 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamStyler: Paint by Style Inversion with Text-to-Image Diffusion Models
Sep 13, 2023Recent progresses in large-scale text-to-image models have yielded remarkable accomplishments, finding various applications in art domain. However, expressing unique characteristics of an artwork (e.g. brushwork, colortone, or composition) with text prompts alone may encounter limitations due to the inherent constraints of verbal description. To this end, we introduce DreamStyler, a novel framework designed for artistic image synthesis, proficient in both text-to-image synthesis and style transfer. DreamStyler optimizes a multi-stage textual embedding with a context-aware text prompt, resulting in prominent image quality. In addition, with content and style guidance, DreamStyler exhibits flexibility to accommodate a range of style references. Experimental results demonstrate its superior performance across multiple scenarios, suggesting its promising potential in artistic product creation.
TILDE-Q: A Transformation Invariant Loss Function for Time-Series Forecasting
Oct 26, 2022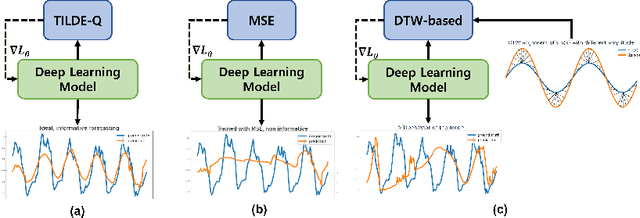

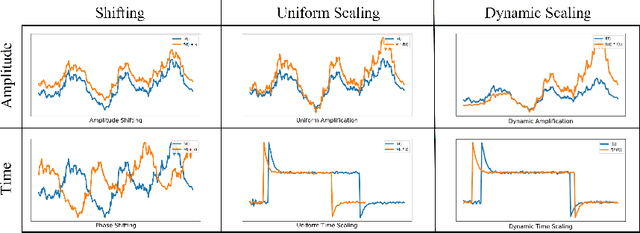
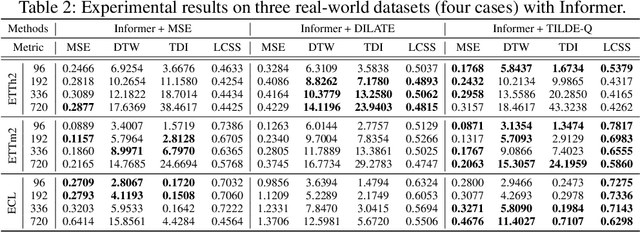
Time-series forecasting has caught increasing attention in the AI research field due to its importance in solving real-world problems across different domains, such as energy, weather, traffic, and economy. As shown in various types of data, it has been a must-see issue to deal with drastic changes, temporal patterns, and shapes in sequential data that previous models are weak in prediction. This is because most cases in time-series forecasting aim to minimize $L_p$ norm distances as loss functions, such as mean absolute error (MAE) or mean square error (MSE). These loss functions are vulnerable to not only considering temporal dynamics modeling but also capturing the shape of signals. In addition, these functions often make models misbehave and return uncorrelated results to the original time-series. To become an effective loss function, it has to be invariant to the set of distortions between two time-series data instead of just comparing exact values. In this paper, we propose a novel loss function, called TILDE-Q (Transformation Invariant Loss function with Distance EQuilibrium), that not only considers the distortions in amplitude and phase but also allows models to capture the shape of time-series sequences. In addition, TILDE-Q supports modeling periodic and non-periodic temporal dynamics at the same time. We evaluate the effectiveness of TILDE-Q by conducting extensive experiments with respect to periodic and non-periodic conditions of data, from naive models to state-of-the-art models. The experiment results indicate that the models trained with TILDE-Q outperform those trained with other training metrics (e.g., MSE, dynamic time warping (DTW), temporal distortion index (TDI), and longest common subsequence (LCSS)).
