 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConCSE: Unified Contrastive Learning and Augmentation for Code-Switched Embeddings
Aug 28, 2024This paper examines the Code-Switching (CS) phenomenon where two languages intertwine within a single utterance. There exists a noticeable need for research on the CS between English and Korean. We highlight that the current Equivalence Constraint (EC) theory for CS in other languages may only partially capture English-Korean CS complexities due to the intrinsic grammatical differences between the languages. We introduce a novel Koglish dataset tailored for English-Korean CS scenarios to mitigate such challenges. First, we constructed the Koglish-GLUE dataset to demonstrate the importance and need for CS datasets in various tasks. We found the differential outcomes of various foundation multilingual language models when trained on a monolingual versus a CS dataset. Motivated by this, we hypothesized that SimCSE, which has shown strengths in monolingual sentence embedding, would have limitations in CS scenarios. We construct a novel Koglish-NLI (Natural Language Inference) dataset using a CS augmentation-based approach to verify this. From this CS-augmented dataset Koglish-NLI, we propose a unified contrastive learning and augmentation method for code-switched embeddings, ConCSE, highlighting the semantics of CS sentences. Experimental results validate the proposed ConCSE with an average performance enhancement of 1.77\% on the Koglish-STS(Semantic Textual Similarity) tasks.
Variability Matters : Evaluating inter-rater variability in histopathology for robust cell detection
Oct 11, 2022

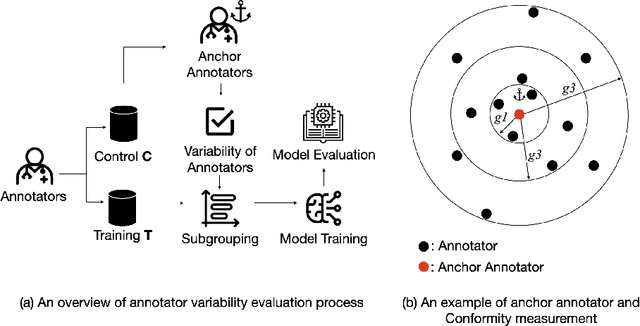
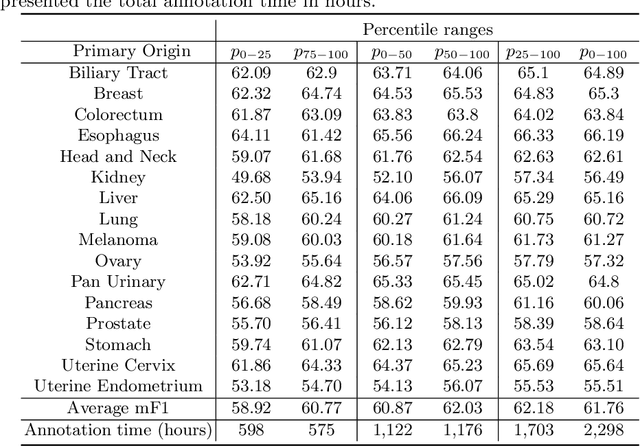
Large annotated datasets have been a key component in the success of deep learning. However, annotating medical images is challenging as it requires expertise and a large budget. In particular, annotating different types of cells in histopathology suffer from high inter- and intra-rater variability due to the ambiguity of the task. Under this setting, the relation between annotators' variability and model performance has received little attention. We present a large-scale study on the variability of cell annotations among 120 board-certified pathologists and how it affects the performance of a deep learning model. We propose a method to measure such variability, and by excluding those annotators with low variability, we verify the trade-off between the amount of data and its quality. We found that naively increasing the data size at the expense of inter-rater variability