 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotMover: Learning to Move Large Objects by Imitating the Dynamic Chain
Feb 07, 2025Moving large objects, such as furniture, is a critical capability for robots operating in human environments. This task presents significant challenges due to two key factors: the need to synchronize whole-body movements to prevent collisions between the robot and the object, and the under-actuated dynamics arising from the substantial size and weight of the objects. These challenges also complicate performing these tasks via teleoperation. In this work, we introduce \method, a generalizable learning framework that leverages human-object interaction demonstrations to enable robots to perform large object manipulation tasks. Central to our approach is the Dynamic Chain, a novel representation that abstracts human-object interactions so that they can be retargeted to robotic morphologies. The Dynamic Chain is a spatial descriptor connecting the human and object root position via a chain of nodes, which encode the position and velocity of different interaction keypoints. We train policies in simulation using Dynamic-Chain-based imitation rewards and domain randomization, enabling zero-shot transfer to real-world settings without fine-tuning. Our approach outperforms both learning-based methods and teleoperation baselines across six evaluation metrics when tested on three distinct object types, both in simulation and on physical hardware. Furthermore, we successfully apply the learned policies to real-world tasks, such as moving a trash cart and rearranging chairs.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024
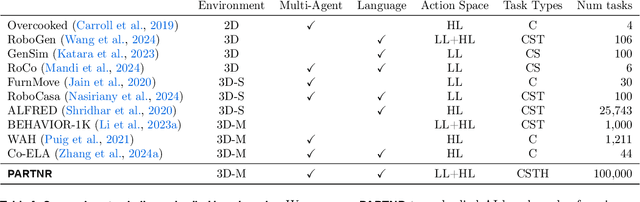

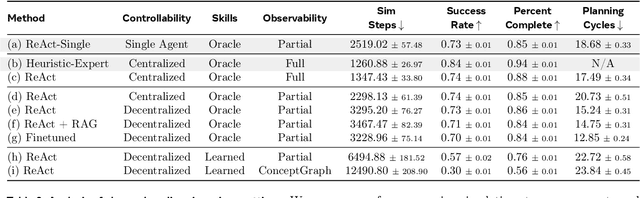
We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Controllable Human-Object Interaction Synthesis
Dec 06, 2023
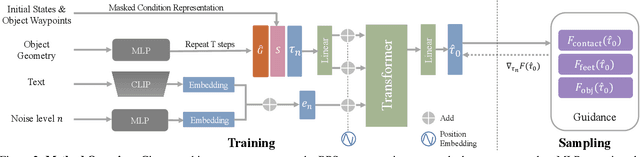
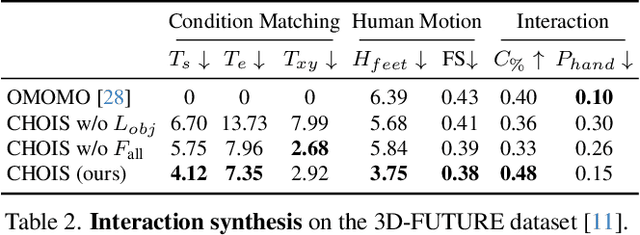
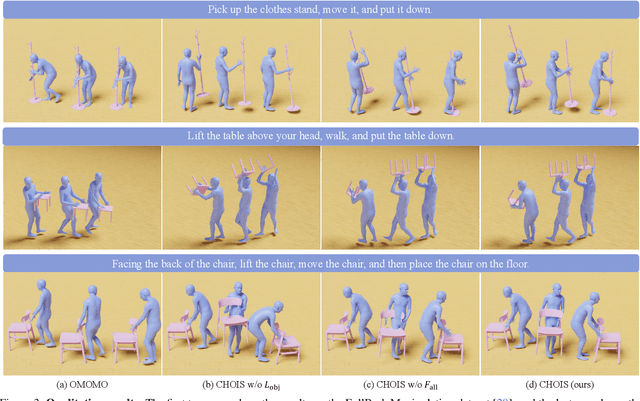
Synthesizing semantic-aware, long-horizon, human-object interaction is critical to simulate realistic human behaviors. In this work, we address the challenging problem of generating synchronized object motion and human motion guided by language descriptions in 3D scenes. We propose Controllable Human-Object Interaction Synthesis (CHOIS), an approach that generates object motion and human motion simultaneously using a conditional diffusion model given a language description, initial object and human states, and sparse object waypoints. While language descriptions inform style and intent, waypoints ground the motion in the scene and can be effectively extracted using high-level planning methods. Naively applying a diffusion model fails to predict object motion aligned with the input waypoints and cannot ensure the realism of interactions that require precise hand-object contact and appropriate contact grounded by the floor. To overcome these problems, we introduce an object geometry loss as additional supervision to improve the matching between generated object motion and input object waypoints. In addition, we design guidance terms to enforce contact constraints during the sampling process of the trained diffusion model.
