 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Optimization in the Modular Norm
May 23, 2024



To improve performance in contemporary deep learning, one is interested in scaling up the neural network in terms of both the number and the size of the layers. When ramping up the width of a single layer, graceful scaling of training has been linked to the need to normalize the weights and their updates in the "natural norm" particular to that layer. In this paper, we significantly generalize this idea by defining the modular norm, which is the natural norm on the full weight space of any neural network architecture. The modular norm is defined recursively in tandem with the network architecture itself. We show that the modular norm has several promising applications. On the practical side, the modular norm can be used to normalize the updates of any base optimizer so that the learning rate becomes transferable across width and depth. This means that the user does not need to compute optimizer-specific scale factors in order to scale training. On the theoretical side, we show that for any neural network built from "well-behaved" atomic modules, the gradient of the network is Lipschitz-continuous in the modular norm, with the Lipschitz constant admitting a simple recursive formula. This characterization opens the door to porting standard ideas in optimization theory over to deep learning. We have created a Python package called Modula that automatically normalizes weight updates in the modular norm of the architecture. The package is available via "pip install modula" with source code at https://github.com/jxbz/modula.
Visual Prompting: Modifying Pixel Space to Adapt Pre-trained Models
Mar 31, 2022

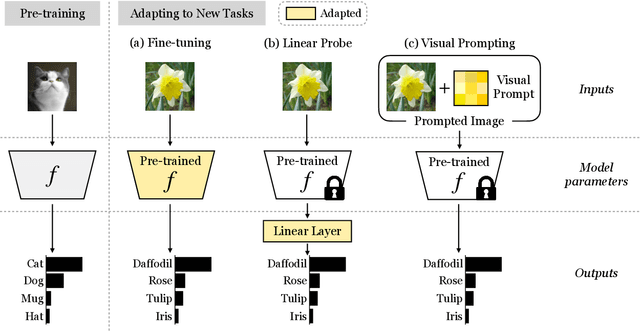
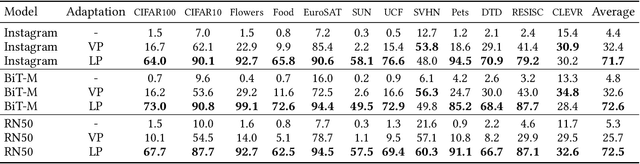
Prompting has recently become a popular paradigm for adapting language models to downstream tasks. Rather than fine-tuning model parameters or adding task-specific heads, this approach steers a model to perform a new task simply by adding a text prompt to the model's inputs. In this paper, we explore the question: can we create prompts with pixels instead? In other words, can pre-trained vision models be adapted to a new task solely by adding pixels to their inputs? We introduce visual prompting, which learns a task-specific image perturbation such that a frozen pre-trained model prompted with this perturbation performs a new task. We discover that changing only a few pixels is enough to adapt models to new tasks and datasets, and performs on par with linear probing, the current de facto approach to lightweight adaptation. The surprising effectiveness of visual prompting provides a new perspective on how to adapt pre-trained models in vision, and opens up the possibility of adapting models solely through their inputs, which, unlike model parameters or outputs, are typically under an end-user's control. Code is available at http://hjbahng.github.io/visual_prompting .
Exploring Unlabeled Faces for Novel Attribute Discovery
Dec 06, 2019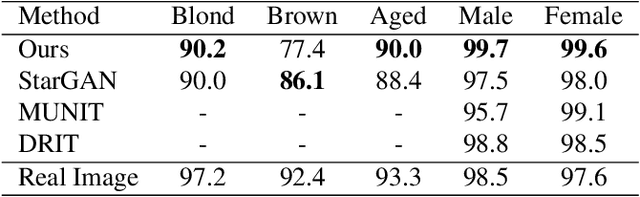

