 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Relighting of Real Scenes
Jul 06, 2022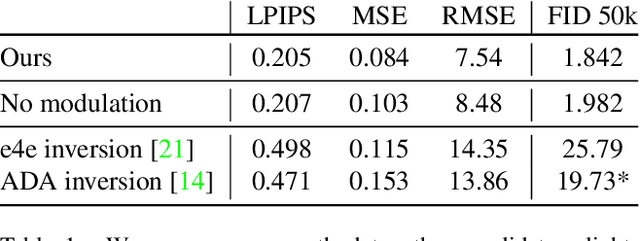

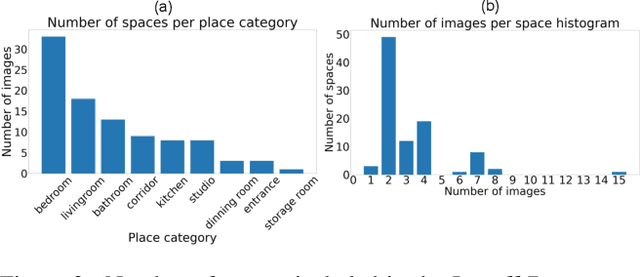
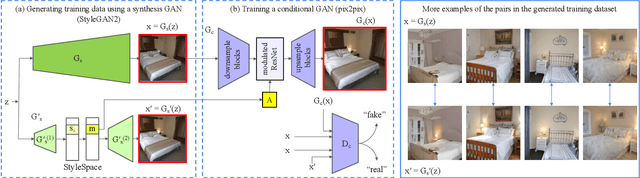
We introduce the task of local relighting, which changes a photograph of a scene by switching on and off the light sources that are visible within the image. This new task differs from the traditional image relighting problem, as it introduces the challenge of detecting light sources and inferring the pattern of light that emanates from them. We propose an approach for local relighting that trains a model without supervision of any novel image dataset by using synthetically generated image pairs from another model. Concretely, we collect paired training images from a stylespace-manipulated GAN; then we use these images to train a conditional image-to-image model. To benchmark local relighting, we introduce Lonoff, a collection of 306 precisely aligned images taken in indoor spaces with different combinations of lights switched on. We show that our method significantly outperforms baseline methods based on GAN inversion. Finally, we demonstrate extensions of our method that control different light sources separately. We invite the community to tackle this new task of local relighting.
Visual Prompting: Modifying Pixel Space to Adapt Pre-trained Models
Mar 31, 2022

