 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAPT: Actively Discovering and Adapting to Preferences for any Task
Apr 05, 2025Assistive agents should be able to perform under-specified long-horizon tasks while respecting user preferences. We introduce Actively Discovering and Adapting to Preferences for any Task (ADAPT) -- a benchmark designed to evaluate agents' ability to adhere to user preferences across various household tasks through active questioning. Next, we propose Reflection-DPO, a novel training approach for adapting large language models (LLMs) to the task of active questioning. Reflection-DPO finetunes a 'student' LLM to follow the actions of a privileged 'teacher' LLM, and optionally ask a question to gather necessary information to better predict the teacher action. We find that prior approaches that use state-of-the-art LLMs fail to sufficiently follow user preferences in ADAPT due to insufficient questioning and poor adherence to elicited preferences. In contrast, Reflection-DPO achieves a higher rate of satisfying user preferences, outperforming a zero-shot chain-of-thought baseline by 6.1% on unseen users.
Grounding Multimodal LLMs to Embodied Agents that Ask for Help with Reinforcement Learning
Apr 02, 2025
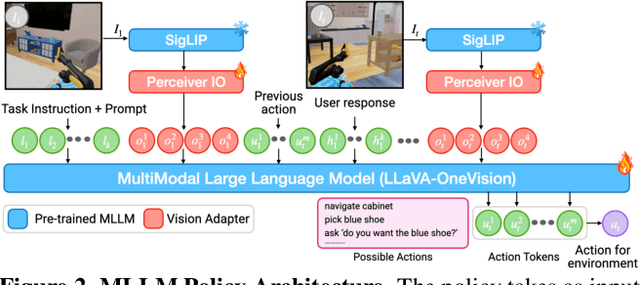
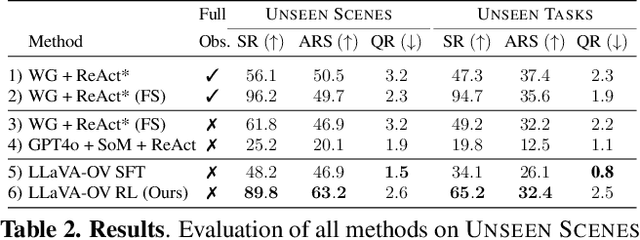
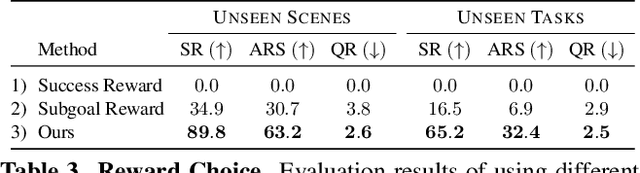
Embodied agents operating in real-world environments must interpret ambiguous and under-specified human instructions. A capable household robot should recognize ambiguity and ask relevant clarification questions to infer the user intent accurately, leading to more effective task execution. To study this problem, we introduce the Ask-to-Act task, where an embodied agent must fetch a specific object instance given an ambiguous instruction in a home environment. The agent must strategically ask minimal, yet relevant, clarification questions to resolve ambiguity while navigating under partial observability. To solve this problem, we propose a novel approach that fine-tunes multimodal large language models (MLLMs) as vision-language-action (VLA) policies using online reinforcement learning (RL) with LLM-generated rewards. Our method eliminates the need for large-scale human demonstrations or manually engineered rewards for training such agents. We benchmark against strong zero-shot baselines, including GPT-4o, and supervised fine-tuned MLLMs, on our task. Our results demonstrate that our RL-finetuned MLLM outperforms all baselines by a significant margin ($19.1$-$40.3\%$), generalizing well to novel scenes and tasks. To the best of our knowledge, this is the first demonstration of adapting MLLMs as VLA agents that can act and ask for help using LLM-generated rewards with online RL.