Variability Matters : Evaluating inter-rater variability in histopathology for robust cell detection
Oct 11, 2022

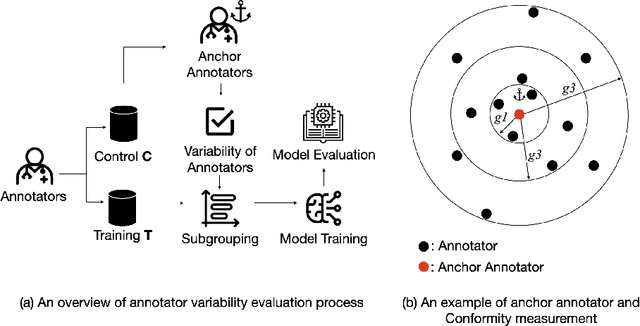
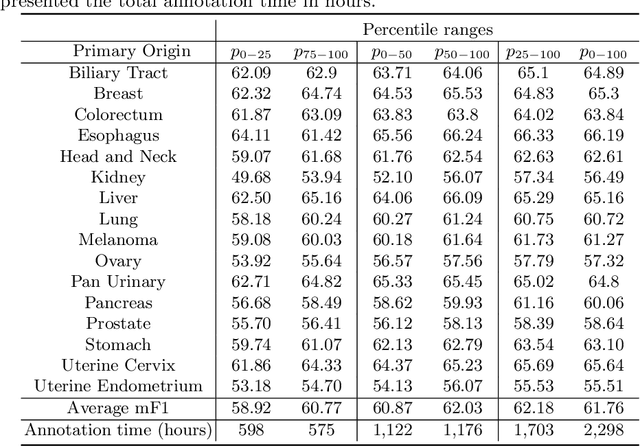
Large annotated datasets have been a key component in the success of deep learning. However, annotating medical images is challenging as it requires expertise and a large budget. In particular, annotating different types of cells in histopathology suffer from high inter- and intra-rater variability due to the ambiguity of the task. Under this setting, the relation between annotators' variability and model performance has received little attention. We present a large-scale study on the variability of cell annotations among 120 board-certified pathologists and how it affects the performance of a deep learning model. We propose a method to measure such variability, and by excluding those annotators with low variability, we verify the trade-off between the amount of data and its quality. We found that naively increasing the data size at the expense of inter-rater variability does not necessarily lead to better-performing models in cell detection. Instead, decreasing the inter-rater variability with the expense of decreasing dataset size increased the model performance. Furthermore, models trained from data annotated with lower inter-labeler variability outperform those from higher inter-labeler variability. These findings suggest that the evaluation of the annotators may help tackle the fundamental budget issues in the histopathology domain
Interactive Multi-Class Tiny-Object Detection
Mar 29, 2022

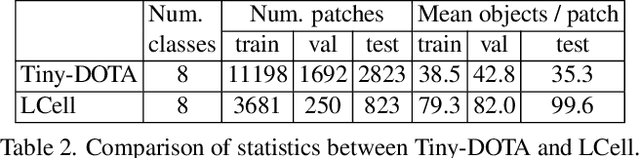
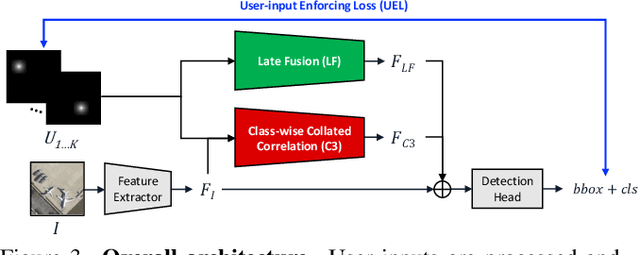
Annotating tens or hundreds of tiny objects in a given image is laborious yet crucial for a multitude of Computer Vision tasks. Such imagery typically contains objects from various categories, yet the multi-class interactive annotation setting for the detection task has thus far been unexplored. To address these needs, we propose a novel interactive annotation method for multiple instances of tiny objects from multiple classes, based on a few point-based user inputs. Our approach, C3Det, relates the full image context with annotator inputs in a local and global manner via late-fusion and feature-correlation, respectively. We perform experiments on the Tiny-DOTA and LCell datasets using both two-stage and one-stage object detection architectures to verify the efficacy of our approach. Our approach outperforms existing approaches in interactive annotation, achieving higher mAP with fewer clicks. Furthermore, we validate the annotation efficiency of our approach in a user study where it is shown to be 2.85x faster and yield only 0.36x task load (NASA-TLX, lower is better) compared to manual annotation. The code is available at https://github.com/ChungYi347/Interactive-Multi-Class-Tiny-Object-Detection.
