 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompting: Modifying Pixel Space to Adapt Pre-trained Models
Paper and Code


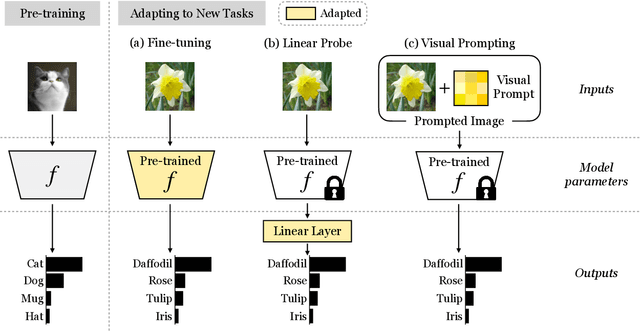
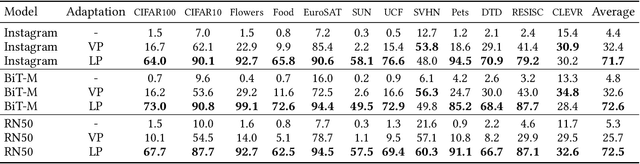
Prompting has recently become a popular paradigm for adapting language models to downstream tasks. Rather than fine-tuning model parameters or adding task-specific heads, this approach steers a model to perform a new task simply by adding a text prompt to the model's inputs. In this paper, we explore the question: can we create prompts with pixels instead? In other words, can pre-trained vision models be adapted to a new task solely by adding pixels to their inputs? We introduce visual prompting, which learns a task-specific image perturbation such that a frozen pre-trained model prompted with this perturbation performs a new task. We discover that changing only a few pixels is enough to adapt models to new tasks and datasets, and performs on par with linear probing, the current de facto approach to lightweight adaptation. The surprising effectiveness of visual prompting provides a new perspective on how to adapt pre-trained models in vision, and opens up the possibility of adapting models solely through their inputs, which, unlike model parameters or outputs, are typically under an end-user's control. Code is available at http://hjbahng.github.io/visual_prompting .