RobotMover: Learning to Move Large Objects by Imitating the Dynamic Chain
Feb 07, 2025Moving large objects, such as furniture, is a critical capability for robots operating in human environments. This task presents significant challenges due to two key factors: the need to synchronize whole-body movements to prevent collisions between the robot and the object, and the under-actuated dynamics arising from the substantial size and weight of the objects. These challenges also complicate performing these tasks via teleoperation. In this work, we introduce \method, a generalizable learning framework that leverages human-object interaction demonstrations to enable robots to perform large object manipulation tasks. Central to our approach is the Dynamic Chain, a novel representation that abstracts human-object interactions so that they can be retargeted to robotic morphologies. The Dynamic Chain is a spatial descriptor connecting the human and object root position via a chain of nodes, which encode the position and velocity of different interaction keypoints. We train policies in simulation using Dynamic-Chain-based imitation rewards and domain randomization, enabling zero-shot transfer to real-world settings without fine-tuning. Our approach outperforms both learning-based methods and teleoperation baselines across six evaluation metrics when tested on three distinct object types, both in simulation and on physical hardware. Furthermore, we successfully apply the learned policies to real-world tasks, such as moving a trash cart and rearranging chairs.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024
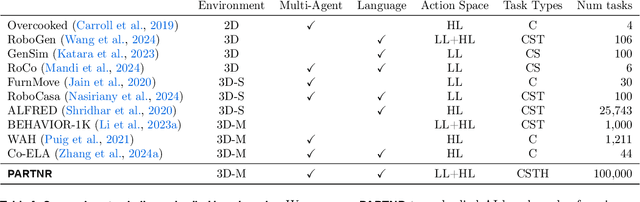

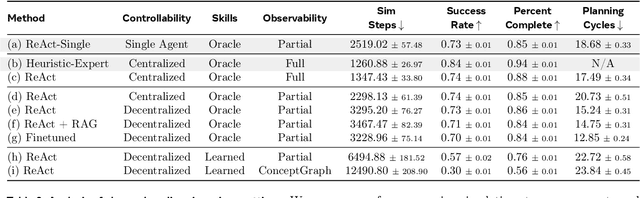
We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
Controllable Human-Object Interaction Synthesis
Dec 06, 2023
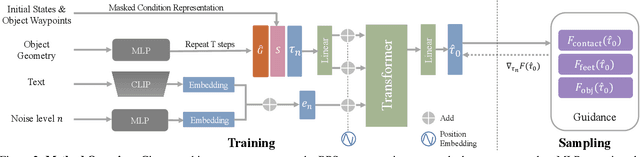
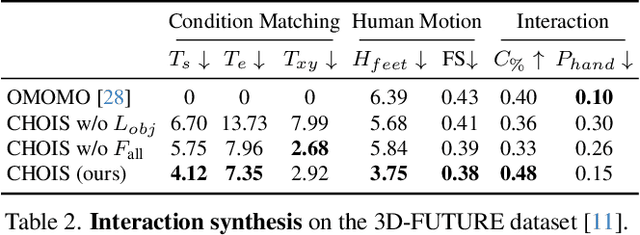
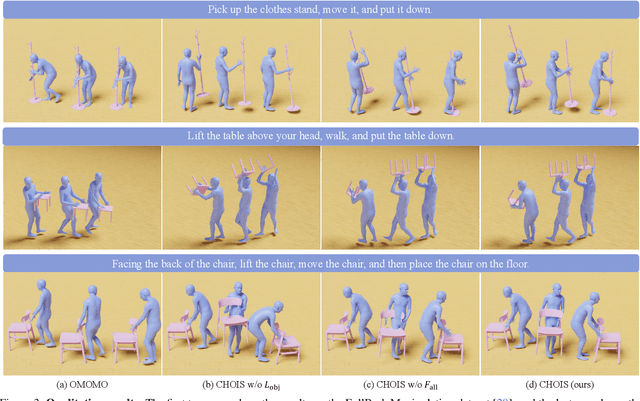
Synthesizing semantic-aware, long-horizon, human-object interaction is critical to simulate realistic human behaviors. In this work, we address the challenging problem of generating synchronized object motion and human motion guided by language descriptions in 3D scenes. We propose Controllable Human-Object Interaction Synthesis (CHOIS), an approach that generates object motion and human motion simultaneously using a conditional diffusion model given a language description, initial object and human states, and sparse object waypoints. While language descriptions inform style and intent, waypoints ground the motion in the scene and can be effectively extracted using high-level planning methods. Naively applying a diffusion model fails to predict object motion aligned with the input waypoints and cannot ensure the realism of interactions that require precise hand-object contact and appropriate contact grounded by the floor. To overcome these problems, we introduce an object geometry loss as additional supervision to improve the matching between generated object motion and input object waypoints. In addition, we design guidance terms to enforce contact constraints during the sampling process of the trained diffusion model.
Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots
Oct 19, 2023



We present Habitat 3.0: a simulation platform for studying collaborative human-robot tasks in home environments. Habitat 3.0 offers contributions across three dimensions: (1) Accurate humanoid simulation: addressing challenges in modeling complex deformable bodies and diversity in appearance and motion, all while ensuring high simulation speed. (2) Human-in-the-loop infrastructure: enabling real human interaction with simulated robots via mouse/keyboard or a VR interface, facilitating evaluation of robot policies with human input. (3) Collaborative tasks: studying two collaborative tasks, Social Navigation and Social Rearrangement. Social Navigation investigates a robot's ability to locate and follow humanoid avatars in unseen environments, whereas Social Rearrangement addresses collaboration between a humanoid and robot while rearranging a scene. These contributions allow us to study end-to-end learned and heuristic baselines for human-robot collaboration in-depth, as well as evaluate them with humans in the loop. Our experiments demonstrate that learned robot policies lead to efficient task completion when collaborating with unseen humanoid agents and human partners that might exhibit behaviors that the robot has not seen before. Additionally, we observe emergent behaviors during collaborative task execution, such as the robot yielding space when obstructing a humanoid agent, thereby allowing the effective completion of the task by the humanoid agent. Furthermore, our experiments using the human-in-the-loop tool demonstrate that our automated evaluation with humanoids can provide an indication of the relative ordering of different policies when evaluated with real human collaborators. Habitat 3.0 unlocks interesting new features in simulators for Embodied AI, and we hope it paves the way for a new frontier of embodied human-AI interaction capabilities.
Generating Continual Human Motion in Diverse 3D Scenes
Apr 11, 2023We introduce a method to synthesize animator guided human motion across 3D scenes. Given a set of sparse (3 or 4) joint locations (such as the location of a person's hand and two feet) and a seed motion sequence in a 3D scene, our method generates a plausible motion sequence starting from the seed motion while satisfying the constraints imposed by the provided keypoints. We decompose the continual motion synthesis problem into walking along paths and transitioning in and out of the actions specified by the keypoints, which enables long generation of motions that satisfy scene constraints without explicitly incorporating scene information. Our method is trained only using scene agnostic mocap data. As a result, our approach is deployable across 3D scenes with various geometries. For achieving plausible continual motion synthesis without drift, our key contribution is to generate motion in a goal-centric canonical coordinate frame where the next immediate target is situated at the origin. Our model can generate long sequences of diverse actions such as grabbing, sitting and leaning chained together in arbitrary order, demonstrated on scenes of varying geometry: HPS, Replica, Matterport, ScanNet and scenes represented using NeRFs. Several experiments demonstrate that our method outperforms existing methods that navigate paths in 3D scenes.
NOPA: Neurally-guided Online Probabilistic Assistance for Building Socially Intelligent Home Assistants
Jan 12, 2023In this work, we study how to build socially intelligent robots to assist people in their homes. In particular, we focus on assistance with online goal inference, where robots must simultaneously infer humans' goals and how to help them achieve those goals. Prior assistance methods either lack the adaptivity to adjust helping strategies (i.e., when and how to help) in response to uncertainty about goals or the scalability to conduct fast inference in a large goal space. Our NOPA (Neurally-guided Online Probabilistic Assistance) method addresses both of these challenges. NOPA consists of (1) an online goal inference module combining neural goal proposals with inverse planning and particle filtering for robust inference under uncertainty, and (2) a helping planner that discovers valuable subgoals to help with and is aware of the uncertainty in goal inference. We compare NOPA against multiple baselines in a new embodied AI assistance challenge: Online Watch-And-Help, in which a helper agent needs to simultaneously watch a main agent's action, infer its goal, and help perform a common household task faster in realistic virtual home environments. Experiments show that our helper agent robustly updates its goal inference and adapts its helping plans to the changing level of uncertainty.