does not necessarily lead to better-performing models in cell detection. Instead, decreasing the inter-rater variability with the expense of decreasing dataset size increased the model performance. Furthermore, models trained from data annotated with lower inter-labeler variability outperform those from higher inter-labeler variability. These findings suggest that the evaluation of the annotators may help tackle the fundamental budget issues in the histopathology domain
VLANet: Video-Language Alignment Network for Weakly-Supervised Video Moment Retrieval
Aug 24, 2020
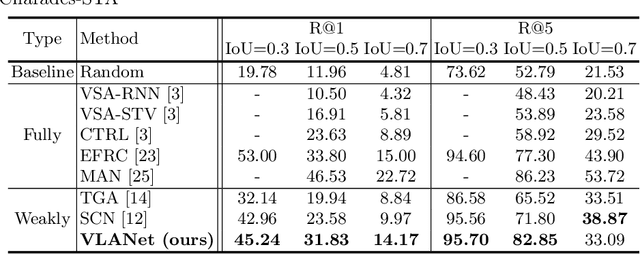
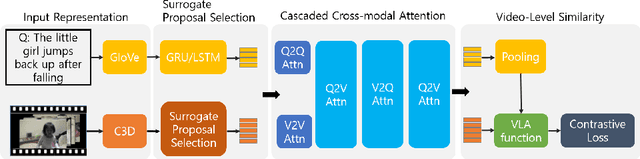
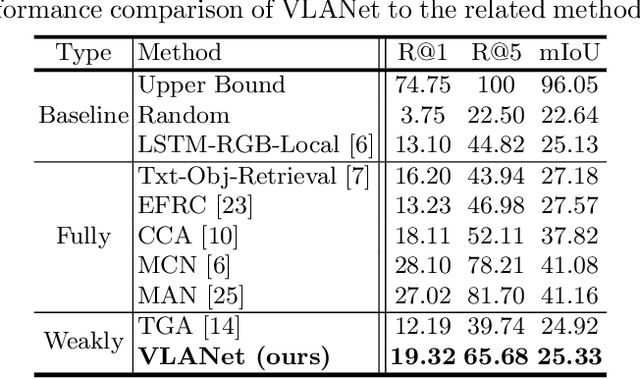
Video Moment Retrieval (VMR) is a task to localize the temporal moment in untrimmed video specified by natural language query. For VMR, several methods that require full supervision for training have been proposed. Unfortunately, acquiring a large number of training videos with labeled temporal boundaries for each query is a labor-intensive process. This paper explores methods for performing VMR in a weakly-supervised manner (wVMR): training is performed without temporal moment labels but only with the text query that describes a segment of the video. Existing methods on wVMR generate multi-scale proposals and apply query-guided attention mechanisms to highlight the most relevant proposal. To leverage the weak supervision, contrastive learning is used which predicts higher scores for the correct video-query pairs than for the incorrect pairs. It has been observed that a large number of candidate proposals, coarse query representation, and one-way attention mechanism lead to blurry attention maps which limit the localization performance. To handle this issue, Video-Language Alignment Network (VLANet) is proposed that learns sharper attention by pruning out spurious candidate proposals and applying a multi-directional attention mechanism with fine-grained query representation. The Surrogate Proposal Selection module selects a proposal based on the proximity to the query in the joint embedding space, and thus substantially reduces candidate proposals which leads to lower computation load and sharper attention. Next, the Cascaded Cross-modal Attention module considers dense feature interactions and multi-directional attention flow to learn the multi-modal alignment. VLANet is trained end-to-end using contrastive loss which enforces semantically similar videos and queries to gather. The experiments show that the method achieves state-of-the-art performance on Charades-STA and DiDeMo datasets.