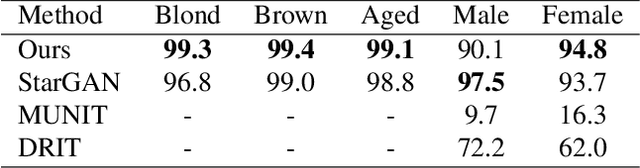

Despite remarkable success in unpaired image-to-image translation, existing systems still require a large amount of labeled images. This is a bottleneck for their real-world applications; in practice, a model trained on labeled CelebA dataset does not work well for test images from a different distribution -- greatly limiting their application to unlabeled images of a much larger quantity. In this paper, we attempt to alleviate this necessity for labeled data in the facial image translation domain. We aim to explore the degree to which you can discover novel attributes from unlabeled faces and perform high-quality translation. To this end, we use prior knowledge about the visual world as guidance to discover novel attributes and transfer them via a novel normalization method. Experiments show that our method trained on unlabeled data produces high-quality translations, preserves identity, and be perceptually realistic as good as, or better than, state-of-the-art methods trained on labeled data.
STGRAT: A Spatio-Temporal Graph Attention Network for Traffic Forecasting
Nov 29, 2019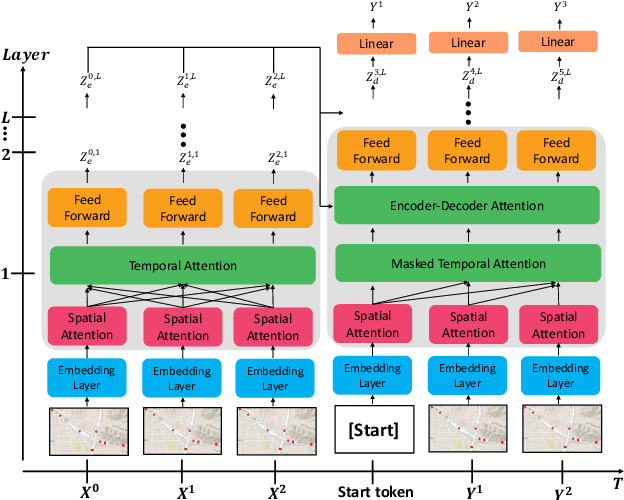
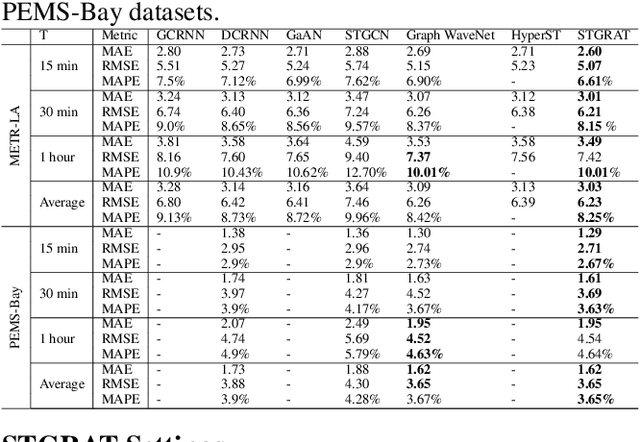
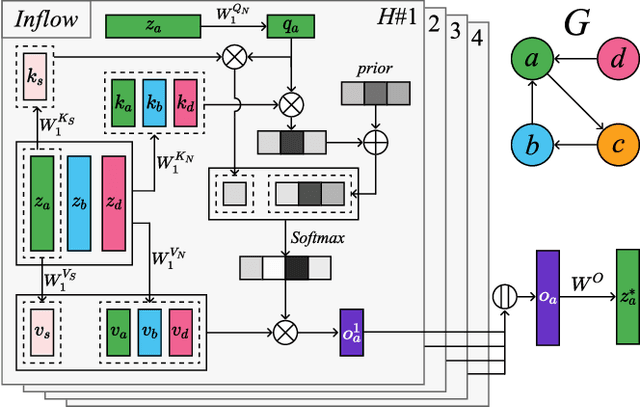
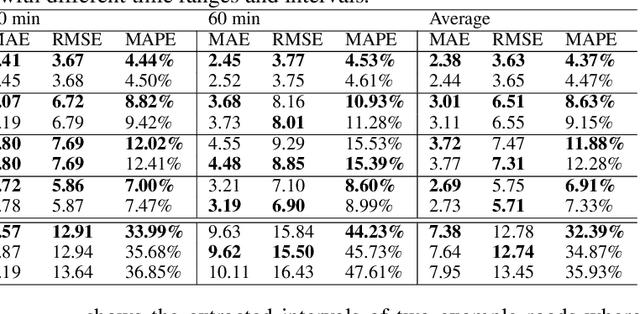
Predicting the road traffic speed is a challenging task due to different types of roads, abrupt speed changes, and spatial dependencies between roads, which requires the modeling of dynamically changing spatial dependencies among roads and temporal patterns over long input sequences. This paper proposes a novel Spatio-Temporal Graph Attention (STGRAT) that effectively captures the spatio-temporal dynamics in road networks. The features of our approach mainly include spatial attention, temporal attention, and spatial sentinel vectors. The spatial attention takes the graph structure information (e.g., distance between roads) and dynamically adjusts spatial correlation based on road states. The temporal attention is responsible for capturing traffic speed changes, while the sentinel vectors allow the model to retrieve new features from spatially correlated nodes or preserve existing features. The experimental results show that STGRAT outperforms existing models, especially in difficult conditions where traffic speeds rapidly change (e.g., rush hours). We additionally provide a qualitative study to analyze when and where STGRAT mainly attended to make accurate predictions during a rush-hour time.
Learning De-biased Representations with Biased Representations
Oct 07, 2019
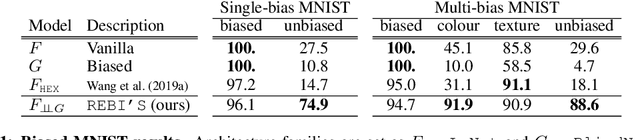