Habitat Synthetic Scenes Dataset (HSSD-200): An Analysis of 3D Scene Scale and Realism Tradeoffs for ObjectGoal Navigation
Jun 21, 2023We contribute the Habitat Synthetic Scene Dataset, a dataset of 211 high-quality 3D scenes, and use it to test navigation agent generalization to realistic 3D environments. Our dataset represents real interiors and contains a diverse set of 18,656 models of real-world objects. We investigate the impact of synthetic 3D scene dataset scale and realism on the task of training embodied agents to find and navigate to objects (ObjectGoal navigation). By comparing to synthetic 3D scene datasets from prior work, we find that scale helps in generalization, but the benefits quickly saturate, making visual fidelity and correlation to real-world scenes more important. Our experiments show that agents trained on our smaller-scale dataset can match or outperform agents trained on much larger datasets. Surprisingly, we observe that agents trained on just 122 scenes from our dataset outperform agents trained on 10,000 scenes from the ProcTHOR-10K dataset in terms of zero-shot generalization in real-world scanned environments.
ACE: Adversarial Correspondence Embedding for Cross Morphology Motion Retargeting from Human to Nonhuman Characters
May 24, 2023



Motion retargeting is a promising approach for generating natural and compelling animations for nonhuman characters. However, it is challenging to translate human movements into semantically equivalent motions for target characters with different morphologies due to the ambiguous nature of the problem. This work presents a novel learning-based motion retargeting framework, Adversarial Correspondence Embedding (ACE), to retarget human motions onto target characters with different body dimensions and structures. Our framework is designed to produce natural and feasible robot motions by leveraging generative-adversarial networks (GANs) while preserving high-level motion semantics by introducing an additional feature loss. In addition, we pretrain a robot motion prior that can be controlled in a latent embedding space and seek to establish a compact correspondence. We demonstrate that the proposed framework can produce retargeted motions for three different characters -- a quadrupedal robot with a manipulator, a crab character, and a wheeled manipulator. We further validate the design choices of our framework by conducting baseline comparisons and a user study. We also showcase sim-to-real transfer of the retargeted motions by transferring them to a real Spot robot.
