieZe/GMR.
CIRCLE: Capture In Rich Contextual Environments
Mar 31, 2023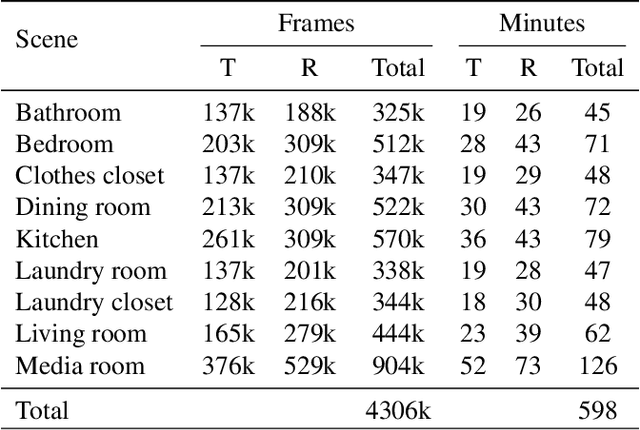
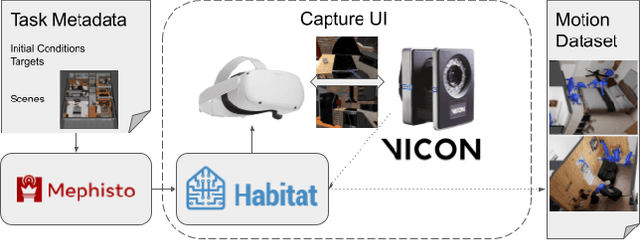

Synthesizing 3D human motion in a contextual, ecological environment is important for simulating realistic activities people perform in the real world. However, conventional optics-based motion capture systems are not suited for simultaneously capturing human movements and complex scenes. The lack of rich contextual 3D human motion datasets presents a roadblock to creating high-quality generative human motion models. We propose a novel motion acquisition system in which the actor perceives and operates in a highly contextual virtual world while being motion captured in the real world. Our system enables rapid collection of high-quality human motion in highly diverse scenes, without the concern of occlusion or the need for physical scene construction in the real world. We present CIRCLE, a dataset containing 10 hours of full-body reaching motion from 5 subjects across nine scenes, paired with ego-centric information of the environment represented in various forms, such as RGBD videos. We use this dataset to train a model that generates human motion conditioned on scene information. Leveraging our dataset, the model learns to use ego-centric scene information to achieve nontrivial reaching tasks in the context of complex 3D scenes. To download the data please visit https://stanford-tml.github.io/circle_dataset/.
NeMo: 3D Neural Motion Fields from Multiple Video Instances of the Same Action
Dec 28, 2022The task of reconstructing 3D human motion has wideranging applications. The gold standard Motion capture (MoCap) systems are accurate but inaccessible to the general public due to their cost, hardware and space constraints. In contrast, monocular human mesh recovery (HMR) methods are much more accessible than MoCap as they take single-view videos as inputs. Replacing the multi-view Mo- Cap systems with a monocular HMR method would break the current barriers to collecting accurate 3D motion thus making exciting applications like motion analysis and motiondriven animation accessible to the general public. However, performance of existing HMR methods degrade when the video contains challenging and dynamic motion that is not in existing MoCap datasets used for training. This reduces its appeal as dynamic motion is frequently the target in 3D motion recovery in the aforementioned applications. Our study aims to bridge the gap between monocular HMR and multi-view MoCap systems by leveraging information shared across multiple video instances of the same action. We introduce the Neural Motion (NeMo) field. It is optimized to represent the underlying 3D motions across a set of videos of the same action. Empirically, we show that NeMo can recover 3D motion in sports using videos from the Penn Action dataset, where NeMo outperforms existing HMR methods in terms of 2D keypoint detection. To further validate NeMo using 3D metrics, we collected a small MoCap dataset mimicking actions in Penn Action,and show that NeMo achieves better 3D reconstruction compared to various baselines.