Pre-Trained Language Models for Interactive Decision-Making
Feb 03, 2022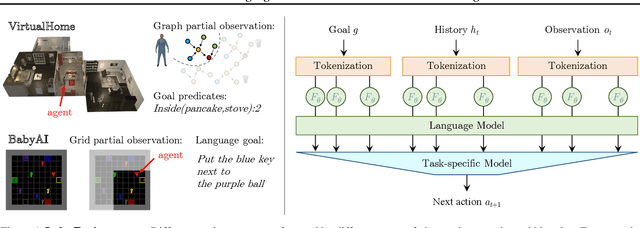
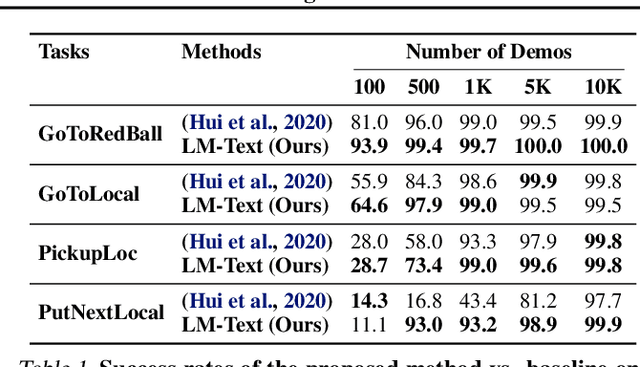
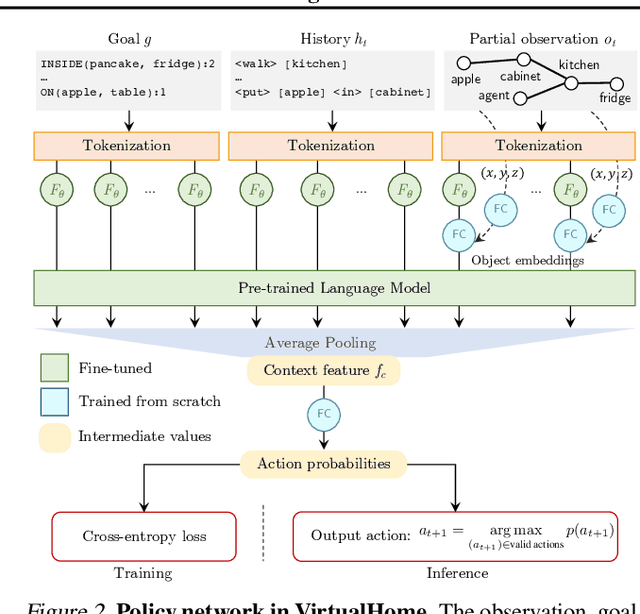
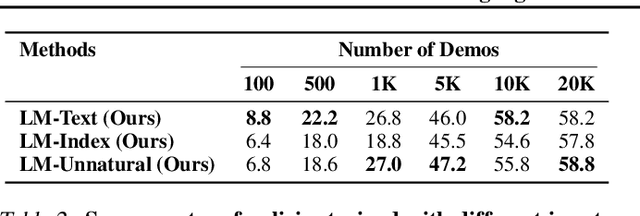
Language model (LM) pre-training has proven useful for a wide variety of language processing tasks, but can such pre-training be leveraged for more general machine learning problems? We investigate the effectiveness of language modeling to scaffold learning and generalization in autonomous decision-making. We describe a framework for imitation learning in which goals and observations are represented as a sequence of embeddings, and translated into actions using a policy network initialized with a pre-trained transformer LM. We demonstrate that this framework enables effective combinatorial generalization across different environments, such as VirtualHome and BabyAI. In particular, for test tasks involving novel goals or novel scenes, initializing policies with language models improves task completion rates by 43.6% in VirtualHome. We hypothesize and investigate three possible factors underlying the effectiveness of LM-based policy initialization. We find that sequential representations (vs. fixed-dimensional feature vectors) and the LM objective (not just the transformer architecture) are both important for generalization. Surprisingly, however, the format of the policy inputs encoding (e.g. as a natural language string vs. an arbitrary sequential encoding) has little influence. Together, these results suggest that language modeling induces representations that are useful for modeling not just language, but also goals and plans; these representations can aid learning and generalization even outside of language processing.