CIRCLE: Capture In Rich Contextual Environments
Mar 31, 2023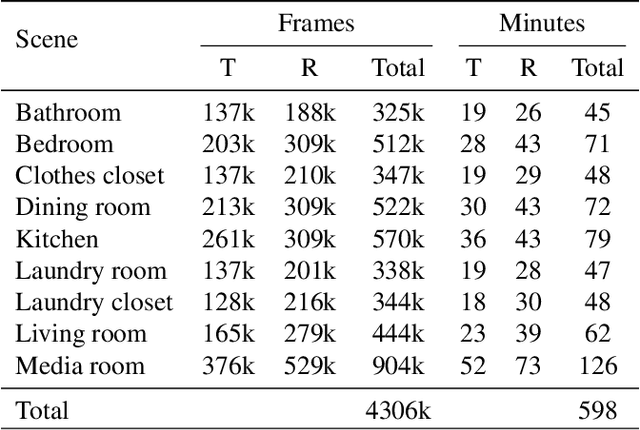
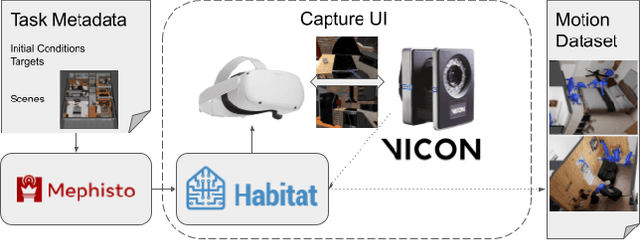

Synthesizing 3D human motion in a contextual, ecological environment is important for simulating realistic activities people perform in the real world. However, conventional optics-based motion capture systems are not suited for simultaneously capturing human movements and complex scenes. The lack of rich contextual 3D human motion datasets presents a roadblock to creating high-quality generative human motion models. We propose a novel motion acquisition system in which the actor perceives and operates in a highly contextual virtual world while being motion captured in the real world. Our system enables rapid collection of high-quality human motion in highly diverse scenes, without the concern of occlusion or the need for physical scene construction in the real world. We present CIRCLE, a dataset containing 10 hours of full-body reaching motion from 5 subjects across nine scenes, paired with ego-centric information of the environment represented in various forms, such as RGBD videos. We use this dataset to train a model that generates human motion conditioned on scene information. Leveraging our dataset, the model learns to use ego-centric scene information to achieve nontrivial reaching tasks in the context of complex 3D scenes. To download the data please visit https://stanford-tml.github.io/circle_dataset/.
Learning to Transfer In-Hand Manipulations Using a Greedy Shape Curriculum
Mar 14, 2023In-hand object manipulation is challenging to simulate due to complex contact dynamics, non-repetitive finger gaits, and the need to indirectly control unactuated objects. Further adapting a successful manipulation skill to new objects with different shapes and physical properties is a similarly challenging problem. In this work, we show that natural and robust in-hand manipulation of simple objects in a dynamic simulation can be learned from a high quality motion capture example via deep reinforcement learning with careful designs of the imitation learning problem. We apply our approach on both single-handed and two-handed dexterous manipulations of diverse object shapes and motions. We then demonstrate further adaptation of the example motion to a more complex shape through curriculum learning on intermediate shapes morphed between the source and target object. While a naive curriculum of progressive morphs often falls short, we propose a simple greedy curriculum search algorithm that can successfully apply to a range of objects such as a teapot, bunny, bottle, train, and elephant.
SoundSpaces 2.0: A Simulation Platform for Visual-Acoustic Learning
Jun 16, 2022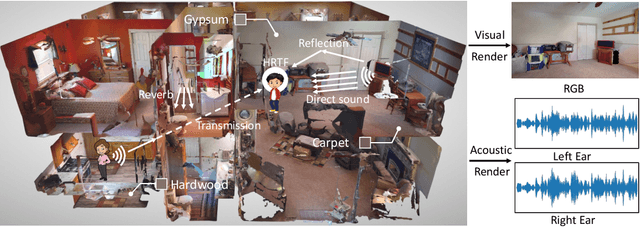


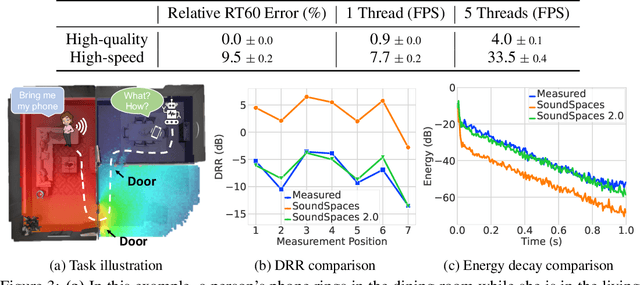
We introduce SoundSpaces 2.0, a platform for on-the-fly geometry-based audio rendering for 3D environments. Given a 3D mesh of a real-world environment, SoundSpaces can generate highly realistic acoustics for arbitrary sounds captured from arbitrary microphone locations. Together with existing 3D visual assets, it supports an array of audio-visual research tasks, such as audio-visual navigation, mapping, source localization and separation, and acoustic matching. Compared to existing resources, SoundSpaces 2.0 has the advantages of allowing continuous spatial sampling, generalization to novel environments, and configurable microphone and material properties. To our best knowledge, this is the first geometry-based acoustic simulation that offers high fidelity and realism while also being fast enough to use for embodied learning. We showcase the simulator's properties and benchmark its performance against real-world audio measurements. In addition, through two downstream tasks covering embodied navigation and far-field automatic speech recognition, highlighting sim2real performance for the latter. SoundSpaces 2.0 is publicly available to facilitate wider research for perceptual systems that can both see and hear.