Many machine learning algorithms are trained and evaluated by splitting data from a single source into training and test sets. While such focus on in-distribution learning scenarios has led interesting advances, it has not been able to tell if models are relying on dataset biases as shortcuts for successful prediction (e.g., using snow cues for recognising snowmobiles). Such biased models fail to generalise when the bias shifts to a different class. The cross-bias generalisation problem has been addressed by de-biasing training data through augmentation or re-sampling, which are often prohibitive due to the data collection cost (e.g., collecting images of a snowmobile on a desert) and the difficulty of quantifying or expressing biases in the first place. In this work, we propose a novel framework to train a de-biased representation by encouraging it to be different from a set of representations that are biased by design. This tactic is feasible in many scenarios where it is much easier to define a set of biased representations than to define and quantify bias. Our experiments and analyses show that our method discourages models from taking bias shortcuts, resulting in improved performances on de-biased test data.
Coloring With Limited Data: Few-Shot Colorization via Memory-Augmented Networks
Jun 09, 2019
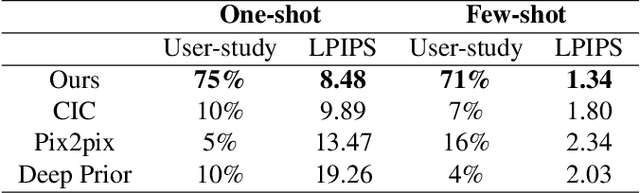