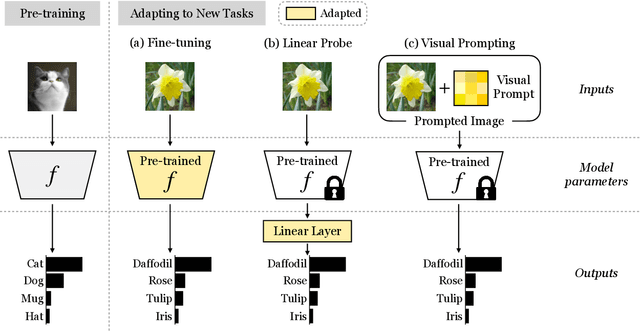
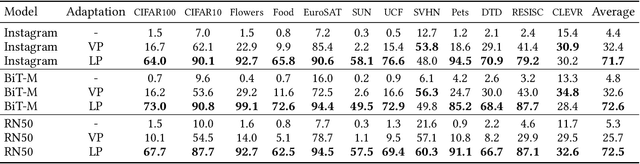
Prompting has recently become a popular paradigm for adapting language models to downstream tasks. Rather than fine-tuning model parameters or adding task-specific heads, this approach steers a model to perform a new task simply by adding a text prompt to the model's inputs. In this paper, we explore the question: can we create prompts with pixels instead? In other words, can pre-trained vision models be adapted to a new task solely by adding pixels to their inputs? We introduce visual prompting, which learns a task-specific image perturbation such that a frozen pre-trained model prompted with this perturbation performs a new task. We discover that changing only a few pixels is enough to adapt models to new tasks and datasets, and performs on par with linear probing, the current de facto approach to lightweight adaptation. The surprising effectiveness of visual prompting provides a new perspective on how to adapt pre-trained models in vision, and opens up the possibility of adapting models solely through their inputs, which, unlike model parameters or outputs, are typically under an end-user's control. Code is available at http://hjbahng.github.io/visual_prompting .
Generative Models as a Data Source for Multiview Representation Learning
Jun 09, 2021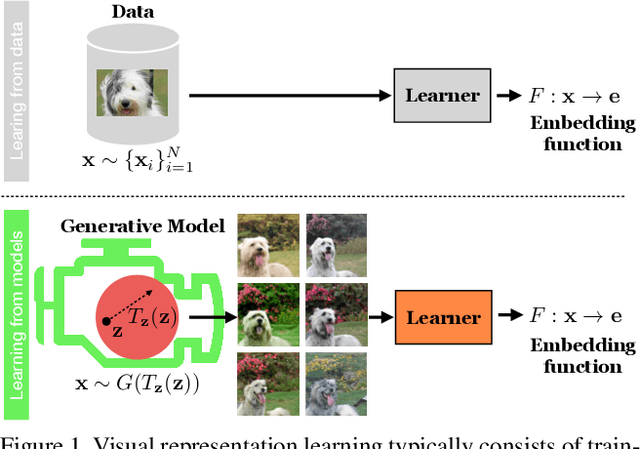
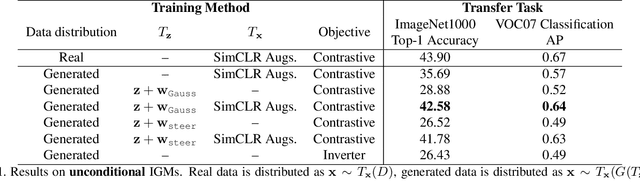
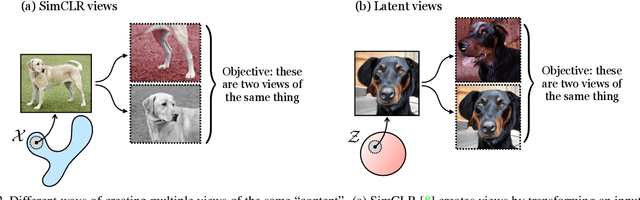
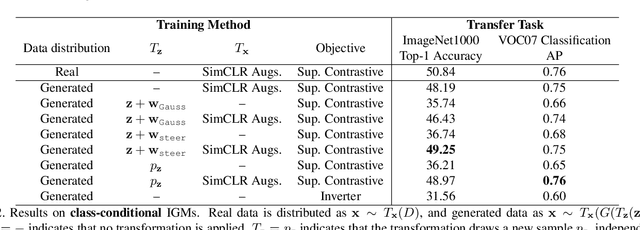
Generative models are now capable of producing highly realistic images that look nearly indistinguishable from the data on which they are trained. This raises the question: if we have good enough generative models, do we still need datasets? We investigate this question in the setting of learning general-purpose visual representations from a black-box generative model rather than directly from data. Given an off-the-shelf image generator without any access to its training data, we train representations from the samples output by this generator. We compare several representation learning methods that can be applied to this setting, using the latent space of the generator to generate multiple "views" of the same semantic content. We show that for contrastive methods, this multiview data can naturally be used to identify positive pairs (nearby in latent space) and negative pairs (far apart in latent space). We find that the resulting representations rival those learned directly from real data, but that good performance requires care in the sampling strategy applied and the training method. Generative models can be viewed as a compressed and organized copy of a dataset, and we envision a future where more and more "model zoos" proliferate while datasets become increasingly unwieldy, missing, or private. This paper suggests several techniques for dealing with visual representation learning in such a future. Code is released on our project page: https://ali-design.github.io/GenRep/
Paint by Word
Mar 24, 2021
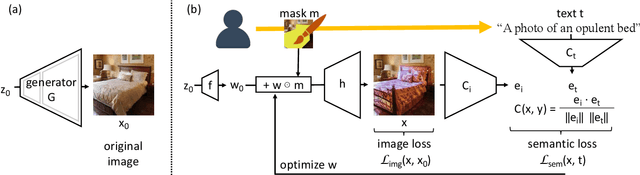

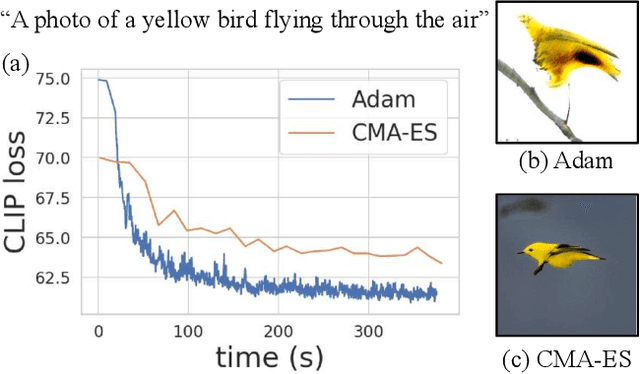
We investigate the problem of zero-shot semantic image painting. Instead of painting modifications into an image using only concrete colors or a finite set of semantic concepts, we ask how to create semantic paint based on open full-text descriptions: our goal is to be able to point to a location in a synthesized image and apply an arbitrary new concept such as "rustic" or "opulent" or "happy dog." To do this, our method combines a state-of-the art generative model of realistic images with a state-of-the-art text-image semantic similarity network. We find that, to make large changes, it is important to use non-gradient methods to explore latent space, and it is important to relax the computations of the GAN to target changes to a specific region. We conduct user studies to compare our methods to several baselines.
GAN Mask R-CNN:Instance semantic segmentation benefits from generativeadversarial networks
Oct 26, 2020
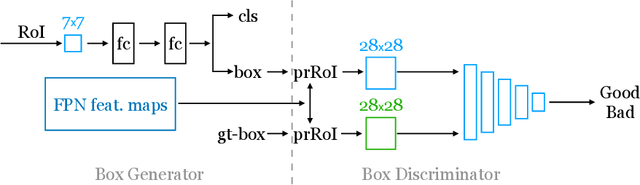