iSDF: Real-Time Neural Signed Distance Fields for Robot Perception
Apr 05, 2022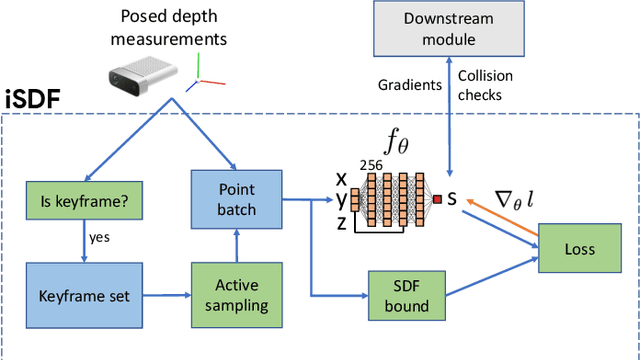
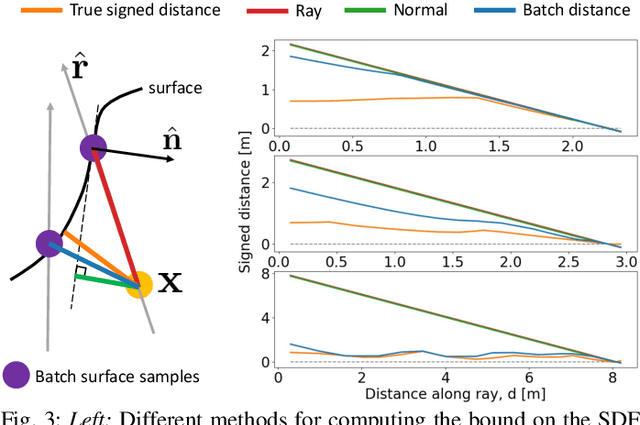
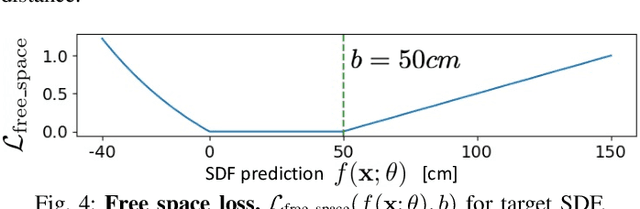
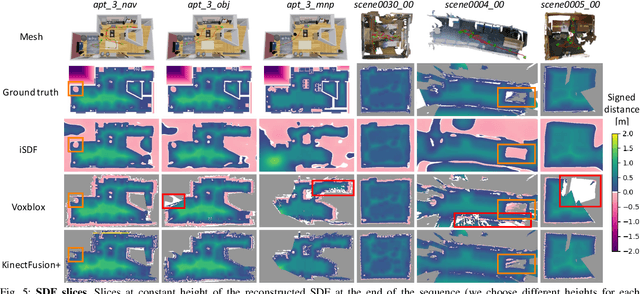
We present iSDF, a continual learning system for real-time signed distance field (SDF) reconstruction. Given a stream of posed depth images from a moving camera, it trains a randomly initialised neural network to map input 3D coordinate to approximate signed distance. The model is self-supervised by minimising a loss that bounds the predicted signed distance using the distance to the closest sampled point in a batch of query points that are actively sampled. In contrast to prior work based on voxel grids, our neural method is able to provide adaptive levels of detail with plausible filling in of partially observed regions and denoising of observations, all while having a more compact representation. In evaluations against alternative methods on real and synthetic datasets of indoor environments, we find that iSDF produces more accurate reconstructions, and better approximations of collision costs and gradients useful for downstream planners in domains from navigation to manipulation. Code and video results can be found at our project page: https://joeaortiz.github.io/iSDF/ .