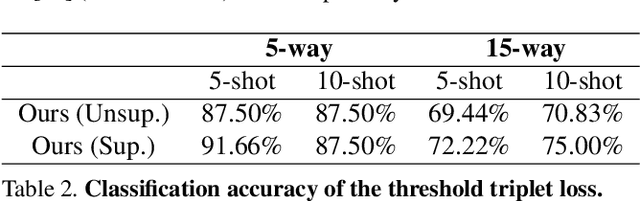
Despite recent advancements in deep learning-based automatic colorization, they are still limited when it comes to few-shot learning. Existing models require a significant amount of training data. To tackle this issue, we present a novel memory-augmented colorization model MemoPainter that can produce high-quality colorization with limited data. In particular, our model is able to capture rare instances and successfully colorize them. We also propose a novel threshold triplet loss that enables unsupervised training of memory networks without the need of class labels. Experiments show that our model has superior quality in both few-shot and one-shot colorization tasks.
Coloring with Words: Guiding Image Colorization Through Text-based Palette Generation
Aug 07, 2018
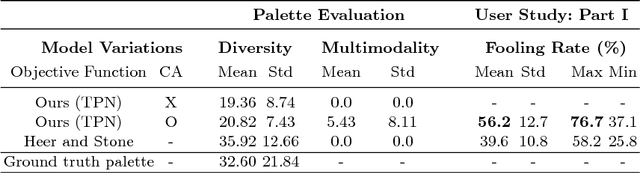


This paper proposes a novel approach to generate multiple color palettes that reflect the semantics of input text and then colorize a given grayscale image according to the generated color palette. In contrast to existing approaches, our model can understand rich text, whether it is a single word, a phrase, or a sentence, and generate multiple possible palettes from it. For this task, we introduce our manually curated dataset called Palette-and-Text (PAT). Our proposed model called Text2Colors consists of two conditional generative adversarial networks: the text-to-palette generation networks and the palette-based colorization networks. The former captures the semantics of the text input and produce relevant color palettes. The latter colorizes a grayscale image using the generated color palette. Our evaluation results show that people preferred our generated palettes over ground truth palettes and that our model can effectively reflect the given palette when colorizing an image.
* 25 pages, 22 figures
MEGAN: Mixture of Experts of Generative Adversarial Networks for Multimodal Image Generation
May 08, 2018

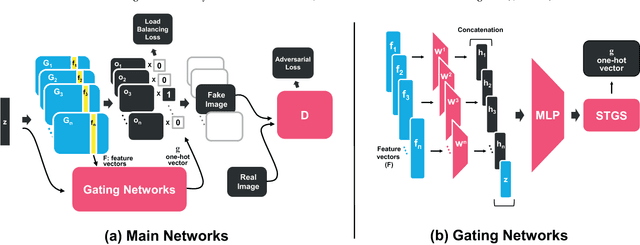
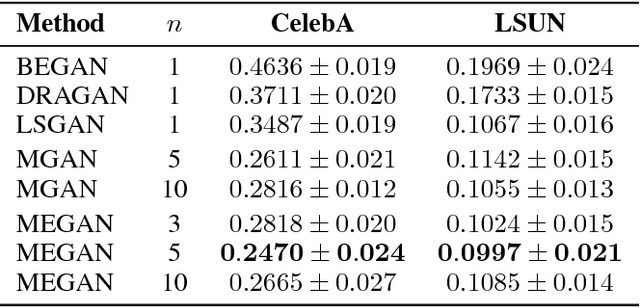
Recently, generative adversarial networks (GANs) have shown promising performance in generating realistic images. However, they often struggle in learning complex underlying modalities in a given dataset, resulting in poor-quality generated images. To mitigate this problem, we present a novel approach called mixture of experts GAN (MEGAN), an ensemble approach of multiple generator networks. Each generator network in MEGAN specializes in generating images with a particular subset of modalities, e.g., an image class. Instead of incorporating a separate step of handcrafted clustering of multiple modalities, our proposed model is trained through an end-to-end learning of multiple generators via gating networks, which is responsible for choosing the appropriate generator network for a given condition. We adopt the categorical reparameterization trick for a categorical decision to be made in selecting a generator while maintaining the flow of the gradients. We demonstrate that individual generators learn different and salient subparts of the data and achieve a multiscale structural similarity (MS-SSIM) score of 0.2470 for CelebA and a competitive unsupervised inception score of 8.33 in CIFAR-10.