Generative Models as a Data Source for Multiview Representation Learning
Jun 09, 2021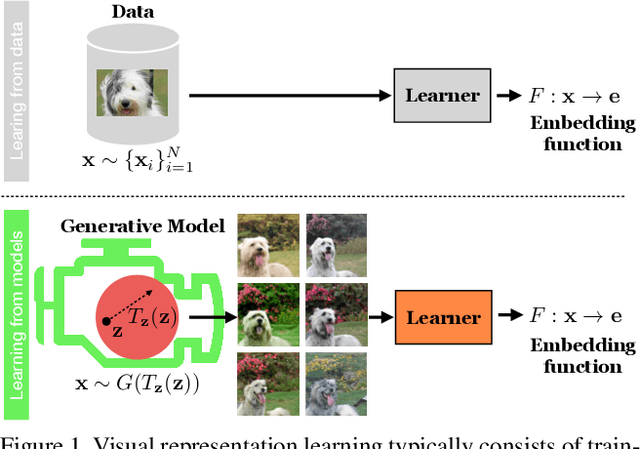
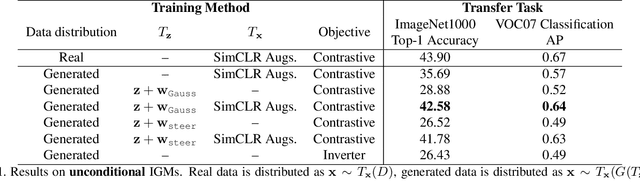
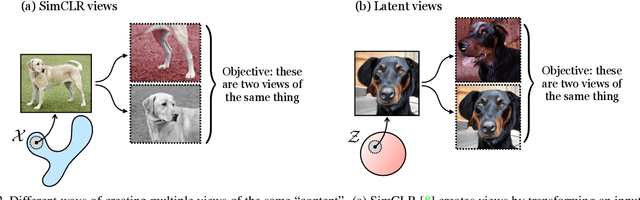
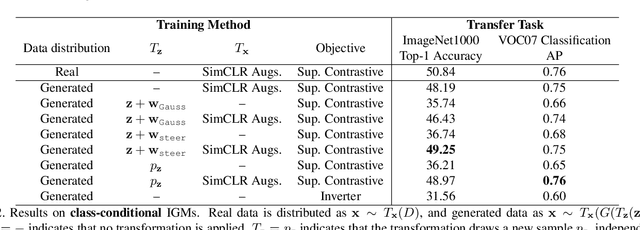
Generative models are now capable of producing highly realistic images that look nearly indistinguishable from the data on which they are trained. This raises the question: if we have good enough generative models, do we still need datasets? We investigate this question in the setting of learning general-purpose visual representations from a black-box generative model rather than directly from data. Given an off-the-shelf image generator without any access to its training data, we train representations from the samples output by this generator. We compare several representation learning methods that can be applied to this setting, using the latent space of the generator to generate multiple "views" of the same semantic content. We show that for contrastive methods, this multiview data can naturally be used to identify positive pairs (nearby in latent space) and negative pairs (far apart in latent space). We find that the resulting representations rival those learned directly from real data, but that good performance requires care in the sampling strategy applied and the training method. Generative models can be viewed as a compressed and organized copy of a dataset, and we envision a future where more and more "model zoos" proliferate while datasets become increasingly unwieldy, missing, or private. This paper suggests several techniques for dealing with visual representation learning in such a future. Code is released on our project page: https://ali-design.github.io/GenRep/