Modality Shifting Attention Network for Multi-modal Video Question Answering
Jul 04, 2020
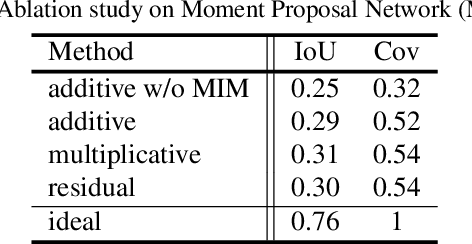
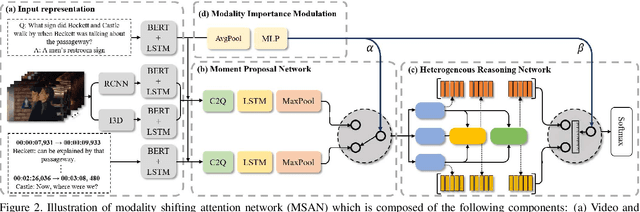
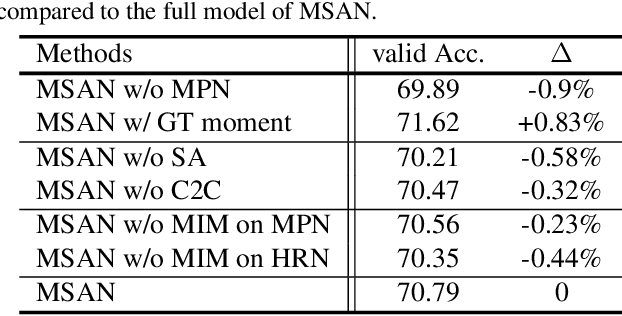
This paper considers a network referred to as Modality Shifting Attention Network (MSAN) for Multimodal Video Question Answering (MVQA) task. MSAN decomposes the task into two sub-tasks: (1) localization of temporal moment relevant to the question, and (2) accurate prediction of the answer based on the localized moment. The modality required for temporal localization may be different from that for answer prediction, and this ability to shift modality is essential for performing the task. To this end, MSAN is based on (1) the moment proposal network (MPN) that attempts to locate the most appropriate temporal moment from each of the modalities, and also on (2) the heterogeneous reasoning network (HRN) that predicts the answer using an attention mechanism on both modalities. MSAN is able to place importance weight on the two modalities for each sub-task using a component referred to as Modality Importance Modulation (MIM). Experimental results show that MSAN outperforms previous state-of-the-art by achieving 71.13\% test accuracy on TVQA benchmark dataset. Extensive ablation studies and qualitative analysis are conducted to validate various components of the network.
Gaining Extra Supervision via Multi-task learning for Multi-Modal Video Question Answering
May 28, 2019
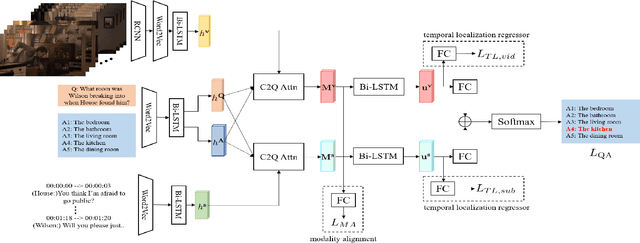
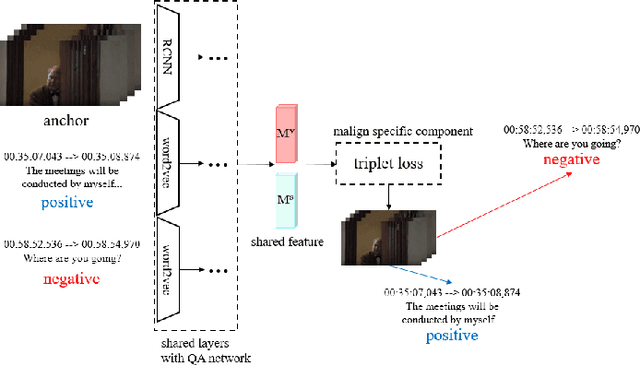
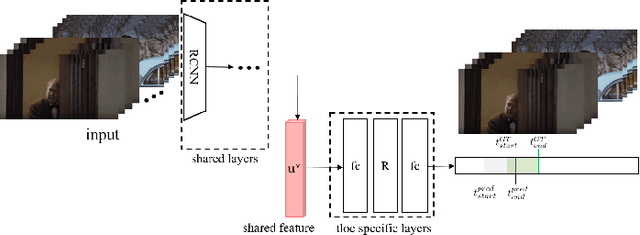
This paper proposes a method to gain extra supervision via multi-task learning for multi-modal video question answering. Multi-modal video question answering is an important task that aims at the joint understanding of vision and language. However, establishing large scale dataset for multi-modal video question answering is expensive and the existing benchmarks are relatively small to provide sufficient supervision. To overcome this challenge, this paper proposes a multi-task learning method which is composed of three main components: (1) multi-modal video question answering network that answers the question based on the both video and subtitle feature, (2) temporal retrieval network that predicts the time in the video clip where the question was generated from and (3) modality alignment network that solves metric learning problem to find correct association of video and subtitle modalities. By simultaneously solving related auxiliary tasks with hierarchically shared intermediate layers, the extra synergistic supervisions are provided. Motivated by curriculum learning, multi task ratio scheduling is proposed to learn easier task earlier to set inductive bias at the beginning of the training. The experiments on publicly available dataset TVQA shows state-of-the-art results, and ablation studies are conducted to prove the statistical validity.