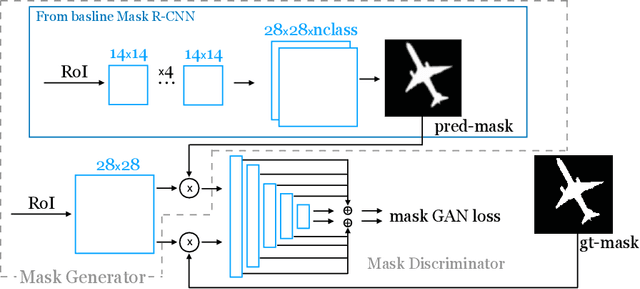
In designing instance segmentation ConvNets that reconstruct masks, segmentation is often taken as its literal definition -- assigning label to every pixel -- for defining the loss functions. That is, using losses that compute the difference between pixels in the predicted (reconstructed) mask and the ground truth mask -- a template matching mechanism. However, any such instance segmentation ConvNet is a generator, so we can lay the problem of predicting masks as a GANs game framework: We can think the ground truth mask is drawn from the true distribution, and a ConvNet like Mask R-CNN is an implicit model that infers the true distribution. Then, designing a discriminator in front of this generator will close the loop of GANs concept and more importantly obtains a loss that is trained not hand-designed. We show this design outperforms the baseline when trying on, without extra settings, several different domains: cellphone recycling, autonomous driving, large-scale object detection, and medical glands. Further, we observe in general GANs yield masks that account for better boundaries, clutter, and small details.
On the ''steerability" of generative adversarial networks
Jul 16, 2019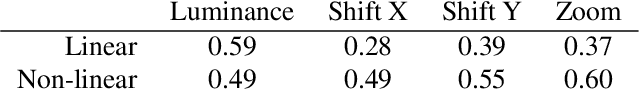
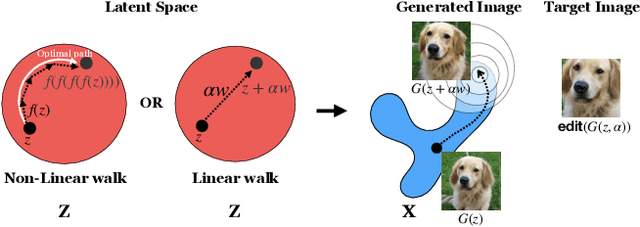

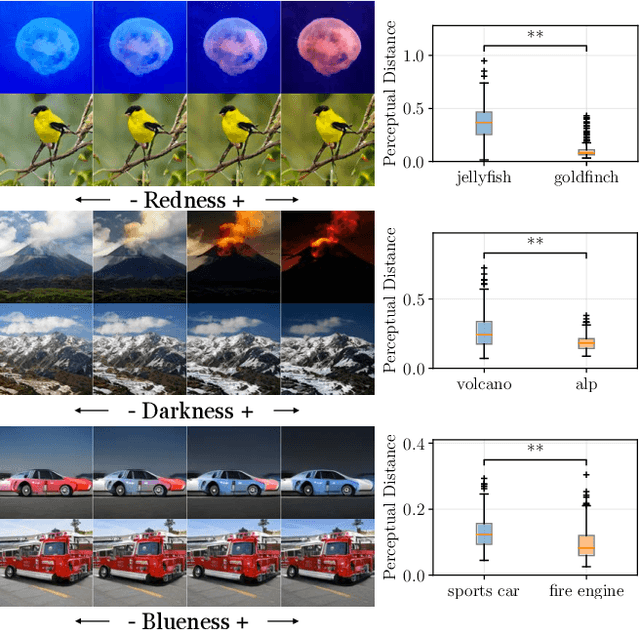
An open secret in contemporary machine learning is that many models work beautifully on standard benchmarks but fail to generalize outside the lab. This has been attributed to training on biased data, which provide poor coverage over real world events. Generative models are no exception, but recent advances in generative adversarial networks (GANs) suggest otherwise -- these models can now synthesize strikingly realistic and diverse images. Is generative modeling of photos a solved problem? We show that although current GANs can fit standard datasets very well, they still fall short of being comprehensive models of the visual manifold. In particular, we study their ability to fit simple transformations such as camera movements and color changes. We find that the models reflect the biases of the datasets on which they are trained (e.g., centered objects), but that they also exhibit some capacity for generalization: by "steering" in latent space, we can shift the distribution while still creating realistic images. We hypothesize that the degree of distributional shift is related to the breadth of the training data distribution, and conduct experiments that demonstrate this. Code is released on our project page: https://ali-design.github.io/gan_steerability/