STGRAT: A Spatio-Temporal Graph Attention Network for Traffic Forecasting
Nov 29, 2019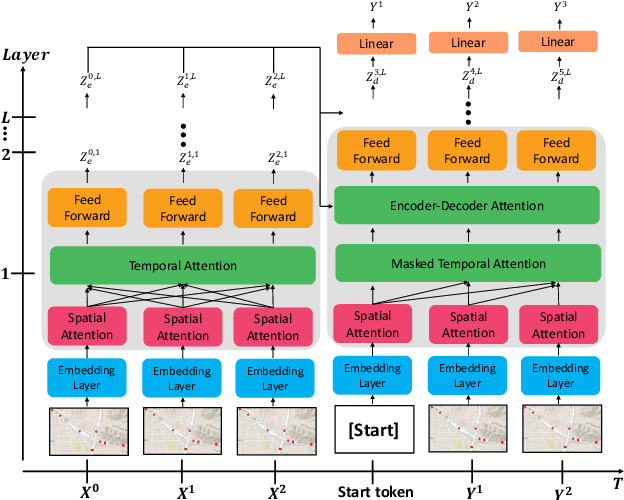
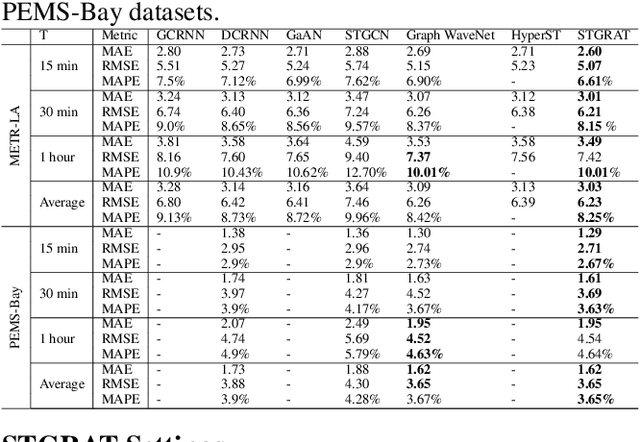
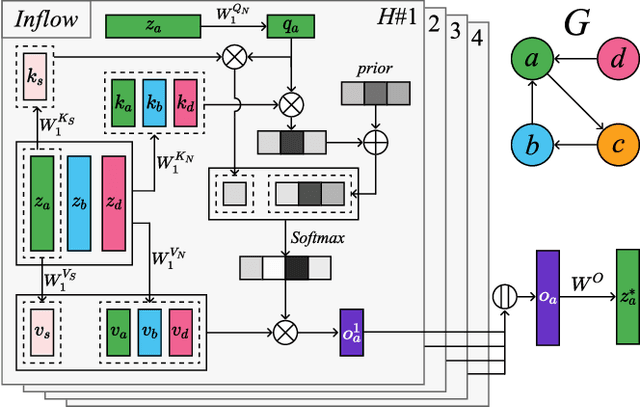
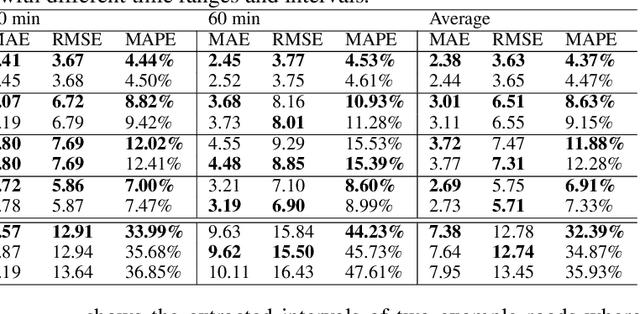
Predicting the road traffic speed is a challenging task due to different types of roads, abrupt speed changes, and spatial dependencies between roads, which requires the modeling of dynamically changing spatial dependencies among roads and temporal patterns over long input sequences. This paper proposes a novel Spatio-Temporal Graph Attention (STGRAT) that effectively captures the spatio-temporal dynamics in road networks. The features of our approach mainly include spatial attention, temporal attention, and spatial sentinel vectors. The spatial attention takes the graph structure information (e.g., distance between roads) and dynamically adjusts spatial correlation based on road states. The temporal attention is responsible for capturing traffic speed changes, while the sentinel vectors allow the model to retrieve new features from spatially correlated nodes or preserve existing features. The experimental results show that STGRAT outperforms existing models, especially in difficult conditions where traffic speeds rapidly change (e.g., rush hours). We additionally provide a qualitative study to analyze when and where STGRAT mainly attended to make accurate predictions during a rush-hour time.