Progressive Attention Memory Network for Movie Story Question Answering
Apr 18, 2019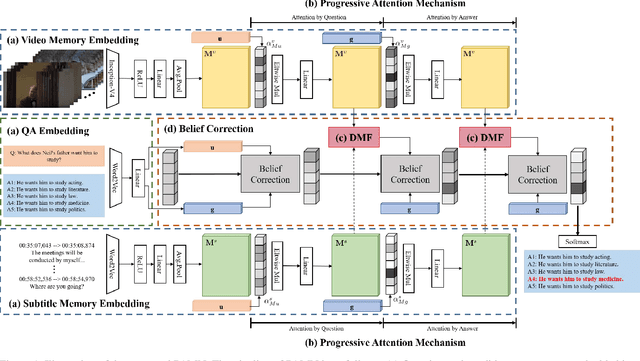

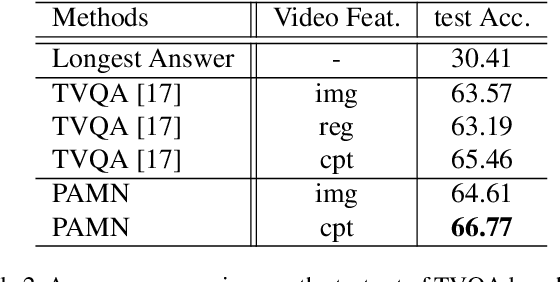
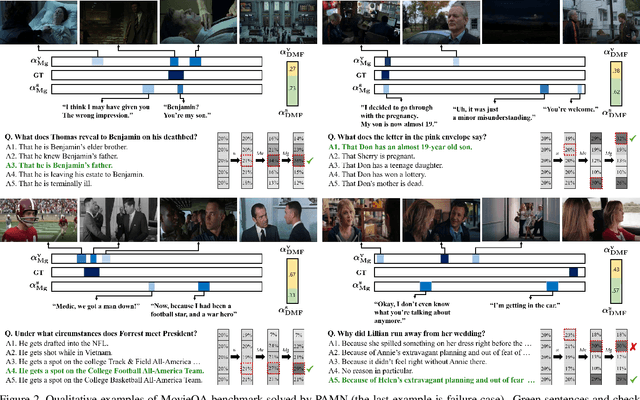
This paper proposes the progressive attention memory network (PAMN) for movie story question answering (QA). Movie story QA is challenging compared to VQA in two aspects: (1) pinpointing the temporal parts relevant to answer the question is difficult as the movies are typically longer than an hour, (2) it has both video and subtitle where different questions require different modality to infer the answer. To overcome these challenges, PAMN involves three main features: (1) progressive attention mechanism that utilizes cues from both question and answer to progressively prune out irrelevant temporal parts in memory, (2) dynamic modality fusion that adaptively determines the contribution of each modality for answering the current question, and (3) belief correction answering scheme that successively corrects the prediction score on each candidate answer. Experiments on publicly available benchmark datasets, MovieQA and TVQA, demonstrate that each feature contributes to our movie story QA architecture, PAMN, and improves performance to achieve the state-of-the-art result. Qualitative analysis by visualizing the inference mechanism of PAMN is also provided.